Snowflake ストレージ統合で Amazon S3 のデータをロードする
2026.1.21

概要
Snowflake では、ETL ツールを使用しなくても「ストレージ統合(Storage Integration)」機能を使用することで、Amazon S3 などの外部ストレージにあるデータを直接ロードすることが可能です。
今回は、Snowflake の機能だけで完結するこのデータロード方法を実際に試してみました。
構成のイメージ
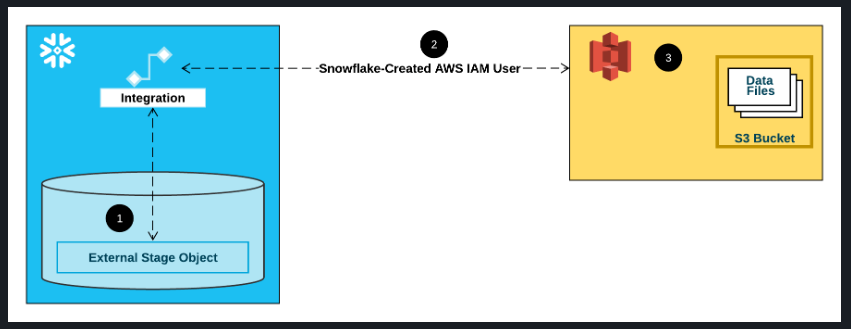
オプション 1: Amazon S3 にアクセスするための Snowflake ストレージ統合の構成 | Snowflake Documentation
検証の流れ
以下のステップで進めていきます。
- S3 バケットの作成および転送データの準備
- AWS IAM ロールの作成
- Snowflake ストレージ統合を作成
- AWS IAM ポリシーの修正(外部 ID の設定)
- Snowflake ステージを使ったデータロード
Snowflake アカウントについては、無料トライアルを使用しています。
Snowflake Trial
1. S3 バケットの作成 & 転送データの準備
まずはロード対象となるデータを S3 に用意します。
