【セッションレポート】オープンテーブルフォーマットで実現する、大規模データ分析基盤の構築と運用 #AWS Summit Japan 2025

はじめに
この記事は「オープンテーブルフォーマットで実現する、大規模データ分析基盤の構築と運用」のレポート記事です。
オープンテーブルフォーマットやApache Icebergに関する基礎的な知識を紹介するセッションですので、興味のある方は是非ご覧ください。
ちなみに、本セッションは AWS Summit Japan サイトからユーザー登録いただくことでアーカイブ視聴が可能なセッションとなっておりますので、気になった方はぜひ見てみてください。
AWS Summit Japan 2025
ユーザー登録はこちらから
※ 本情報は、2025年7月10日時点での情報となります。
セッション情報
タイトル
オープンテーブルフォーマットで実現する、大規模データ分析基盤の構築と運用
スピーカー
疋田 宗太郎 様
アマゾン ウェブ サービス ジャパン合同会社 サービス&テクノロジー事業統括本部 Data & AI ソリューション本部 アナリティクススペシャリストソリューションアーキテクト
概要
機械学習や生成 AI の急速な発展により、企業のデータ基盤には、より高い拡張性と堅牢性が求められています。本セッションでは、AWS の分析サービスとオープンテーブルフォーマット (OTF) を活用し、この要件に応える大規模トランザクショナルデータレイクの構築方法をご紹介します。