LangChain v1.0 のすすめ ~新機能 Middleware~

この記事は NHN テコラス Advent Calendar 2025の16日目の記事です。
12月は毎日記事があがりますので、是非他の記事も読んでみてください!
はじめに
こんにちは、いかがお過ごしでしょうか?
私はつい最近、社内インフラの管理から社内 AI 開発へジョブチェンジしました。そこで今回は AI 開発に関する記事を執筆してみたいと思います。
ここ数年でカスタマーサポートや翻訳、コード生成をはじめとする様々な領域で大規模言語モデル (以下、LLM) の導入が進んでいます。
しかし本番環境で LLM を運用する際には、単純にユーザーの入力を API に直接送信するだけではパフォーマンスに限界があり、独自データベースから回答や会話履歴の管理、外部ツールの自動実行に LLM プロバイダーの切り替えなど様々な機能を追加する必要があります。
それらの包括的な LLM アプリケーション開発をサポートするフレームワークは各社から様々な思想で提供されていますが、本記事は特に LangChain というオープンソースフレームワークに焦点を当てて解説していきたいと思います。
LLM アプリケーションの開発において、フレームワーク選定は単なる開発効率の問題にとどまらず、システムの保守性、スケーラビリティ、そして技術的負債の蓄積に直結する重要な技術的判断ですから、慎重に行う必要があります。
本記事はそんなフレームワーク選定の一助になればという思いで書かせてもらいました。どうぞ最後までお読みいただければ幸いです。
それではドイツの詩人であるゲーテの名言とともに 「LangChain v1.0 のすすめ ~新機能 Middleware~」 はじめていきます!
自分一人で石を持ち上げる気がなかったら、二人でも持ち上がらない。
想定読者
- LLM アプリケーション開発を始めたいが、どのフレームワークを選定してよいのかわからない
- 現在利用しているフレームワークに不満があり、リプレイスを検討している
- Langchain v1.0 の新機能である Middleware について知りたい
LangChain v1.0 と Middleware について
LangChain v1.0
LangChain は LLM を活用したアプリケーション開発を支援するオープンソースフレームワークの1つであり、他のフレームワークに比べてエコシステムが成熟していたり、豊富なコンポーネントライブラリが揃っていることが強みの1つです。
そんな LangChain は 2025/10 に初のメジャーバージョンである LangChain v1.0 を一般公開しました!
CEO である Harrison Chase 氏のリポジトリへの初コミットが 2022/10 ですので、約3年かけて最初のメジャーバージョンがリリースされたことになります。
LangChain 1.0 is our first major stable release, marking our commitment to no breaking changes until 2.0. After three years of feedback, we’ve streamlined the framework to focus on what matters most: building agents quickly while having the flexibility to customize when needed.
出典 : LangChain 1.0 now generally available
リリース文面から、今回のメジャーバージョンである 「1.0」 リリースは単なる数字の変更ではなく、安心して本番環境にアプリケーションを導入できるような安定性と信頼性を達成したことの象徴であるように感じました。そしてそれを強調するように、次のメジャーバージョンである 「2.0」 まで互換性を失うような破壊的な変更は行わないとも説明されています。
また、個人的にはリリースとドキュメントの乖離が気になっていたので、このタイミングでドキュメントが整備されたというのも大きなポイントだと感じています。
このリリースによって長期的な開発基盤として LangChain を採用する機運が高まってきたといってもよいのではないでしょうか。
LangChain v1.0 について理解を深めてもらうために、リリースの中でも 「最大の新機能」 として紹介されている Middleware について詳しくみていきたいと思います!
Middleware
LangChain has had agent abstractions for nearly three years. There are now probably 100s of agent frameworks with the same core abstraction.
They all suffer from the same downsides that the original LangChain agents suffered from: they do not give the developer enough control over context engineering when needed, leading to developers graduating off of the abstraction for any non-trivial use case.
