[AWS re:Invent 2024] Store tabular data at scale with Amazon S3 Tables (STG367-NEW)

はじめに
re:Invent 2024でS3 Tablesが発表されました。その後現地でもセッションが追加され、私も当日にそのセッションに参加しました。
今回はそのセッションについて、内容について振り返ってみようと思います。セッションの動画は以下になります。
セッション概要
Amazon S3 Tablesは、Apache Icebergテーブルに表形式のデータを保存することを目的として構築されています。Amazon S3 Tablesを使用すると、Amazon S3コンソールで数回クリックするだけで、テーブルを作成し、テーブルレベルの権限を設定することができます。これらのテーブルは、表形式データ用に特別に構築されたストレージによってバックアップされているため、ストレージ内の管理されていないテーブルと比較して、1秒あたりのトランザクション数が増加し、クエリのスループットが向上します。このセッションに参加すると、クエリのパフォーマンスを継続的に最適化し、コストを最小限に抑えるために、Amazon S3でコンパクション、スナップショット管理などのテーブル管理タスクを自動化する方法を学ぶことができます。
出典: AWS re:Invent 2024 – [NEW LAUNCH] Store tabular data at scale with Amazon S3 Tables (STG367-NEW)
(1) S3 Tables誕生の背景
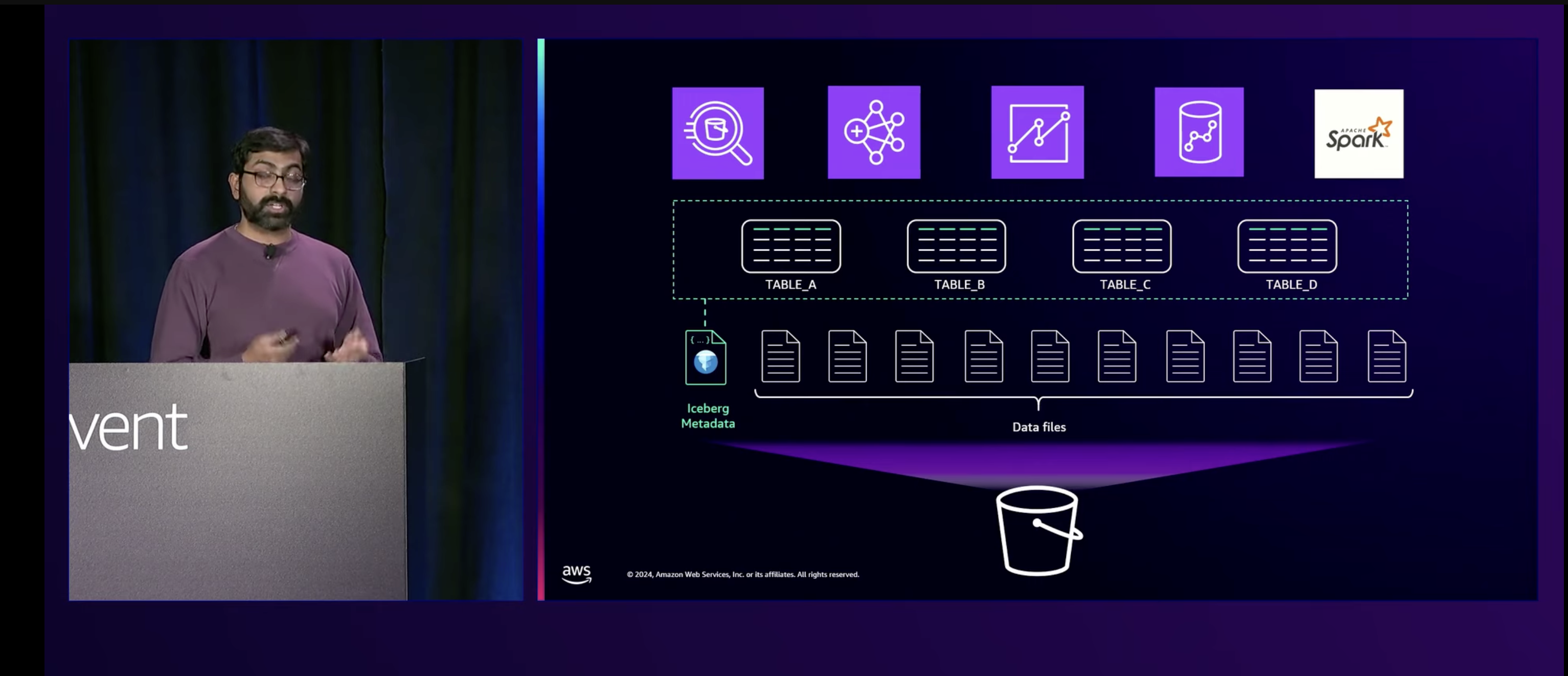
データ分析の現場ではファイル形式としてParquetが使われることが多く、AWSではS3がストレージとして使われている。そしてファイルにたくさんの書き込みやトランザクション等に対処するために、オープンテーブルフォーマットが生まれ、その中でApache Icebergが特に使われることが多くなったそうです。
私はApache Icebergは本番環境で利用した経験はありませんが、CloudFormationでGlue Data Catalogにテーブルを作り、Athena経由で必要なデータをINSERTをして、別の処理の際にクエリをして判定すると言ったような、簡易的なDataBaseとして使っているケースがありました。Apache IcebergはINSERTだけでなく、UPDATEやDELETEも実行できるため、移行先として検証したことがありました。本来は説明にある通り大量のデータを扱うための技術なので、自分の認識の差をここで修正できました。
(2) Apache Icebergの特徴とその課題について