高いパフォーマンス、コスト最適化、運用の優秀性を実現するための具体的な実装方法と、大規模テーブル運用のベストプラクティスを解説します。さらに、ストリーミングデータにおけるスキーマ進化の課題に対し、OTF を活用することで高い信頼性とシームレスな運用を実現する手法もご紹介します。データ基盤の近代化に取り組むデータエンジニアの方々に、実践的な知見をお届けします。
セッションレポート
このセッションではオープンテーブルフォーマットと呼ばれるもの説明と、それをAWS上で構築する方法について紹介されていました。
私がこれを見ようと思ったきっかけはAmazon S3 Tablesでした。これは2024年のre:Inventで発表されたサービスですが、実際に使ってみるためにはまずApache Icebergとは何かを理解する必要がありました。その際に前提知識を集めるために苦労したことがありました。そのため当時は理解が曖昧だった部分もあったのですが、改めてこのセッションを通してApache Icebergを扱うための知識を再確認することができました。
参考:
Amazon S3 Tables
以降では参考になったポイントをいくつかご紹介します。
1. トランザクショナルデータベース登場の背景
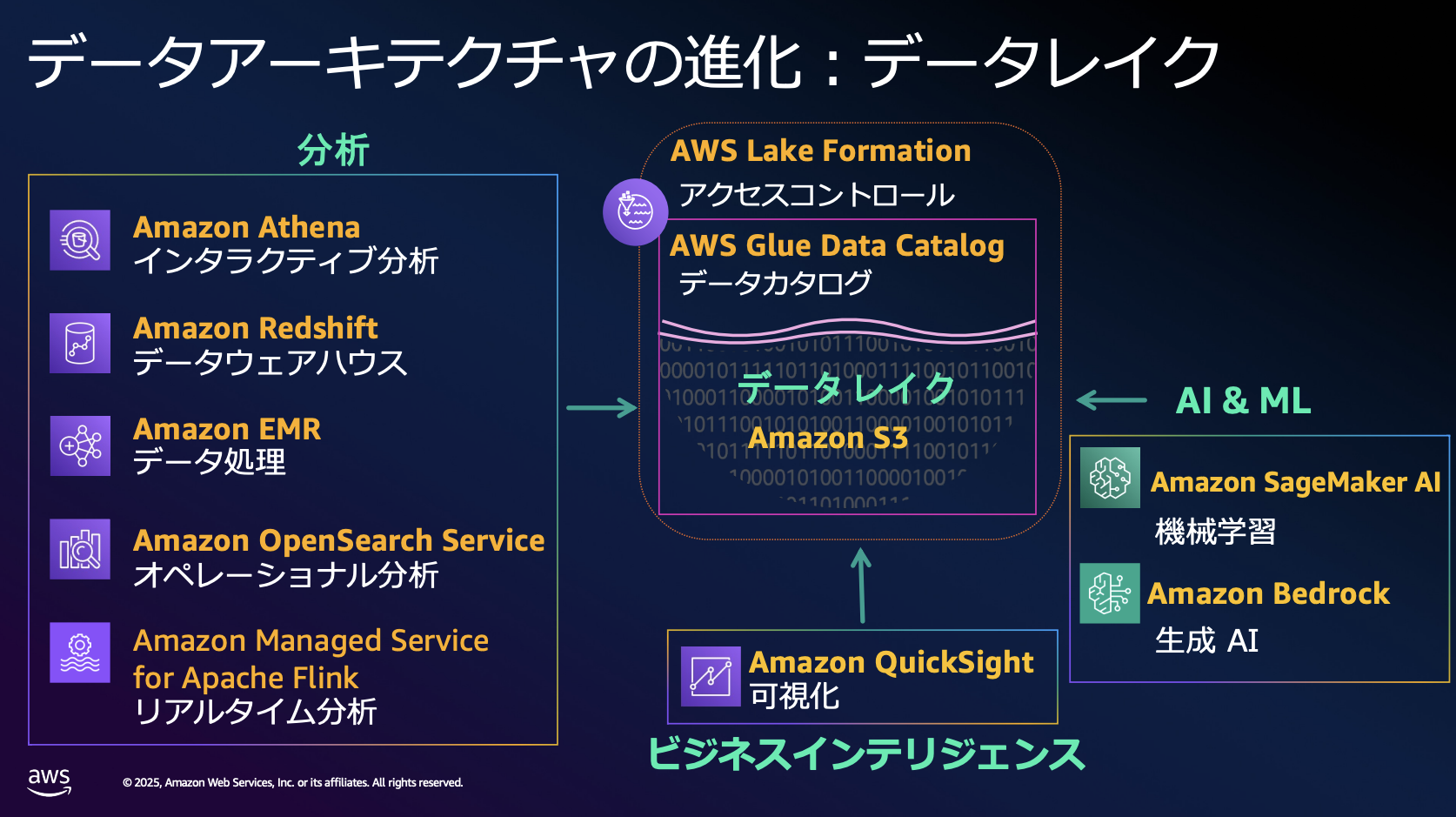
DWHでデータを管理するとコストや扱えるデータに制限が出るため、分析と管理の方法を分けたことが始まりだそうです。これはAmazon Redshiftで分析と管理を行なっていたものを、S3にデータを置いて、Athenaで分析するといった方法だと思います。Amazon Redshift は稼働時間単位で料金が発生する従量課金制ですので、利用していない時間でも料金が発生し続けます。