In LangChain 1.0 we are introducing a new agent abstraction (Middleware) which we think solves this.
出典 : Agent Middleware
モデル (もっというとエージェント) の信頼性を高めるにはどうすればよいでしょうか。その答えは 「モデルに取り込まれるコンテキストを高いレベルで制御する」 ことです。この制御こそがコンテキストエンジニアリングであり、モデルに入力されるコンテキストを制御することはすなわち出力を制御することに直結します。
このコンテキストエンジニアリングにおいて、シンプルなエージェントであるうちはフレームワークを利用するだけで十分ですが、ある程度の複雑さやパフォーマンスを求め始めるとどうでしょうか。
どうしてもフレームワークが提供する標準的な抽象化では対応できず、低レベルなカスタム実装が必要になり、その結果コードの保守性が失われてしまいます。
LangChain はこの問題を解決するために積極的な機能拡張を続けてきましたが、この拡張により設定パラメータが大幅に増加し、パラメータ間の相互依存関係も複雑化していきました。その結果、本番環境でのチューニングや運用保守が困難になるという別の問題が浮上してきました。
LangChain v1.0 ではそのような問題を新しいエージェントの抽象化 (Middleware) で解決していこうとしています。
Middleware defines a set of hooks that allow you to customize behavior in the agent loop, enabling fine grained control at every step an agent takes.
出典 : LangChain and LangGraph Agent Frameworks Reach v1.0 Milestones
Middleware は既存のエージェントコンポーネント・ループに変更を加えるのではなく、拡張性を提供するという考え方に基づいて設計が行われています。すなわちエージェントの実行フローの各処理にフックを設け、カスタムロジックを注入できるようにすることで、エージェントの状態を監視したり修正を加えたりとより明確で細かい制御を可能にしていくというアプローチです。
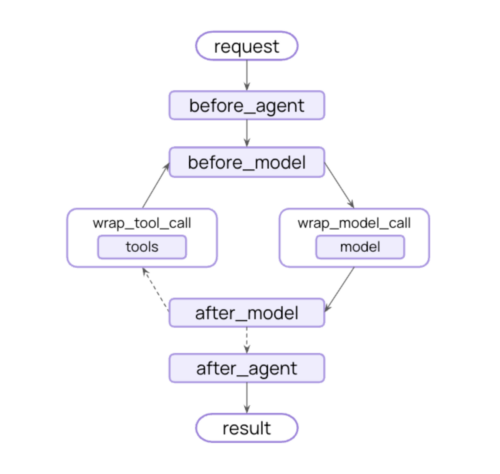
出典 : LangChain and LangGraph Agent Frameworks Reach v1.0 Milestones
また、一般的なユースケース向けに構築済みのミドルウェアがすでに提供されているため、必ずしもカスタムロジックを1から構築する必要はありません。構築済みのミドルウェアで要件を満たせる場合は、大幅な開発時間の短縮が期待できます。
- Built-in middleware (構築済みのミドルウェア)
- すでに提供されている機能であれば、とてもシンプルな記述でその機能を使うことができる
- Custom middleware (カスタムミドルウェア)
- 機能や実行タイミングなど、すべての要素を独自に設計・構築可能
プロバイダーに依存しない Built-in middleware 一覧(クリックすると展開されます)
| 名前 | 説明 |
|---|---|
| Summarization | トークン制限に近づくと、会話履歴を自動的に要約 |
| Human-in-the-loop | ツール呼び出しの人間による承認のために実行を一時停止 |
| Model call limit | 過剰なコストを防ぐために、モデル呼び出しの数を制限 |
| Tool call limit | 呼び出し回数を制限してツールの実行を制御 |
| Model fallback | プライマリが失敗した場合は、自動的に代替モデルにフォールバック |
| PII detection | 個人を特定できる情報 (PII) を検出して処理 |
| To-do list | エージェントにタスクの計画および追跡機能を装備 |
| LLM tool selector | メイン モデルを呼び出す前に、LLM を使用して関連するツールを選択 |
| Tool retry | 指数バックオフを使用して、失敗したツール呼び出しを自動的に再試行 |
| Model retry | 指数バックオフを使用して失敗したモデル呼び出しを自動的に再試行 |
| LLM tool emulator | テスト目的で LLM を使用してツールの実行をエミュレート |
| Context editing | ツールの使用をトリミングまたはクリアして、会話のコンテキストを管理 |
| Shell tool | コマンド実行のために永続的なシェル セッションをエージェントに公開 |
| File search | ファイルシステムのファイルに対する Glob および Grep 検索ツールを提供 |
それでは実際に以下 Middleware を実装し、それぞれ評価していきたいと思います!