今回は生成 AI を活用してダミーの CSV データ(注文データ等)を作成し、S3 バケット内のフォルダに格納しました。
ダミーデータ
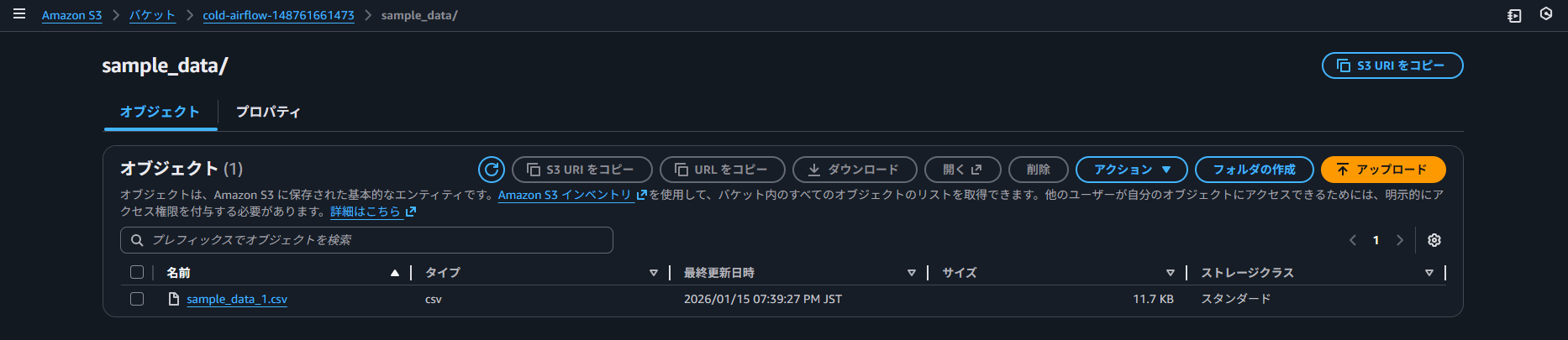
CSV ファイルを S3 バケットに格納
2. AWS IAM ロールの作成
Snowflake が管理する AWS 環境(Snowflake アカウント)から、自分の AWS 環境(S3)へアクセスすることを許可するため、IAM ロールを作成します。
この認証には「外部 ID」を使用しますが、この段階では Snowflake 側で外部 ID が発行されていないため、仮の値で作成を進めます。
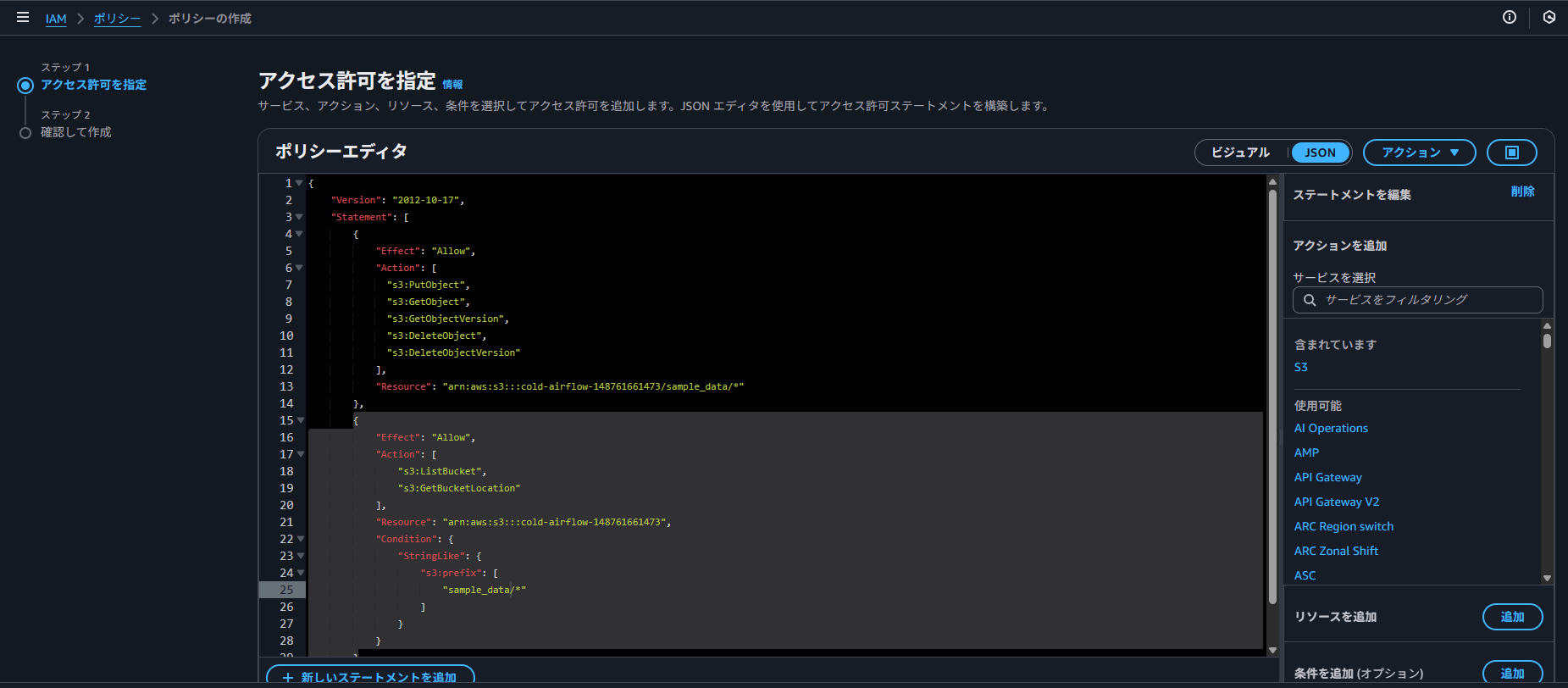
IAM ポリシーの作成
S3 へのアクセス権限を持つ IAM ポリシーを作成します。
ドキュメントのサンプルを参考に、以下のような JSON でポリシーを定義しました。
<bucket> や <prefix> の部分は、実際の環境に合わせて書き換えてください。
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": [
"s3:PutObject",
"s3:GetObject",
"s3:GetObjectVersion",
"s3:DeleteObject",
"s3:DeleteObjectVersion"