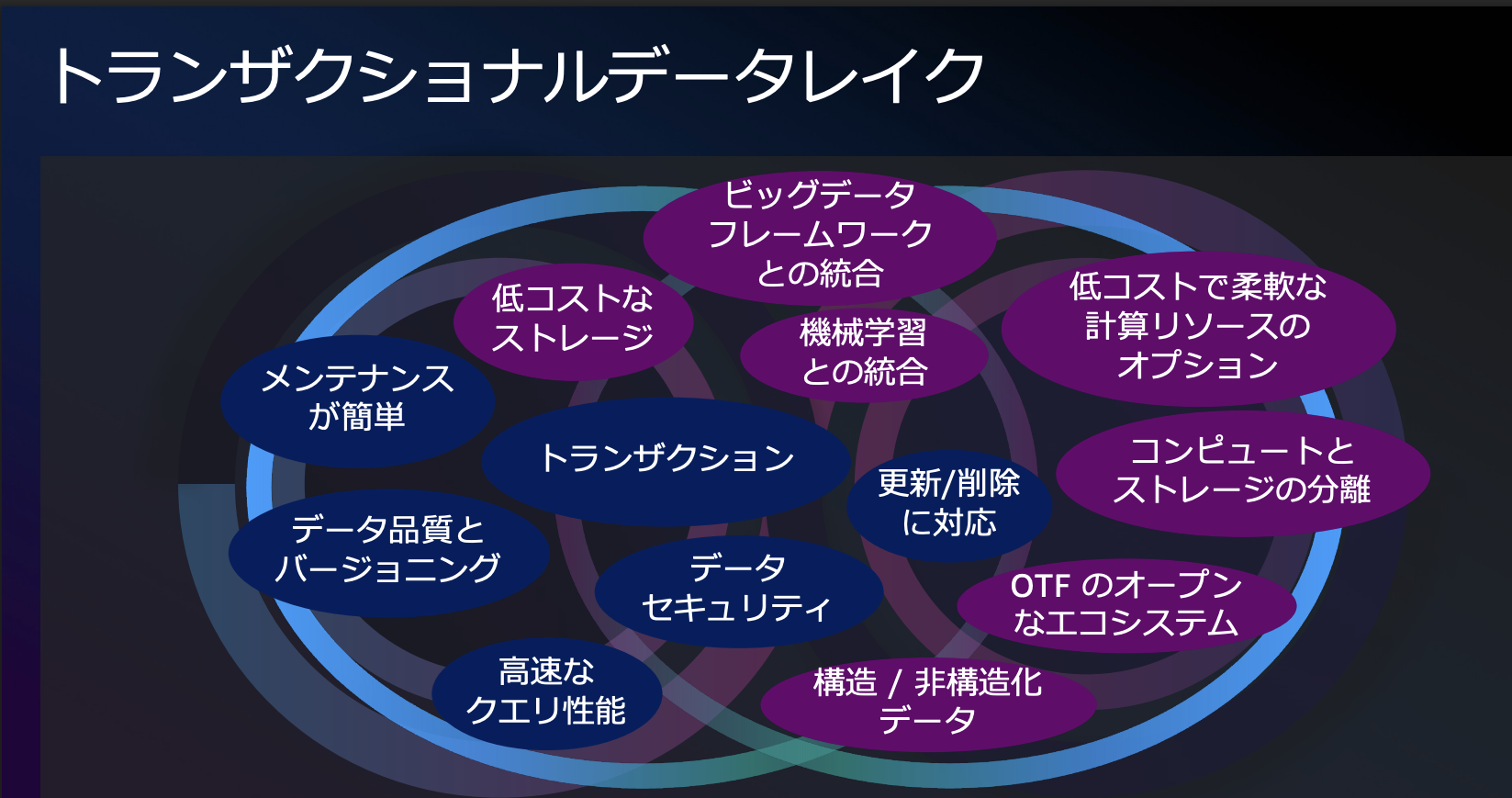
データレイク自体にも課題があり、データレイクはDBではないので同時書き込みやスモールファイルによるパフォーマンスの問題、特定のデータの更新削除が難しいなどが出てきます。これらの問題を解決するためにトランザクションやデータの整合性を管理するための仕組みとしてトランザクショナルデータレイクが利用できないか? という要望が高まったそうです。
これを聞いて私はAthenaのことを思い出しました。AthenaではINSERT自体は可能ですがINSERTしたものを更新、削除することはできません。またINSERTをすることでスモールファイルが多数生成される件については、Athenaの公式ドキュメントにも記載があります。
参考: Amazon Athena > INSERT INTO

そしてトランザクショナルデータレイクを実現するための技術として、オープンテーブルフォーマット(OTF)が登場したそうです。OTFを使うとデータレイクでDB相当のことをすることができるようになります。