PII detection(Built-in middleware) : 個人を特定できる情報 (PII) を検出して処理Human-in-the-loop(Built-in middleware) : 特定のツール実行時には承認を挟むようにするcost_tracking(Custom middleware) : 実行毎に利用コストを出力する
参考 : Middleware
検証
本記事ではすでに LangChain を利用している方はもちろん、触ったことがないエンジニアにとってもなんとなくやっていることが理解できるように、極力シンプルなコードを用いて実装を進めていきたいと思います。
※ コードを動かすには環境変数として OPENAI_API_KEY を設定しておく必要があります
※ コードは参考情報として提供されるものであり、実行する際はご自身の責任において実行してください
❯ echo "実行環境" 実行環境 ❯ python --version Python 3.13.7 ❯ python -m pip list | grep -i lang langchain 1.1.0 langchain-core 1.1.0 langchain-openai 1.1.0 langgraph 1.0.4
1. PII detection (Built-in middleware)
この Built-in middleware では会話中の個人識別情報 (PII) を検出し、処理させるという機能を提供しています。
PII 検出は正規表現やカスタム関数を用いて独自実装することも可能ですが、今回は提供されている設定オプションを活用して進めていきます。
| 設定項目 | 検証で使用する値 | その他の選択肢 |
|---|---|---|
| PII タイプ | url | email, credit_card, ip, mac_address |
| 処理方法 | redact | block, mask, hash |
| 処理タイミング | apply_to_input | apply_to_output, apply_to_tool_results |
今回は以下の流れで機能を実装 & 確認してみたいと思います。
- エージェント作成 : エージェント作成時に middleware パラメータにて検出対象の PII タイプと処理方法、処理タイミングを設定する
- 動作確認 : 入力したユーザーメッセージと実際に渡されているメッセージを出力し、PII 情報が適切に処理されていることを確認できるようにする
正しく設定されていると、モデルへの入力に URL が含まれていた場合、自動的に URL が編集されるはずです。全体的な実装は下記コードをご確認いただき、重要なポイントについては追加で解説を入れていきたいと思います。
コード(クリックすると展開されます)
import os
from dotenv import load_dotenv
from langchain.agents import create_agent
from langchain.agents.middleware import PIIMiddleware
load_dotenv()
agent = create_agent(
model="openai:gpt-4o-mini",
tools=[],
system_prompt="あなたは親切で役立つアシスタントです。",
middleware=[
PIIMiddleware("url", strategy="redact", apply_to_input=True),
]
)
user_input = input("メッセージを入力してください : ")
result = agent.invoke({
"messages": [{"role": "user", "content": user_input}]
})
print("\n=== 応答 ===")
print(result['messages'][-1].content)
print(f"\n=== メッセージ履歴 ===")
for i, msg in enumerate(result['messages']):
role = getattr(msg, 'type', 'unknown')
content = getattr(msg, 'content', '')
print(f" [{i}] {role}: {content}")
agent = create_agent(
model="openai:gpt-4o-mini",
tools=[],
system_prompt="あなたは親切で役立つアシスタントです。",
middleware=[
PIIMiddleware("url", strategy="redact", apply_to_input=True),
]
)
まずはこちらも LangChain v1 で追加されました create_agent() を使ってエージェントを作成していきます。モデルは OpenAI の gpt-4o-mini を利用していきます。
今回の目的である PII 検出機能を有効にするために middleware パラメータにて PIIMiddleware を設定し、必要なパラメータを指定するだけで簡単に実装できます。
では実際にファイルを実行してメッセージのやり取りを確認してみましょう。
メッセージを入力してください : このサイトを見てください: https://example.com === 応答 === 申し訳ありませんが、具体的なウェブサイトを確認することはできません。ただし、サイトの内容や質問について説明していただければ、その情報をもとにお手伝いできるかもしれません。何か具体的なことを教えていただけますか? === メッセージ履歴 === [0] human: このサイトを見てください: [REDACTED_URL] [1] ai: 申し訳ありませんが、具体的なウェブサイトを確認することはできません。ただし、サイトの内容や質問について説明していただければ、その情報をもとにお手伝いできるかもしれません。何か具体的なことを教えていただけますか?
