【GCP】BigQueryのパーティション機能とクラスター機能
2023.7.5

Topics
はじめに
こんにちは!マイグレーションチーム所属のDJ.mashiです。
今回はBigQueryのパーティション機能とクラスター機能のご紹介、及び簡単な検証結果のご紹介です。
本記事では、主にデータベースやデータウェアハウスでの簡単なスキーマ、テーブル作成が可能な方をターゲットとしております。
パーティション機能について
パーティション分割テーブルはパーティションと呼ばれるセグメントに分割されるため、データの管理や照会が簡単になります。
大きなテーブルを小さなパーティションに分割することで、クエリのパフォーマンスを高めることや、クエリによって読み取られるバイト数を減らしてコストを抑えることができます。
テーブルのパーティショニングに使用されるパーティション列を指定して、テーブルを分割します。
主に日付属性のカラムや数値属性のカラムを元に、テーブルを内部的に小分けとする仕組みです。
メリットは下記が挙げられます。
- 格納データ量が肥大化した際、パーティションキーに対するWHERE句選択時のパフォーマンス低下を軽減
- 読み取り範囲が小分けテーブルの一部に絞られることによるクエリーコストの低下
制限事項も存在します。詳しくは下記をご参照ください。
クラスター機能について
BigQuery のクラスタ化テーブルは、クラスタ化列を使用したユーザー定義の列並べ替え順序があるテーブルです。
クラスタ化テーブルを使用すると、クエリのパフォーマンスが向上し、クエリ費用を削減できます。
パーティション機能が内部的にテーブルを小分けにするのに対し、此方はテーブルの中で指定キーを元にソートをかけた状態でテーブル内に特定キーデータの集合を作成・保存し、クエリー実行を効率化します。
こちらも同様に制限事項が存在します。詳しくは下記をご参照ください。
また、通常のテーブル、パーティション機能を用いたテーブル、クラスター機能を用いたテーブルをよくある勤怠管理上の出退勤打刻を例として簡単な図で表現しました。下図をご参照ください。
わかりやすさを重視した例をご用意しています。図や説明には、実際の挙動とは少々異なる部分を含みます。
- 通常のテーブル
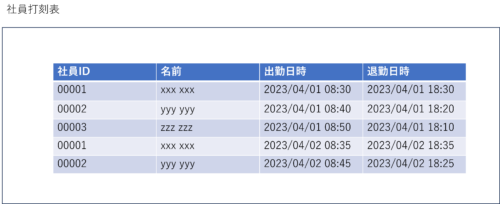
-
社員IDを基にパーティションを実施した例
見た目上1つのテーブルですが、内部的には3つに小分けし保管されます。
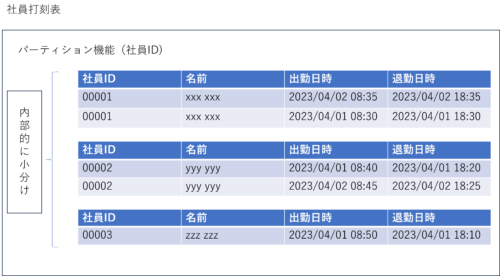
-
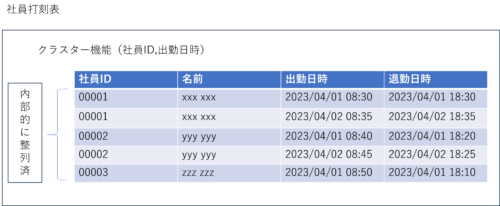
社員ID、出勤日時を基にパーティションを実施した例
予め整列の上で保管されています。
検証について
検証用データ
検証用データはBigQueryの一般公開データセットを利用します。
今回は、下記2種類4つの気象情報に関連したテーブルを利用します。
気象データ
- bigquery-public-data.ghcn_d.ghcnd_2023
- bigquery-public-data.ghcn_d.ghcnd_2022
- bigquery-public-data.ghcn_d.ghcnd_2021
観測拠点データ
- bigquery-public-data.ghcn_d.ghcnd_stations
検証用テーブル
また、上述2種類のデータを結合しクエリー実行用テーブルを4つ作成します。
これらのテーブルは、格納されているデータは全て同じデータを利用し、各テーブルごとに下記定義にて作成します。
- パーティションもクラスターも利用しないテーブル
- パーティションを利用したテーブル
- クラスターを利用したテーブル
- パーティションとクラスターを併用したテーブル
各テーブルの属性は共通です。下記に定義を記載します。
| 属性 | 属性について | 備考 |
| id | 観測拠点のID | |
| wmoid | 国際地点番号 | 本検証にてキーとして利用します。 本属性を基に、どの観測拠点であるか判断ができます。 |
| name | 観測拠点の名称 | TOKYOやYOKOHAMAが存在します。 |
| date | 気象データの日付 | 本検証にてキーとして利用します |
| time | 時間 hhmm | 日本のデータの場合余り中身が入っていないようです |
| PRCP | 降水量 | |
| SNOW | 降雪量 | |
