Amazon EMRバージョンアップのつまずきポイント

はじめに
EMRバージョンアップには以下のようなメリットがあります。
- 最新の機能を活用することで、生産性が向上し、コストが削減される。
- 更新されたアプリケーションの実行速度が速くなる。
- 最新のバグ修正により、安定したインフラストラクチャを実現できる。
- 最新のセキュリティパッチがセキュリティを強化する。
- オープンソースソフトウェア機能への最新のアクセス。
EMR 5.24以降のバージョンではAmazon EMRのSpark ランタイムが改善されています。EMR5.23を使っているレガシーの分析基盤があったので、その時点での最新バージョンであるEMR 6.12 へのバージョン変更を行いました。
EMRバージョンアップ時の環境を再現
今回は、EMRを利用したサンプルアプリケーションを利用して、バージョンアップの際の不具合を再現しようと思います。
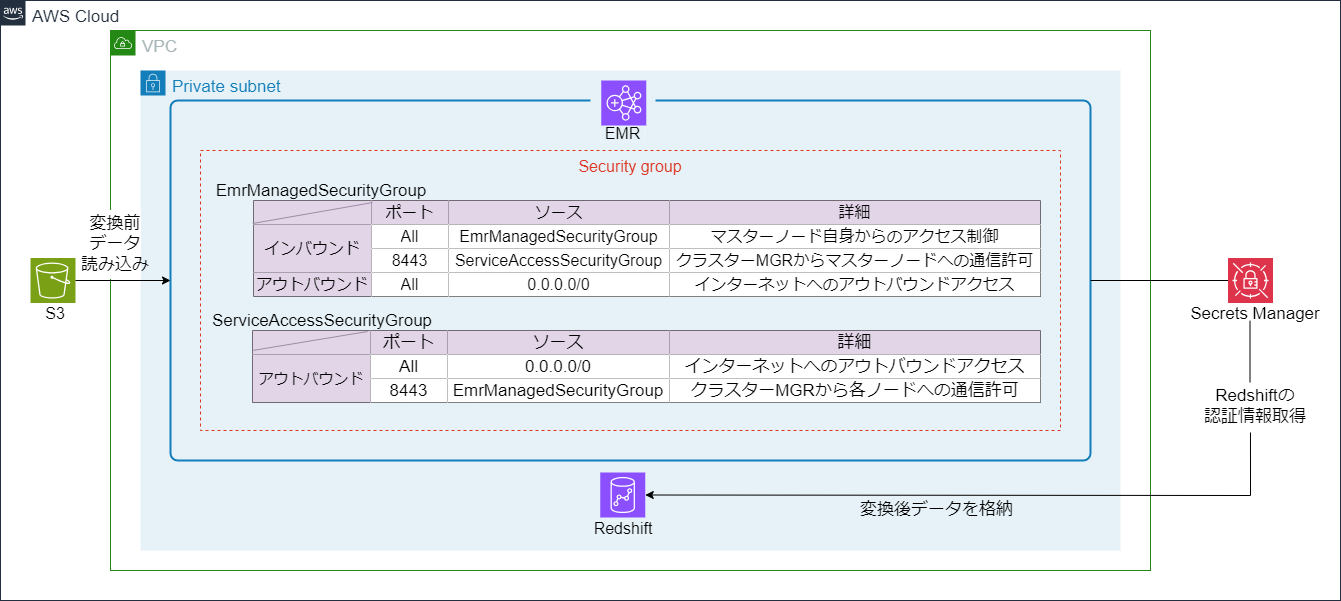
EMRバージョンアップ前のAWS構成
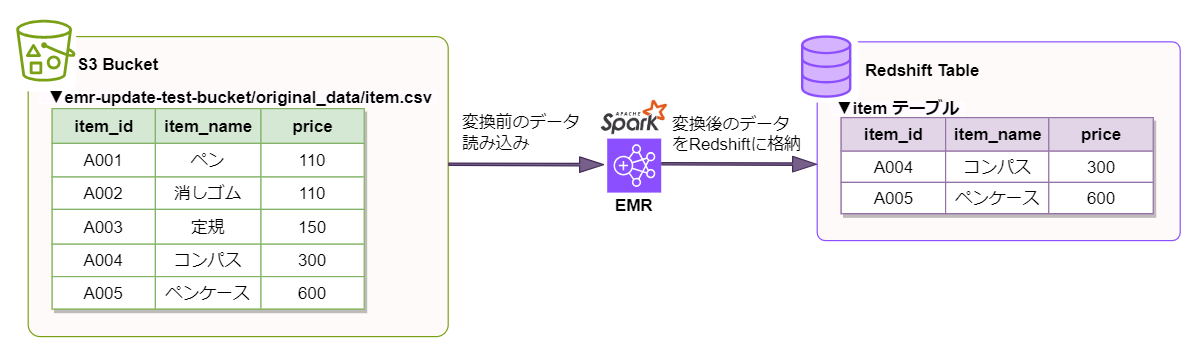
EMRで実行するscalaアプリケーション
EMR 5.23 -> EMR 6.12 にアップグレードし、実際に発生した不具合を再現していきます。S3上の変換前データを読み込み、データ変換を行った後、変換済みデータをRedshiftに格納するような処理を行うscalaアプリケーションになります。以下はデータ処理のイメージです。
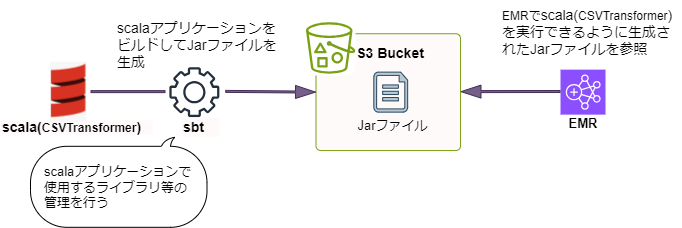
scalaアプリケーションをEMRで実行するために
build.sbtというファイル内で定義されています。build.sbtで参照する必要があります。scalaをEMRで実行する流れは以下のようなイメージになります。
※実際のコード内容(EMRバージョンアップ後)については後述の[EMRバージョンアップ前後での変更点について]の章の該当箇所をご参照ください。
EMRバージョンアップの際に直面した問題
EMRのバージョンアップを
EMR 5.23 -> EMR 6.12 にバージョンアップするに伴い、大きく分けて以下の2つの問題に直面しました。- sbtのバージョンアップを行った際に発生したライブラリの依存関係の問題
- サービスアクセス用のセキュリティグループ設定の不備によるEMRの検証エラー
それぞれどのような問題なのか見ていきます。
➀ sbtのバージョンアップを行った際に発生したライブラリの依存関係の問題
build.sbt ファイルのscalaプログラムを実行するために利用するライブラリについて、バージョンアップ後のEMRで依存関係があるsparkバージョンに合わせて、ライブラリのバージョンアップを行うと、jarファイルの生成時に以下のようなエラーが発生しました。[ec2-user@ip-XXX-XX-X-XX EMR_APP]$ sbt assembly [info] welcome to sbt 1.4.9 (Red Hat, Inc. Java 1.8.0_382) [info] loading settings for project emr_app-build from assembly.sbt ... [info] loading project definition from /home/ec2-user/EMR_APP/project [info] loading settings for project emr_app from build.sbt ... [info] set current project to CSV_Transformar (in build file:/home/ec2-user/EMR_APP/) [info] Updating [info] Resolved dependencies [warn] [warn] Note: Unresolved dependencies path: [error] sbt.librarymanagement.ResolveException: Error downloading org.apache.spark:spark-core_2.11:3.4.0 [error] Not found : [error] Error downloading io.github.spark-redshift-community:spark-redshift_2.11:6.0.0-spark_3.4 [error] Not found : [error] (update) sbt.librarymanagement.ResolveException: Error downloading org.apache.spark:spark-core_2.11:3.4.0 [error] Not found : [error] Error downloading io.github.spark-redshift-community:spark-redshift_2.11:6.0.0-spark_3.4 [error] Not found : [error] Total time: 4 s, completed Nov 9, 2023 5:26:22 AM