入力したユーザーメッセージの中には https://example.com という URL が含まれていましたが、メッセージ履歴では [REDACTED_TYPE] に置き換えられています。
つまり、設定した通り apply_to_input (モデルが呼ばれる前) のタイミングでユーザーメッセージに含まれている URL を検知して redact 処理行ったことが確認できました。
とてもシンプルな記述で PII 処理を実装できました!
カスタマイズすればより高度な処理が行えますので、プロンプトインジェクションや機密情報マスキングなどの LLM ガードレールとして活用できる Middleware であることがわかりました。
2. Human-in-the-loop (Built-in middleware)
この Built-in middleware では指定のツール実行前に処理を中断させ、人間の承認を挟むという機能を提供しています。
以下流れで機能を実装 & 確認してみたいと思います。
- エージェント作成 : 簡易的なツールの作成を行い、エージェントを作成時にツールの登録を行う。また middleware パラメータにてツールごとに承認設定を行う
- ツール実行監視 : エージェントが承認が必要なツールを実行した場合、それをキャッチできるようにする
- 承認プロセス : 承認プロセスとしてユーザーに入力を求め、入力内容に基づいてエージェントの状態を制御して再実行させる
- 動作確認 : ツールごとに設定した承認機能が正しく動作していることを確認する
全体的な実装は下記コードをご確認いただき、重要なポイントについては追加で解説を入れていきたいと思います。
コード(クリックすると展開されます)
import os
from dotenv import load_dotenv
from langchain.agents import create_agent
from langchain.agents.middleware import HumanInTheLoopMiddleware
from langchain_core.tools import tool
from langgraph.checkpoint.memory import InMemorySaver
from langgraph.types import Command
load_dotenv()
@tool
def send_email(to: str, subject: str, body: str) -> str:
"""メールを送信します"""
return f"メール送信完了:\n 宛先: {to}\n 件名: {subject}\n 本文: {body}"
@tool
def search_web(query: str) -> str:
"""web 検索をします"""
return f"検索結果: '{query}' についての情報を見つけました"
agent = create_agent(
model="openai:gpt-4o-mini",
tools=[send_email, search_web],
system_prompt="あなたは親切で役立つアシスタントです。",
checkpointer=InMemorySaver(),
middleware=[
HumanInTheLoopMiddleware(
interrupt_on={
"send_email": {
"allowed_decisions": ["approve", "reject"]
},
"search_web": False,
}
),
]
)
thread_id = "techorus-demo"
user_input = input("メッセージを入力してください: ")
config = {"configurable": {"thread_id": thread_id}}
result = agent.invoke({
"messages": [{"role": "user", "content": user_input}]
}, config)
while result.get("__interrupt__"):
interrupts = result["__interrupt__"]
print("\n=== ツール実行の承認が必要です ===")
for interrupt in interrupts:
action_requests = interrupt.value.get('action_requests', [])
for action in action_requests:
print(f"\nツール: {action['name']}")
print(f"引数: {action['args']}")
decision = input("\n承認しますか? (approve/reject): ").strip().lower()
if decision == "approve":
result = agent.invoke(
Command(
resume={"decisions": [{"type": "approve", "message": "ユーザーが許可しました"}]}),
config
)
elif decision == "reject":
result = agent.invoke(
Command(
resume={"decisions": [{"type": "reject", "message": "ユーザーが拒否しました"}]}),
config
)
else:
print("無効な入力です。approve または reject を入力してください。")
continue
print("\n=== 応答 ===")
print(result['messages'][-1].content)
agent = create_agent(
model="openai:gpt-4o-mini",
tools=[send_email, search_web],
system_prompt="あなたは親切で役立つアシスタントです。",
checkpointer=InMemorySaver(),
middleware=[
HumanInTheLoopMiddleware(