| SNWD | 積雪の深さ | |
| TMAX | 最高気温 | |
| TMIN | 最低気温 |
データの詳細はこちらをご参照ください。
Readme.txt
検証内容
以下の内容を検証致します。
- パーティションとクラスターを利用しないテーブルに対するクエリーコストを検証
- パーティションの有無によるクエリーコストの検証
- クラスターとパーティションのクエリーコストの検証
- パーティションかつクラスター時のクエリーコストの検証
検証準備1.検証用データの取得
まずは気象データの内容を、自身のデータセットのテーブルへ作成しコピーします。
この際、2023年分、及び2022年、2021年分を当該作成テーブルへ挿入します。
CREATE TABLE `mydataset.COPY_WEATHER` AS( SELECT * FROM `bigquery-public-data.ghcn_d.ghcnd_2023` ); INSERT INTO mydataset.COPY_WEATHER SELECT * FROM `bigquery-public-data.ghcn_d.ghcnd_2022`; INSERT INTO mydataset.COPY_WEATHER SELECT * FROM `bigquery-public-data.ghcn_d.ghcnd_2021`;
観測拠点のデータを自身のデータセットのテーブルへ作成しコピーします。
CREATE TABLE `mydataset.COPY_STATION` AS ( SELECT * FROM `bigquery-public-data.ghcn_d.ghcnd_stations` );
気象データと観測拠点データの結合結果を格納するテーブルを作成し、これらの結合結果を本テーブルへ挿入します。
CREATE TABLE `mydataset.WEATHER_STATION` ( id STRING, wmoid INT64, name STRING, date DATE, time STRING, PRCP FLOAT64, SNOW FLOAT64, SNWD FLOAT64, TMAX FLOAT64, TMIN FLOAT64, ); INSERT INTO `mydataset.WEATHER_STATION` WITH CWS AS ( SELECT CS.id, CS.wmoid, CS.name, CW.date, CW.time, SUM(CASE WHEN (CW.element = 'PRCP') THEN CW.value / 10 ELSE NULL END) AS PRCP, SUM(CASE WHEN (CW.element = 'SNOW') THEN CW.value ELSE NULL END) AS SNOW, SUM(CASE WHEN (CW.element = 'SNWD') THEN CW.value ELSE NULL END) AS SNWD, SUM(CASE WHEN (CW.element = 'TMAX') THEN CW.value / 10 ELSE NULL END) AS TMAX, SUM(CASE WHEN (CW.element = 'TMIN') THEN CW.value / 10 ELSE NULL END) AS TMIN FROM `mydataset.COPY_WEATHER` AS CW JOIN `mydataset.COPY_STATION` AS CS USING (id) GROUP BY CS.id,CS.wmoid,CS.name,CW.date,CW.time ) SELECT * FROM CWS;
検証準備2.パーティション機能を用いたテーブルの作成
ここでは新しく作成するテーブルの末尾に、PARTITION BY句を用いてパーティションの実装をしデータを挿入します。
CREATE TABLE `mydataset.WS_PARTITION` ( id STRING, wmoid INT64, name STRING, date DATE, time STRING, PRCP FLOAT64, SNOW FLOAT64, SNWD FLOAT64, TMAX FLOAT64, TMIN FLOAT64, ) PARTITION BY ( RANGE_BUCKET(wmoid,GENERATE_ARRAY(0,100000,25)) ); INSERT INTO `mydataset.WS_PARTITION` SELECT * FROM `mydataset.WEATHER_STATION`;