build.sbt ファイルで指定されているライブラリのバージョンが見つからなかったため、対象のライブラリをインポートすることが出来ずjarファイルの生成に失敗しています。
build.sbtに正しいscalaバージョンを指定することでエラー解消が見込めます。
2.12であると記載があります。Spark は Java 8/11/17、Scala 2.12/2.13、Python 3.7 以降、および R 3.5 以降で実行されます出典:Sparkドキュメント
build.sbtのscalaバージョンを2.12.Xに指定する必要があります。# before scalaVersion := "2.11.12" # after scalaVersion := "2.12.10"
build.sbtで管理しているライブラリの調整を行っています。[ec2-user@ip-XXX-XX-X-XX EMR_APP]$ sbt assembly [info] welcome to sbt 1.4.9 (Red Hat, Inc. Java 1.8.0_382) [info] loading settings for project emr_app-build from assembly.sbt ... [info] loading project definition from /home/ec2-user/EMR_APP/project [info] loading settings for project emr_app from build.sbt ... [info] set current project to CSV_Transformar (in build file:/home/ec2-user/EMR_APP/) [info] 1567 file(s) merged using strategy 'Discard' (Run the task at debug level to see the details) [info] 54 file(s) merged using strategy 'First' (Run the task at debug level to see the details) [info] Built: /home/ec2-user/EMR_APP/target/scala-2.12/CSV_Transformar-assembly-1.0.0.jar [info] Jar hash: 221f11e094d0648782c5dea492b89164755c7f12 [success] Total time: 71 s (01:11), completed Nov 9, 2023 5:28:48 AM
➁ サービスアクセス用のセキュリティグループ設定の不備によるEMRの検証エラー
== セキュリティグループに関連するEMRの検証エラー ==
ServiceAccessSecurityGroup にポート 9443 の EmrManagedMasterSecurityGroup からのイングレス ルールがありません というメッセージとともにEMRスタックの作成が失敗しています。

ServiceAccessSecurityGroup:
Type: AWS::EC2::SecurityGroup
Properties:
VpcId:
!Ref VpcId
GroupName: tec-test-service-access-security-group
GroupDescription: Security Group for EMR Service Access
SecurityGroupIngress:
- IpProtocol: "tcp"
FromPort: 9443
ToPort: 9443
SourceSecurityGroupId: !Ref EmrManagedSecurityGroup
Description: "Allow ingress rule from EmrManagedSecurityGroup on port 9443"