Apache Icebergによってトランザクションや過去の状態に戻れたりする機能など便利な機能が使えるようになるが、Apache Iceberg自体にも利用するうえでいくつか気を付けるべき点があります
- 大量のデータを管理しながらパフォーマンスをどうやって維持するか
- テーブルレベルでのセキュリティをどうやって維持するか
- スナップショットの管理などの運用上の負担をどうするか
これらの課題を解決するために作られたサービスとして、S3 Tablesが作られたそうです。
(3) S3 Tablesの特徴 と 3つの柱
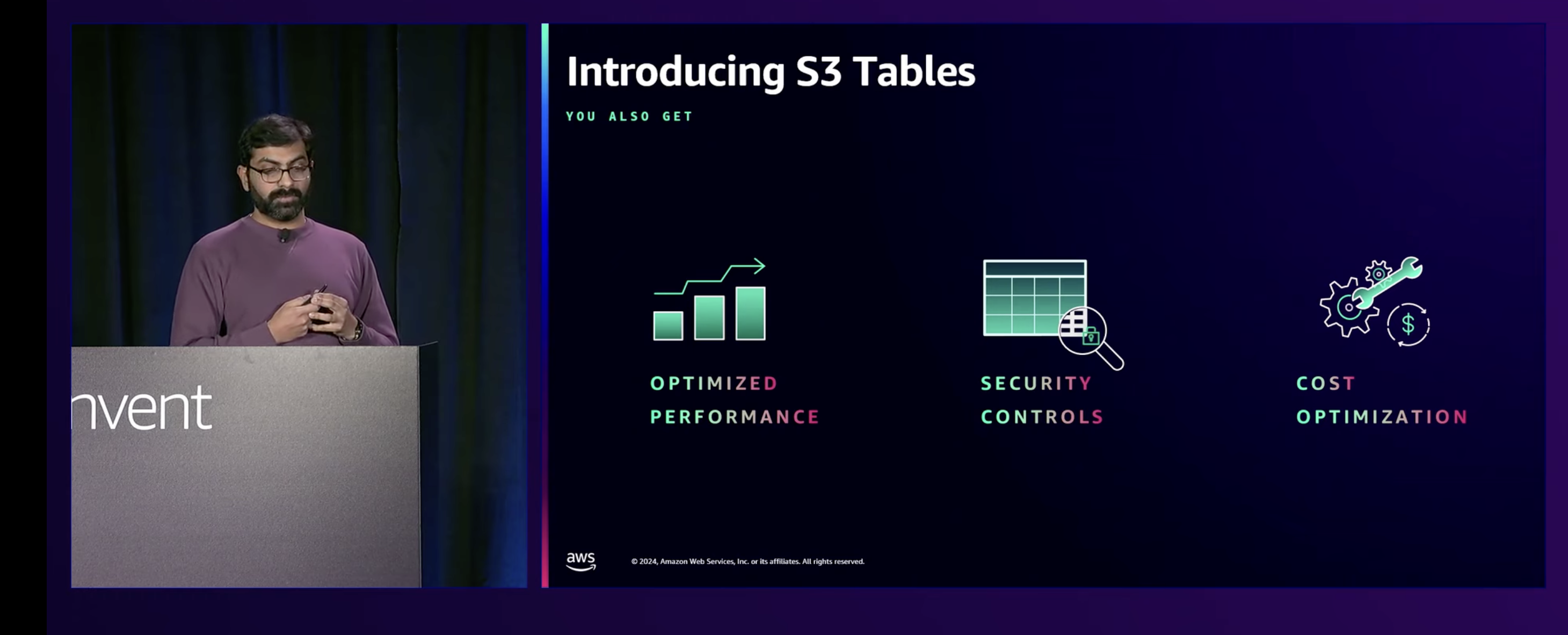
S3の中で扱われるということで、独自のARNを持つこと、CLIを用いてS3 Tablesを操作できること、エンドポイントを持てることなどが紹介されていました。その後S3 Tablesの特徴として、大きく分けて3点あることが述べられていました。
- パフォーマンスの最適化
- セキュリティコントロール
- コスト最適化
この後に、それぞれの項目について詳しく解説されました。
1つ目の柱 パフォーマンスの最適化