interrupt_on={
"send_email": {
"allowed_decisions": ["approve", "reject"]
},
"search_web": False,
}
),
]
)
まずは send_email, search_web という簡易的なツールを用意し、create_agent() にてツールを登録しています。次に Human-in-the-loop を利用するにはエージェントの状態を保存できるようにする必要があるため、checkpointer として InMemorySaver() を利用してきます。
最後に middleware パラメータにて send_email ツールを実行するときは承認を求めるように、search_web ツールは承認なしで実行できるように設定します。
while result.get("__interrupt__"):
interrupts = result["__interrupt__"]
print("\n=== ツール実行の承認が必要です ===")
for interrupt in interrupts:
action_requests = interrupt.value.get('action_requests', [])
for action in action_requests:
print(f"\nツール: {action['name']}")
print(f"引数: {action['args']}")
decision = input("\n承認しますか? (approve/reject): ").strip().lower()
if decision == "approve":
result = agent.invoke(
Command(
resume={"decisions": [{"type": "approve", "message": "ユーザーが許可しました"}]}),
config
)
elif decision == "reject":
result = agent.invoke(
Command(
resume={"decisions": [{"type": "reject", "message": "ユーザーが拒否しました"}]}),
config
)
else:
print("無効な入力です。approve または reject を入力してください。")
continue
send_email ツールが実行されたとき処理が中断され result["__interrupt__"] プロパティが生成されるので、それを検知できるようにしてユーザーの承認プロセスを差し込みます。
承認プロセスではユーザーの入力に応じて Command オブジェクトでエージェントの状態を制御しながら agent.invoke() で処理を再開するようにしています。
では実際にツールを呼び出してみて、動作を確認してみましょう。
メッセージを入力してください: テコラスについて web 検索を実行してください === 応答 === テコラスについての情報が見つかりましたが、具体的な内容はどのようなものをお探しでしょうか?詳細なテーマや質問があれば教えてください。 === メッセージ履歴 === [0] human: テコラスについて web 検索を実行してください [1] ai: [2] tool: 検索結果: 'テコラス' についての情報を見つけました [3] ai: テコラスについての情報が見つかりましたが、具体的な内容はどのようなものをお探しでしょうか?詳細なテーマや質問があれば教えてください。
search_web ツールを実行しているときは承認プロセスなく実行できていることがわかりますね。
メッセージを入力してください: Dr.K に "緊急" という件名で、"ブログを書きなさい" というメールを送信してください
=== ツール実行の承認が必要です ===
ツール: send_email
引数: {'to': 'Dr.K', 'subject': '緊急', 'body': 'ブログを書きなさい'}
承認しますか? (approve/reject): reject
=== 応答 ===
メールの送信に関して何か問題が発生しました。別のメールアドレスを指定するか、メールの内容を変更したい場合はお知らせください。
=== メッセージ履歴 ===
[0] human: Dr.K "緊急" という件名で、"ブログを書きなさい" というメールを送信してください
[1] ai:
[2] tool: ユーザーが拒否しました
[3] ai: メールの送信に関して何か問題が発生しました。別のメールアドレスを指定するか、メールの内容を変更したい場合はお知らせください。
send_email ツールを実行したときは、承認が求められていることがわかります。承認に対して reject と入力すると、メッセージ履歴からツールが正しい結果を返していないことがわかります。
ここでは省略しますが、承認に対して approve と入力すると、ツールが正常に実行され正しい結果を返します。
Human-in-the-loop を使えば、ツールごとの承認機能を簡単に実装することができることがわかりました。
「いつ中断させるのか・実行させるのか」 のみを提供している Built-in middleware であるため、承認フローや UI を自由にカスタマイズして実装することができそうです。
ツール実行を確実にコントロールしたい様々なシチュエーションで利用できる Middleware であることがわかりました。
3. cost_tracking (Custom middleware)
最後に cost_tracking という名前で実行毎に利用コストを出力する Custom middleware を作成してみたいと思います。
以下の流れで機能を実装していきます。
- エージェント作成 : エージェント作成時に middleware パラメータにて、カスタムで作成する cost_tracking を設定する
- ミドルウェア作成 : エージェントの state からトークン使用量情報を取得する cost_tracking を作成する
- 動作確認 : 実行時に、コストがわかりやすい形で出力されることを確認する