redshift-tec-test-db=# SELECT * FROM public.item; item_id | item_name | price ---------+------------+------- A004 | コンパス | 300 A005 | ペンケース | 600 (2 rows)
EMRバージョンアップ前後での変更点について
上記を踏まえて、EMRバージョンアップ前後で変更を加えた箇所は以下になります。
- Templateファイルで指定しているEMRのバージョンを
EMR 5.23->EMR 6.12に変更する - scalaアプリケーションの処理で利用しているライブラリのバージョンを変更する
- scalaバージョンの管理をしているファイル(build.sbt)で指定しているscalaバージョンを正しいものに変更する
- EMRで指定しているサービスアクセス用のセキュリティグループにポート
9443のインバウンドルールを追加する
EMRバージョンアップ後のAWS構成
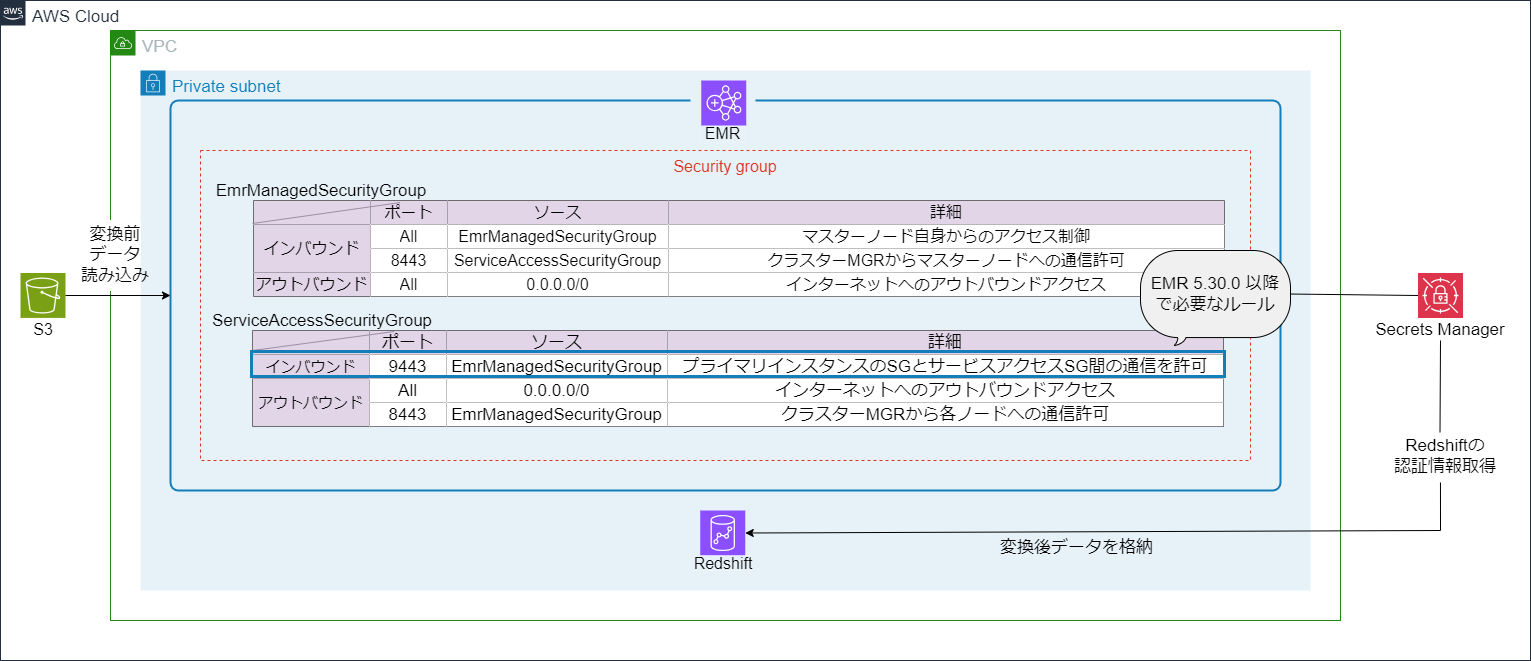
サンプルアプリケーションの構成
今回用意したサンプルアプリケーションの構成については以下になります。
■EMR/scala関連リソースの作業ディレクトリ(一部抜粋)
EMR_APP
├── build.sbt --------------------------------➀scalaアプリケーションのビルド用ファイル
├── project
│ └── assembly.sbt -------------------------➁jarファイルを生成するための拡張機能を定義したファイル
├── src/main/scala/com/testapp
│ └── csv_transformer.scala ----------------➂csvデータの変換処理を行うscalaプログラムが記述されたファイル
├── target/scala-2.1x
│ └── CSV_Transformar-assembly-1.0.0.jar ---⓸sbtを利用して生成されたscalaで記述した機能を固めたjarファイル
└── templates
├── emr.yaml -----------------------------⓹csvデータ変換処理を行うためのEMRリソースを定義したファイル
└── emr-configuration.yaml ---------------⓺EMRのsparkパラメーター等を定義したファイル
■build.sbt
name := "CSV_Transformar"
version := "1.0.0"
scalaVersion := "2.12.10"
libraryDependencies += "org.apache.spark" %% "spark-core" % "3.4.0"
libraryDependencies += "org.apache.spark" %% "spark-sql" % "3.4.0" % "provided"
libraryDependencies += "org.json4s" %% "json4s-native" % "3.6.6"
libraryDependencies += "org.json4s" %% "json4s-jackson" % "3.6.6"
libraryDependencies += "software.amazon.awssdk" % "secretsmanager" % "2.20.130"
libraryDependencies += "software.amazon.awssdk" % "apache-client" % "2.20.130"
libraryDependencies += "io.github.spark-redshift-community" %% "spark-redshift" % "6.0.0-spark_3.4"
libraryDependencies += "com.amazon" % "redshift.jdbc42.Driver" % "2.1.0.15" from "https://s3.amazonaws.com/redshift-downloads/drivers/jdbc/2.1.0.15/redshift-jdbc42-2.1.0.15.jar"
scalacOptions += "-target:jvm-1.8"
assemblyMergeStrategy in assembly := {
case PathList("META-INF", xs @ _*) => MergeStrategy.discard