画像の通り、トランザクションが10倍になり、クエリの速度が3倍になるそうです。比較対象はS3 Tablesを使わずにApache Icebergテーブルを作成したときだそうです。
さらにApache Icebergで更新頻度が高くなると履歴ファイルが増えるのですが、これに対応するための機能としてApache Icebergの機能にある圧縮(compaction)があります。この圧縮を自動で行うことでS3 Tablesの運用負荷を下げているそうです。
2つ目の柱 セキュリティコントロール

IAM Policy、S3バケットポリシーなどでS3 Tablesへのアクセスをコントロールできることが特徴として挙げられていました。さらにネームスペースでより細かくアクセス先を制限できるそうです。
3つ目の柱 コスト最適化
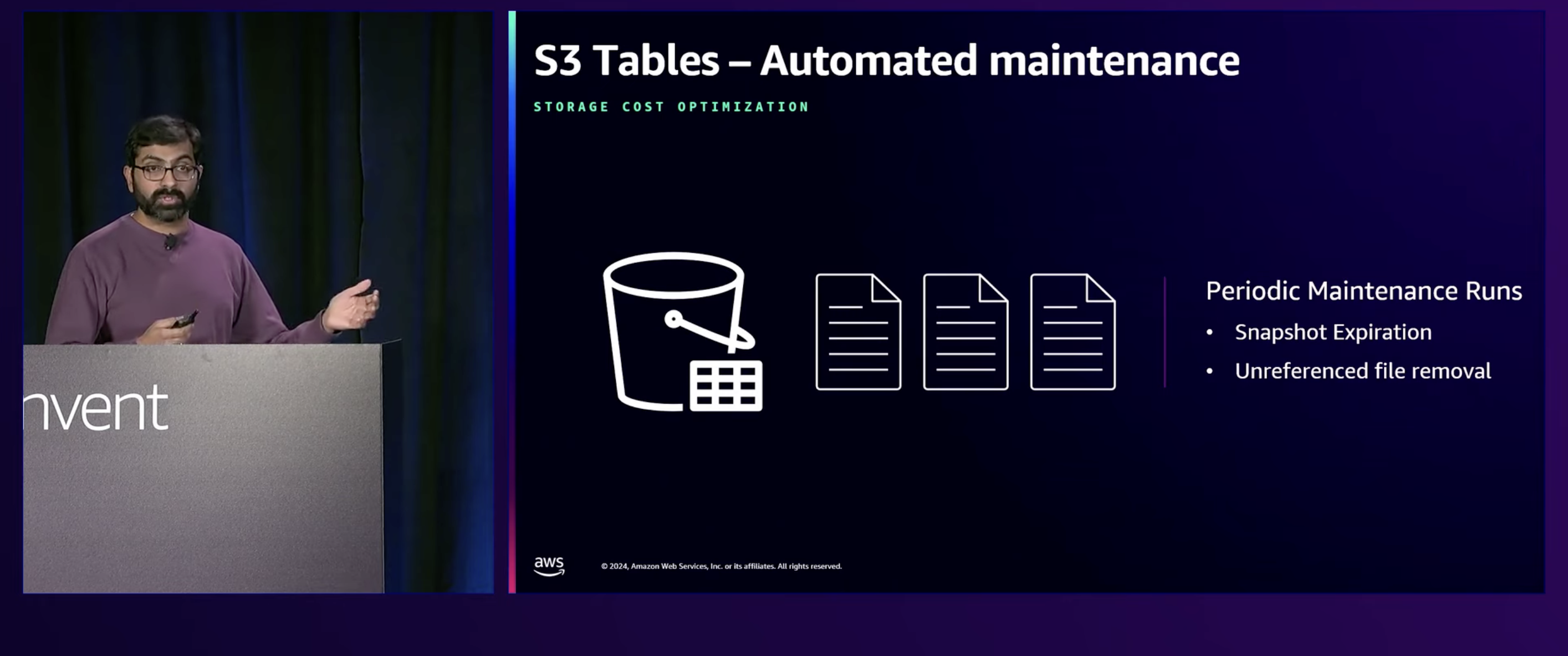
Apache Icebergの機能にはスナップショットの自動取得があり、スナップショットを利用することでどの時点にも戻すことが可能です。しかし、必要のないスナップショットの削除など、スナップショットの管理が課題だったそうです。こちらはS3 TablesによってAPI経由でルールを設定すると、自動で管理が行われるようになるとのことでした。
(4) 使用例: Glue Data Catalogとの連携