全体的な実装は下記コードをご確認いただき、重要なポイントについては追加で解説を入れていきます!
コード(クリックすると展開されます)
import os
from dotenv import load_dotenv
from langchain.agents import create_agent
from langchain.agents.middleware import after_agent, AgentState
from langgraph.runtime import Runtime
from typing import Any
load_dotenv()
MODEL_PRICES = {
"gpt-4o-mini": {
"input": 0.15,
"output": 0.60,
}
}
@after_agent
def cost_tracking(
state: AgentState,
runtime: Runtime
) -> dict[str, Any] | None:
usage = None
messages = state.get("messages", [])
if messages:
last_message = messages[-1]
if hasattr(last_message, 'usage_metadata'):
usage = last_message.usage_metadata
if usage:
input_tokens = usage.get('input_tokens', 0)
output_tokens = usage.get('output_tokens', 0)
total_tokens = usage.get('total_tokens', 0)
prices = MODEL_PRICES.get("gpt-4o-mini")
input_cost = (input_tokens / 1_000_000) * prices["input"]
output_cost = (output_tokens / 1_000_000) * prices["output"]
call_cost = input_cost + output_cost
print("\n" + "="*50)
print(" LLM 呼び出しコスト")
print("="*50)
print(f"モデル → gpt-4o-mini")
print(f"入力トークン → {input_tokens:,}")
print(f"出力トークン → {output_tokens:,}")
print(f"合計トークン → {total_tokens:,}")
print(f"コスト → ${call_cost:.6f} (約{call_cost * 150:.4f}円)")
print("="*50 + "\n")
return None
agent = create_agent(
model="openai:gpt-4o-mini",
system_prompt="あなたは親切で役立つアシスタントです。",
middleware=[
cost_tracking,
]
)
user_input = input("メッセージを入力してください: ")
result = agent.invoke({
"messages": [{"role": "user", "content": user_input}]
})
print("\n=== 応答 ===")
print(result['messages'][-1].content)
agent = create_agent(
model="openai:gpt-4o-mini",
tools=[send_email, search_web],
system_prompt="あなたは親切で役立つアシスタントです。",
middleware=[
cost_tracking,
]
)
create_agent() 時に今回作成する cost_tracking を設定しておきます。
ここまでは Built-in middleware と同じです。
@after_agent
def cost_tracking(
state: AgentState,
runtime: Runtime
) -> dict[str, Any] | None:
usage = None
messages = state.get("messages", [])
if messages:
last_message = messages[-1]
if hasattr(last_message, 'usage_metadata'):
usage = last_message.usage_metadata
⋮
次に cost_tracking を実装していきます。なるべくシンプルな記述にしたいので、ノードスタイルフックかつデコレータベースで Middleware を構築していきます。
エージェントが終了するタイミング (@after_agent) で state からトークン情報を取得するようにしており、トークンあたりのコストを用いて人間のわかりやすい単位 ($) に変換してから出力するようにします。
では正しくコストが出力されるのか、実行して確認してみましょう。
メッセージを入力してください: AWS リセールとはなにか、100文字以内で教えてください ================================================== LLM 呼び出しコスト ================================================== モデル → gpt-4o-mini 入力トークン → 29 出力トークン → 105 合計トークン → 134 コスト → $0.000067 (約0.0101円) ================================================== === 応答 === AWSリセールとは、Amazon Web Services(AWS)のサービスを再販するビジネスモデルで、パートナーや代理店が自社の顧客にAWSサービスを提供し、付加価値を加える形態です。
LLM 呼び出しコストが出力されていることが確認できました!