その後に続けてトランザクショナルデータベースのユースケースの紹介がありました。ストリーミングデータの取り込みでは、書き込み途中のデータを見せないようにする必要があったり、スモールファイルの更新が多数行われるため、クエリ効率を上げるためにファイルを圧縮する必要があります。また別の例としてデータプライバシーの要件が挙げられていました。特定の行を削除・更新する場合、従来の場合だと多数のファイルの中からたった1行を見つけるために、莫大な計算リソースと処理時間をかける必要があります。
いずれもOTFを利用することで効率的な対応ができるとのことでした。
2. オープンテーブルフォーマット(OTF)の基礎知識
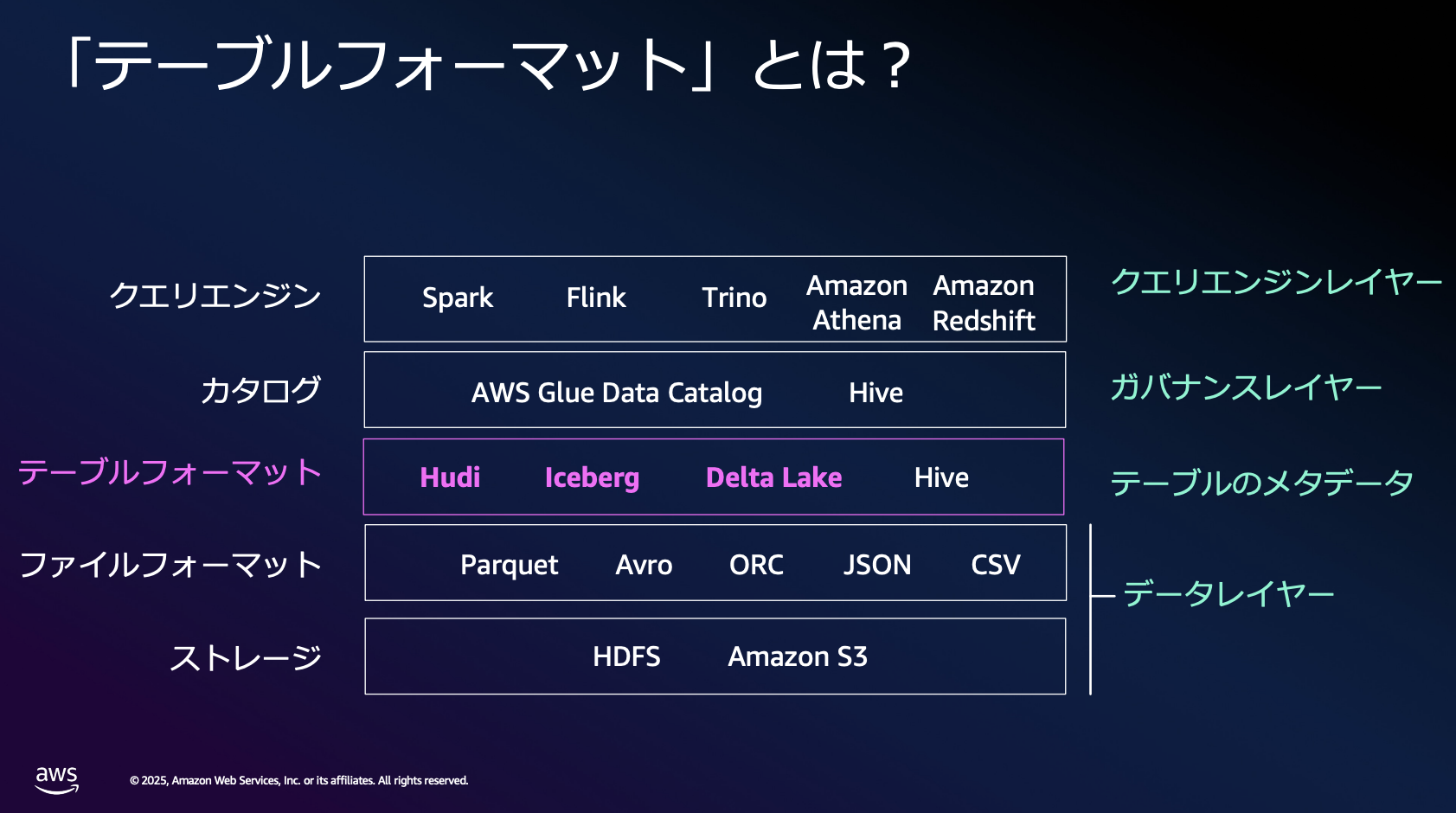
次にOTFに関する具体的な説明がありました。テーブルフォーマットはストレージ上にある複数のファイルを1つのテーブルとして管理するための仕組みを提供してくれます。既存の技術を代替するものではなく、既存の技術を組み合わせて新しい仕組みを提供する土台のような技術がOTFの立ち位置のようです。

次に更新・削除時の仕組みの説明がありました。こちらは名称に差はあるものの全てのOTFに共通する仕組みとのことでした。更新・削除をした場合、既存のファイルを書き換えるわけではなく、あくまで差分のメタデータが追加されるそうです。論理的には削除・更新はされていても、ファイル単位では過去のデータが残っているということになります。またコンパクションという圧縮処理を行うと差分のファイルが1つにまとめられてファイル数を削減することができます。
そして元のデータを更新するのではなく、差分ファイルを持つことでタイムトラベルと呼ばれる過去の状態を参照する機能が使えるそうです。