Glue Data Catalogとの連携方法について紹介していました。以前は自分でApache Icebergを構築すると、Glue Data Catalogとの連携はCloudFormationやAPIなどで自分で登録する必要がありました。S3 Tablesでは自動的に登録されるとのことでした。
このGlue Data Catalogとの連携は2024年12月時点ではプレビューの機能です。現在はテーブルの作成が難しく、AthenaやEMRから作成できないのが理由の一つだそうです。
先日自分で操作したときにこのテーブルのスキーマがSpark経由でしか作成できない部分はかなり気になったので、セッションでも触れられていて安心しました(当日は自身の英語力が原因で聞き漏らしていました)。今後の進展に期待したいです。
(5) 使用例: Athena, Redshiftとの連携

AthenaやRedshiftからS3 Tablesにアクセスする方法について紹介していました。Athenaは普通にアクセスできるけど、RedshiftはLake Formationからリソースリンクの作成が必要だそうです。
以前EMRでテーブルのスキーマを作成して、Athena経由の場合もLake Formationの設定が必要だったはずなのですが、そこに触れられていないのは気になりました。
(6) 使用例: Lake Formationとの連携

Lake Formationを使うことで、S3 Tablesに対して、IAMやIdentity Centerと連携してDBやテーブル、カラム単位でアクセスを管理できるそうです。
(7) 使用例: EMRとの連携

これまでは基本的にGlue Data Catalogなどを経由する形でしたが、EMRは直接S3 Tablesとの連携ができるそうです。直接連携した場合と、Glue Data Catalogを経由した場合の機能の差などが気になりました。
(8) S3 Metadata Tablesについて

最後にKeynoteにてS3 Tablesと同じタイミングで発表されたS3 Metadata Tablesにも触れられていました。オブジェクトに関するメタデータをS3 Tablesに保存される機能があり、これでS3のデータの検索が楽になりそうでした。
まとめ
今回のセッションではS3 Tablesの機能とAthenaやRedshiftなどからの連携方法が中心に紹介されていました。
S3 TablesはApache Icebergを利用しやすくしたサービスなので、使いこなすためにはApache Icebergの方の情報も整理した方が良さそうでした。またS3 Metadata TablesはEMRなどからApache Icebergを利用することとは別の活用方法にあたるので、プレビューとはいえ一度検証してみたいなと思いました。
そしてセッションの最後で講演者の方がこれは始まりに過ぎないと言ったので、今後のS3 Tablesの進化にも期待していきたいです。

2018年新卒入社。エンジニア。フロントエンド&サーバサイドを担当。 Vue.js, Ruby on Rails, Ruby, Javaを主に使用する。 会社では全力で働き、家では全力で遊ぶ。


Recommends
こちらもおすすめ
-

AWSとWordPressで企業Webサイトを構築する
2019.5.16





Special Topics
注目記事はこちら

データ分析入門
これから始めるBigQuery基礎知識
2024.02.28

AWSの料金が 10 %割引になる!
『AWSの請求代行リセールサービス』
2024.07.16