検証準備3.クラスター機能を用いたテーブルの作成
ここでは新しく作成テーブルの末尾に、CLUSTER BY句を用いてクラスターの実装をしデータを挿入します。
CREATE TABLE `mydataset.WS_CLUSTER` ( id STRING, wmoid INT64, name STRING, date DATE, time STRING, PRCP FLOAT64, SNOW FLOAT64, SNWD FLOAT64, TMAX FLOAT64, TMIN FLOAT64, ) CLUSTER BY wmoid,date; INSERT INTO `mydataset.WS_CLUSTER` SELECT * FROM `mydataset.WEATHER_STATION`;
検証準備4.パーティションとクラスターを併用したテーブルの作成
ここでは新しく作成するテーブルの末尾に、PARITION BY句、及びCLUSTER BY句を用います。その後データを挿入します。
DROP TABLE IF EXISTS `mydataset.WS_P_C`; CREATE TABLE `mydataset.WS_P_C` ( id STRING, wmoid INT64, name STRING, date DATE, time STRING, PRCP FLOAT64, SNOW FLOAT64, SNWD FLOAT64, TMAX FLOAT64, TMIN FLOAT64, ) PARTITION BY ( RANGE_BUCKET(wmoid,GENERATE_ARRAY(0,100000,25)) ) CLUSTER BY date; INSERT INTO `mydataset.WS_P_C` SELECT * FROM `mydataset.WEATHER_STATION`;
検証 及び検証結果
用意した4つの下記テーブルに対し、検証クエリーを発行します。
検証クエリーは 下記です。
SELECT * FROM mydataset.TABLENAME (表に記載のWHERE句)
| テーブル名/オプション/実行結果 | PARTITION | CLUSTER | WHERE wmoid = 47662 |
WHERE wmoid = 47662 AND date = DATE(2023,01,01) |
WHERE wmoid = 47662 AND ((date BETWEEN DATE(2023,01,01) AND DATE(2023,01,31))); |
| WHEATHER_STATION | なし | なし | 約1.8GB | 約1.8GB | 約1.8GB |
| WS_PARTITION | wmoid | なし | 約10MB | 約10MB | 約10MB |
| WS_CLUSTER | なし | wmoid, date |
約1.5GB | 約40MB | 約180MB |
| WS_P_C | wmoid | date | 約10MB | 約10MB | 約10MB |
検証結果について所感
パーティション、クラスターなしの場合はテーブルの大きさがクエリーコストとニアイコールでした。
この点は、よくあるデータベースでも同様の結果、全表スキャンやseq_scanと呼ばれる結果と同様に感じます。
クラスター実装のテーブルに対する結果において、wmoidのみを条件とした際のクエリーコストが思ったより高いと感じました。
また、クラスター実装の場合実行前にクエリーコストが読めない部分があり、実行するまでクラスターの効果が不明瞭である点を鑑み注意が必要であると感じました。
その上で、最適なクエリープランとコスト最適化の実現のため、これらを的確に利用する必要があると感じました。

2023年4月中途入社 関心の多くはDBにあります


Recommends
こちらもおすすめ
-

BigQueryのMaterialized Viewについて
2024.6.14
-
【BigQuery】テーブルの種類を整理してみる
2024.6.13




Special Topics
注目記事はこちら

データ分析入門
これから始めるBigQuery基礎知識
2024.02.28

AWSの料金が 10 %割引になる!
『AWSの請求代行リセールサービス』
2024.07.16