またAWSではいくつかあるOTFのうち、Apache Icebergに注力していることが紹介されていました。この後で出てくる機能はApache Icebergの公式サイトでも紹介されているので、併せて見ると理解が深まると思います。
参考: Apache Iceberg
3. Apache Icebergによるトランザクショナルデータレイクの実現

次にトランザクショナルデータレイクの必要な特性に関する説明がありました。これらの機能の紹介とどうやって実現するかに関する内容でした。
こちらは内容が多かったのでポイントを箇条書きにしていきます
- レコード単位の効率的な更新と削除
- SQLに加えて独自の関数もある
- 効率よくレコードを抽出できる仕組みになっている
- 複数のモードがある
- Copy-on-Write = ファイル全体を書き換えるので、読み込み速度を上げるが書き込みは遅い
- Merge-on-Read = 差分のみを追加するので、書き込み速度は速いが読み込みは遅い
- データ構造の進化への対応
- 既存のデータに影響を与えずに、スキーマを柔軟に変えることができる
- カラムの追加、削除、名前の変更など
- パーティションの単位の変更が可能
- 2025-01は月ごと、2025-03は日付ごと、など 別々に対応できる
- 既存のデータに影響を与えずに、スキーマを柔軟に変えることができる
- データの整合性と一貫性
- 同時に書き込み、読み込みを行った場合でも、データの一貫性を保証してくれる