case x => MergeStrategy.first
}
scalaのバージョンと各ライブラリのバージョンをバージョンアップ後のEMRと互換性があるバージョンに変える等、バージョン調整の変更を行っています。
| 修正前のライブラリバージョン | 修正後のライブラリバージョン | 詳細 |
| “org.apache.spark” %% “spark-core” % “2.4.0” |
“org.apache.spark” %% “spark-core” % “3.4.0”
|
emr-6.12.0で利用するsparkのバージョンに合わせてバージョンアップ
|
| “org.apache.spark” %% “spark-sql” % “2.4.0” |
“org.apache.spark” %% “spark-sql” % “3.4.0” % “provided”
|
|
| “org.json4s” %% “json4s-native” % “3.5.3” |
“org.json4s” %% “json4s-native” % “3.6.6”
|
最新バージョンに変更 |
|
“org.json4s” %% “json4s-jackson” % “3.5.3”
|
“org.json4s” %% “json4s-jackson” % “3.6.6”
|
|
|
“software.amazon.awssdk” % “secretsmanager” % “2.10.65”
|
“software.amazon.awssdk” % “secretsmanager” % “2.20.130”
|
|
|
“software.amazon.awssdk” % “apache-client” % “2.10.65”
|
“software.amazon.awssdk” % “apache-client” % “2.20.130”
|
|
|
“com.databricks” % “spark-redshift_2.11” % “3.0.0-preview1”
|
“io.github.spark-redshift-community” %% “spark-redshift” % “6.0.0-spark_3.4”
|
scalaバージョンを2.12に変更したため、spark-redshift_2.11から、互換性のあるバージョンに変更。 |
|
“com.amazon” % “redshift.jdbc42.Driver” % “2.1.0.15” from “https://s3.amazonaws.com/redshift-downloads/drivers/jdbc/2.1.0.15/redshift-jdbc42-2.1.0.15.jar”
|
“com.amazon“ % “redshift.jdbc42.Driver“ % “2.1.0.16“ from “https://s3.amazonaws.com/redshift-downloads/drivers/jdbc/2.1.0.16/redshift-jdbc42-2.1.0.16.jar“ | 互換性のあるバージョンに変更 |
■project/assembly.sbt
addSbtPlugin("com.eed3si9n" % "sbt-assembly" % "2.1.1")
こちらの修正箇所は、scalaアプリケーションのビルドに利用するsbt-assemblyのバージョンを同じくバージョンアップ後のEMRのscalaバージョンと互換性があるものに修正しています。
■src/main/scala/com/testapp/csv_transformer.scala
package com.testapp
import org.apache.spark.sql.SparkSession
import software.amazon.awssdk.services.secretsmanager.SecretsManagerClient
import software.amazon.awssdk.services.secretsmanager.model.GetSecretValueRequest
import software.amazon.awssdk.http.apache.ApacheHttpClient
import org.json4s._
import org.json4s.native.JsonMethods._
object CSVTransformer {
def main(args: Array[String]) {