フックスタイルやフックタイミング、記述方式などを適切に選択することで、用途に合わせた Middleware を適切な形でカスタム実装できることがわかりました。
次はクラスベースやラップスタイルフックでより複雑な Middleware も作成してみたいですね!
検証結果・評価
- Built-in middleware
- 当てはまるユースケースであれば短い開発期間かつ非常にシンプルなコードで機能を実現できる
- LangChain v1.1.0 では追加の Built-in middleware が提供されており、これからも一般的なユースケース向けの Built-in middleware が追加されていくことが予想される
- Custom middleware
- フックと記述方法を使い分けることで、シンプルなコードを保ちながらカスタム処理をエージェントループに追加することができた
- どこまで Custom middleware で実装し、どこから LangGraph を使うとよいのか、考える必要がありそう
今回、エージェント開発において PII 処理やツールの実行承認機能、コスト追跡機能を Middleware を活用して実装してみました。これらの機能はもちろん Middleware を利用しなくても実装することができますが Middleware を利用することで以下のメリットを実感することができました。
- 保守性の向上
- コードの可読性が失われない
- 各機能を適切に分離することができ、責任範囲が明確
- 開発効率の向上
- Built-in middleware の活用により、数行で実装可能
- 既存のベストプラクティスを簡単に適用
- 運用面での利点
- デバッグやモニタリングが容易
- 機能の追加・削除が柔軟に対応可能
これらのメリットは本番環境での運用において非常に重要な要素であり、Middleware を採用する価値は高いといえるのではないでしょうか。
まとめ
今回は LangChain v1.0 で利用可能になった Middleware について検証してみました。
Google や Anthropic、OpenAI、さらにはオープンソース LLM まで、各プロバイダーが相次いで新モデルをリリースしており、LLM アプリケーション開発の技術環境は目まぐるしく変化し続けています。
また、複数の LLM エージェントが協調して問題解決にあたるマルチエージェントや、メインエージェントが特定のタスクを専門エージェントに委譲するサブエージェントなど、エージェント間連携による高度な推論システムという文脈も盛り上がっていると感じます。
こうした技術的変遷の中で、オープンソースでありベンダーロックインを回避できる柔軟なフレームワークの重要性がより高まってくると考えています。そして、その有力な選択肢として LangChain は検討に値する優れたフレームワークであると今回の検証を通して改めて実感しました。
本記事が LLM アプリケーション開発/フレームワーク選定の一助となれば幸いです。
最後までお読みいただきありがとうございました。また次の記事でお会いしましょう。
NHN テコラスの採用情報はこちら


2023年度新卒入社。DevOpsエンジニア。


Recommends
こちらもおすすめ
-

Amazon Bedrock 経由で Claude Code を利用するまで
2026.3.18




Special Topics
注目記事はこちら

データ分析入門
これから始めるBigQuery基礎知識
2024.02.28

AWSの料金が 10 %割引になる!
『AWSの請求代行リセールサービス』
2024.07.16