- 書き込み途中のデータを提供することがなくなる
- スナップショットにタグをつける
- 特定のスナップショットをすぐに閲覧ができる
- タグのあるものを削除対象外にすることができる
- 同時に書き込み、読み込みを行った場合でも、データの一貫性を保証してくれる
- 性能に最適化されたデータ構造
- スモールファイルのコンパクション(圧縮)
- 小さいファイルをまとめて、クエリの性能を上げることができる
- 隠しパーティション
- パーティションがパス等に設定されてなくても後から定義することで、検索効率を上げられる
- スモールファイルのコンパクション(圧縮)
- きめ細やかなアクセス管理
- 後述
4. OTFのデータアクセスコントロール
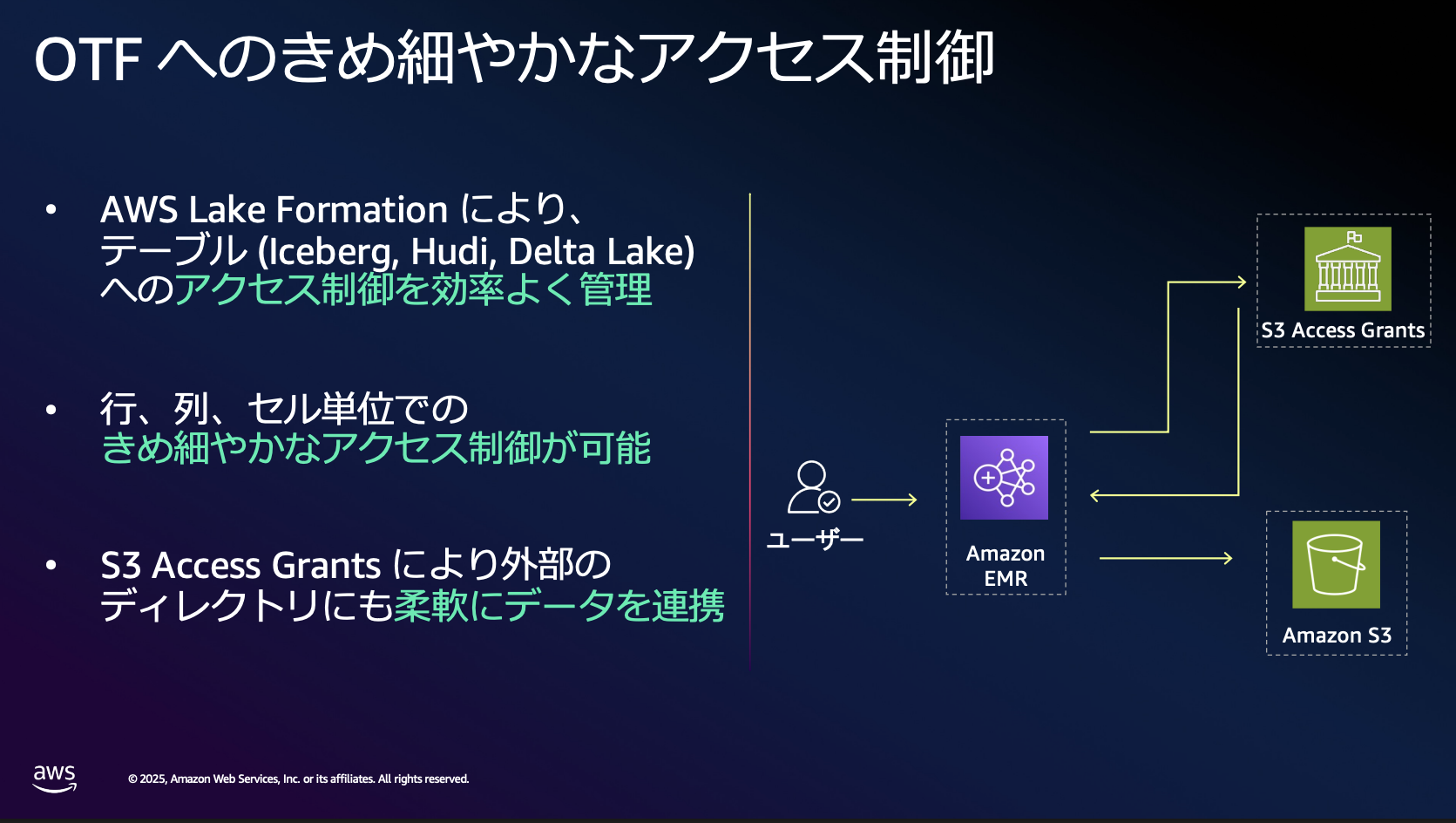
データのアクセス制御に関する要件はあるものの、Apache Iceberg自体にそれらの機能は備わっていないとのことでした。そのためAWSではAWS Lake Formationを使うことで列や行単位でアクセス制御を実現することができるそうです。
5. Amazon Sage Maker Lakehouseで始めるトランザクショナルデータレイク
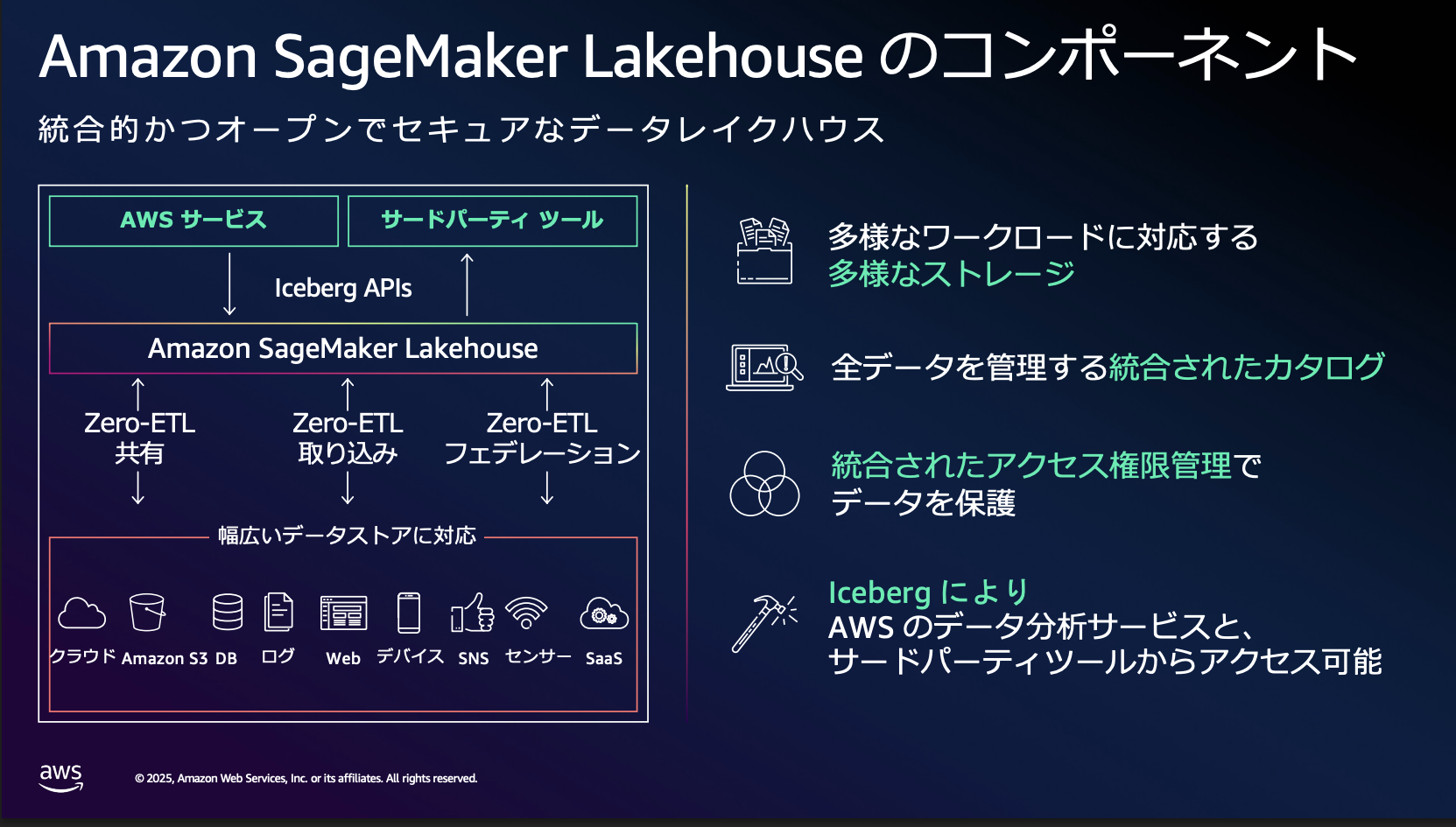
最後にApache Icebergの運用を統合的に行うサービスとしてAmazon SageMaker Lakehouseが紹介されていました。Apache Icebergの運用をすぐに始められるのでおすすめだそうです。