val spark = SparkSession.builder.appName("CSVTransformer Application").getOrCreate() //SparkSessionの取得
val df = spark.read.option("header", true).csv("s3://emr-update-test-bucket/original_data/item.csv") //変換前のcsvファイルを読み込む
val transformedDF = df.filter("price > 200") //読み込んだcsvデータを変換する
val jdbcUrl = getjdbcUrl(args(0)) //redshift接続用のjdbcUrlを取得
transformedDF
.write
.format("io.github.spark_redshift_community.spark.redshift")
.option("url", jdbcUrl)
.option("dbtable", "item")
.option("aws_iam_role", args(1))
.option("tempdir", "s3://emr-update-test-bucket/temp/data")
.mode("overwrite")
.save() //変換済みデータをredshiftに書き込む
spark.stop() //アプリケーションの実行を終了する
}
def getjdbcUrl(secretArn: String): String = {
//SecretsManagerからredshiftの認証情報を取得し、redshift接続用のjdbcUrlを生成する
val httpClientBuilder = ApacheHttpClient.builder()
val client: SecretsManagerClient = SecretsManagerClient.builder().httpClientBuilder(httpClientBuilder).build()
val request = GetSecretValueRequest.builder().secretId(secretArn).build()
val response = client.getSecretValue(request)
val secretJson = response.secretString()
val jsonValue = parse(secretJson)
implicit val formats = DefaultFormats
val host: String = (jsonValue \ "host").extract[String]
val port: String = (jsonValue \ "port").extract[String]
val db: String = (jsonValue \ "dbname").extract[String]
val user: String = (jsonValue \ "username").extract[String]
val password: String = (jsonValue \ "password").extract[String]
val jdbcUrl = s"jdbc:redshift://$host:$port/$db?user=$user&password=$password"
jdbcUrl
}
}
こちらはEMR上で実行しているscalaアプリケーションになります。scalaアプリケーションからredshiftへのデータインポート処理を行っているのですが、こちらのデータ書き込みに利用しているredshiftのライブラリをbuild.sbtで修正したredshiftライブラリに変更しています。
■templates/emr.yaml
AWSTemplateFormatVersion: '2010-09-09'
Parameters:
PrivateSubnet:
Description: private subnet id
Type: String
RedshiftSecretArn:
Description: redshift secret arn
Type: String
RedshiftRoleArn:
Description: redshift role arn
Type: String
SecurityGroup:
Description: security group
Type: String
VpcId:
Description: vpc id
Type: String
VPCSecurityGroupAdditional:
Description: vpc id additional
Type: String
Resources:
EMRJobFlowRole:
Type: AWS::IAM::Role
Properties:
RoleName: emr-jobflow-role
AssumeRolePolicyDocument:
Version: 2008-10-17
Statement:
Effect: Allow
Principal:
Service: ec2.amazonaws.com
Action: sts:AssumeRole
ManagedPolicyArns:
- arn:aws:iam::aws:policy/service-role/AmazonElasticMapReduceforEC2Role
- !Ref RedshiftUserSecretsPermission
RedshiftUserSecretsPermission:
Type: AWS::IAM::ManagedPolicy
Properties:
Description: Policy to access redshift secrets
Path: /
PolicyDocument:
Version: "2012-10-17"
Statement:
- Effect: Allow
Action:
- "secretsmanager:Describe*"
- "secretsmanager:Get*"
- "secretsmanager:List*"
Resource: "*"
- Effect: "Allow"
Action: "kms:Decrypt"
Resource: "*"
EMRJobFlowRoleInstanceProfile:
Type: AWS::IAM::InstanceProfile
Properties:
Roles:
- !Ref EMRJobFlowRole
InstanceProfileName:
!Ref EMRJobFlowRole
EmrManagedSecurityGroup:
Type: AWS::EC2::SecurityGroup
Properties:
VpcId:
!Ref VpcId
GroupName: tec-test-emr-managed-security-group
GroupDescription: Security Group for EMR Service Access
SecurityGroupIngress:
- IpProtocol: '-1'
FromPort: -1
ToPort: -1
SourceSecurityGroupId:
!Ref SecurityGroup
ServiceAccessSecurityGroup:
Type: AWS::EC2::SecurityGroup
Properties:
VpcId:
!Ref VpcId
GroupName: tec-test-service-access-security-group
GroupDescription: Security Group for EMR Service Access
SecurityGroupIngress:
- IpProtocol: "tcp"
FromPort: 9443
ToPort: 9443
SourceSecurityGroupId: !Ref EmrManagedSecurityGroup
Description: "Allow ingress rule from EmrManagedSecurityGroup on port 9443"
EMRCluster:
Type: AWS::EMR::Cluster
Properties:
Applications:
- Name: Hadoop
- Name: Spark
Name: '@TEST-EMR-after-Update'
ServiceRole: EMR_DefaultRole
JobFlowRole:
!Ref EMRJobFlowRole
ReleaseLabel: emr-6.12.0
VisibleToAllUsers: true
LogUri:
Fn::Sub: s3://aws-test-logs-${AWS::AccountId}-${AWS::Region}/elasticmapreduce/update-test/
Instances:
TerminationProtected: false
Ec2SubnetId: !Ref PrivateSubnet
EmrManagedMasterSecurityGroup: !Ref EmrManagedSecurityGroup
EmrManagedSlaveSecurityGroup: !Ref EmrManagedSecurityGroup
ServiceAccessSecurityGroup: !Ref ServiceAccessSecurityGroup
AdditionalMasterSecurityGroups:
- !Ref SecurityGroup
- !Ref VPCSecurityGroupAdditional
AdditionalSlaveSecurityGroups:
- !Ref SecurityGroup
- !Ref VPCSecurityGroupAdditional
MasterInstanceGroup:
InstanceCount: 1
InstanceType: r4.xlarge
Fn::Transform:
Name: AWS::Include
Parameters:
Location: emr-configuration.yaml
EMRStep:
Type: AWS::EMR::Step
Properties:
ActionOnFailure: CONTINUE
HadoopJarStep:
Jar: command-runner.jar
Args:
- spark-submit
- --deploy-mode
- cluster
- --packages
- org.apache.spark:spark-avro_2.12:3.4.0
- --class
- com.testapp.CSVTransformer
- s3://emr-update-test-bucket/jar_file/CSV_Transformar-assembly-1.0.0.jar
- !Ref RedshiftSecretArn
- !Ref RedshiftRoleArn
JobFlowId:
!Ref EMRCluster
Name: Spark Application
こちらはEMRクラスターを作成するためのCloudFormationのTemplateになります。
EMRのサービスセキュリティグループにポート9443の通信を許可するインバウンドルールの追加と、scalaアプリケーションの実行コマンドに指定しているapache sparkのバージョンの変更を行っています。
■templates/emr-configuration.yaml
Configurations:
- Classification: "yarn-env"
ConfigurationProperties:
maximizeResourceAllocation: "false"
- Classification: "yarn-site"
ConfigurationProperties:
yarn.nodemanager.vmem-check-enabled: "false"
yarn.nodemanager.pmem-check-enabled: "false"
- Classification: "spark"
ConfigurationProperties:
maximizeResourceAllocation: "false"
- Classification: "spark-defaults"
ConfigurationProperties:
spark.executor.cores: "1"
spark.executor.memory: "1G"
spark.driver.memory: "1G"
spark.driver.cores: "1"
spark.executor.instances: "2"
spark.default.parallelism: "2"
spark.sql.shuffle.partitions: "200"
ConfigurationPropertiesの値を調整します。まとめ
- EMR上で実行しているアプリケーションが、バージョンアップ後のEMR(spark)と互換性があるかどうかを確認すること
- 変更を行いたいEMRのリリースバージョンに関するドキュメントを確認し、対象のリリースバージョン以降で何か必要な対応があるかどうかを確認すること

普段は社内/社外向けのデータの収集・加工~可視化を行うデータ分析基盤の開発を担当しています。 音楽鑑賞とギターが趣味です。


Recommends
こちらもおすすめ
-

Apache Sparkのパーティション分割について
2022.12.29




Special Topics
注目記事はこちら

データ分析入門
これから始めるBigQuery基礎知識
2024.02.28

AWSの料金が 10 %割引になる!
『AWSの請求代行リセールサービス』
2024.07.16