まとめ
このセッションを通してApache Icebergを扱うために必要な前提知識であるOTFと、AWSでの利用方法を学ぶことができました。基礎的な内容が網羅できるため、OTFの初心者への導入として非常に充実した内容でした。また個人的にはApache Iceberg関連の新サービスでもあるAmazon S3 Tablesに関する内容の紹介もあればよかったなと思いました。
またストレージに関するセッションはこれ以外にも多数あったため、合わせて見ると理解が深まるのでおすすめです。すでに弊社からセッションレポートが出ているものもあるのでこちらも見てみて下さい。
-
[AWS-04] Amazon S3 によるデータレイク構築と最適化
-
[AWS-05] クラウドストレージのコスト最適化戦略 – AWS ストレージの賢い活用法
-
[AWS-48] AWS 上で Apache Iceberg レイクハウスを構築・運用するためのベストプラクティス


2018年新卒入社。エンジニア。フロントエンド&サーバサイドを担当。 Vue.js, Ruby on Rails, Ruby, Javaを主に使用する。 会社では全力で働き、家では全力で遊ぶ。


Recommends
こちらもおすすめ




Special Topics
注目記事はこちら

データ分析入門
これから始めるBigQuery基礎知識
2024.02.28

AWSの料金が 10 %割引になる!
『AWSの請求代行リセールサービス』
2024.07.16