],
"Resource": "arn:aws:s3:::<bucket>/<prefix>/*"
},
{
"Effect": "Allow",
"Action": ["s3:ListBucket", "s3:GetBucketLocation"],
"Resource": "arn:aws:s3:::<bucket>",
"Condition": {
"StringLike": {
"s3:prefix": ["<prefix>/*"]
}
}
}
]
}
IAM ロールの作成
次に、作成したポリシーをアタッチする IAM ロールを作成します。
信頼されたエンティティとして「AWS アカウント」を選択し、自分の AWS アカウント ID を指定します。
この際、「外部 ID」の入力を求められますが、前述の通り後ほど正しい値に書き換えるため、ここでは適当な値(仮置き)で問題ありません。
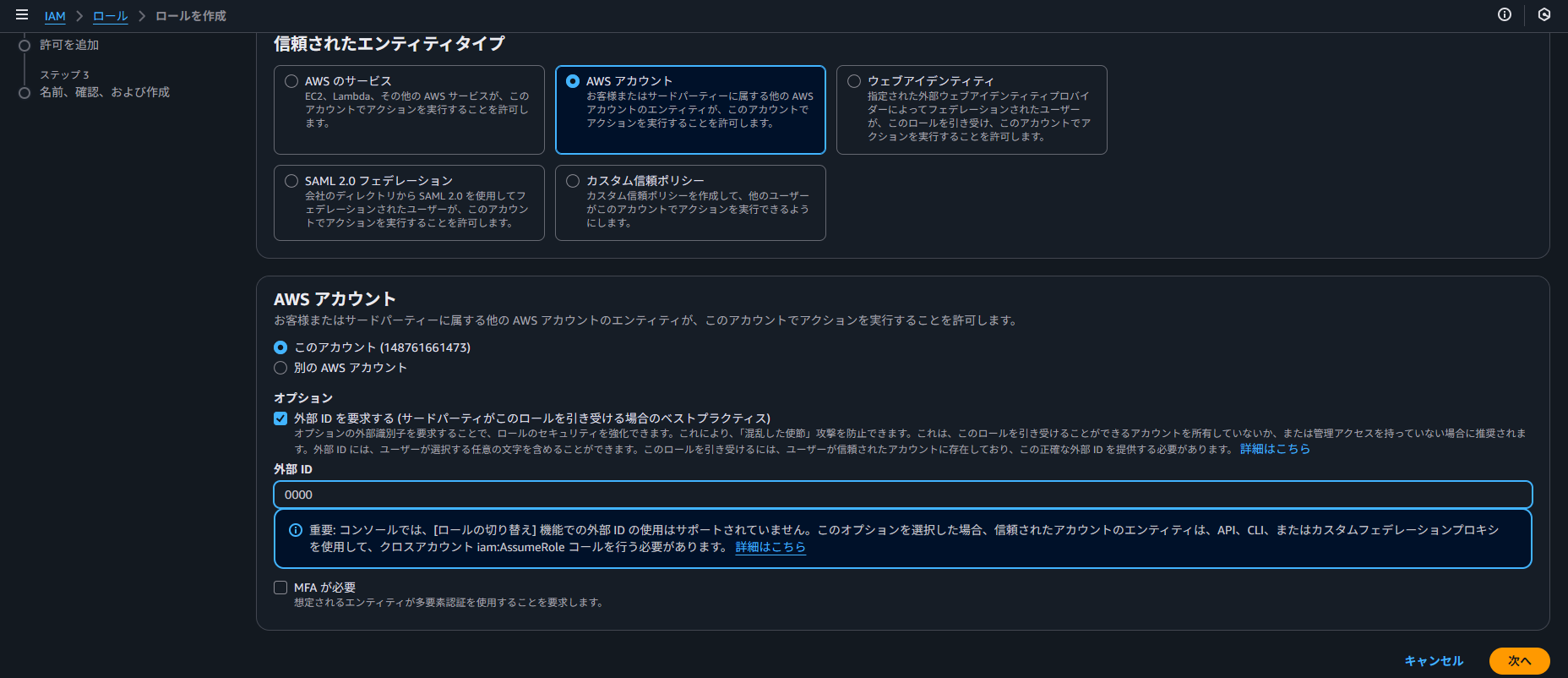
ポリシーは、先程作成した IAM ポリシーを設定します。
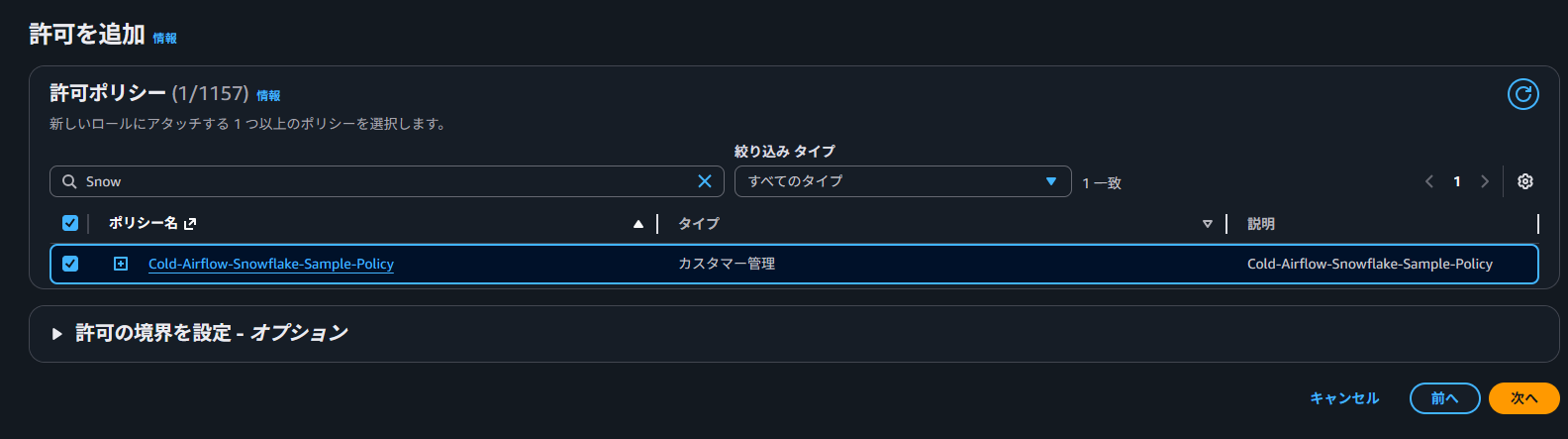
ロールが作成できたら、ロール ARN を控えておきます。
arn:aws:iam::123456789012:role/Snowflake-S3-Integration-Role
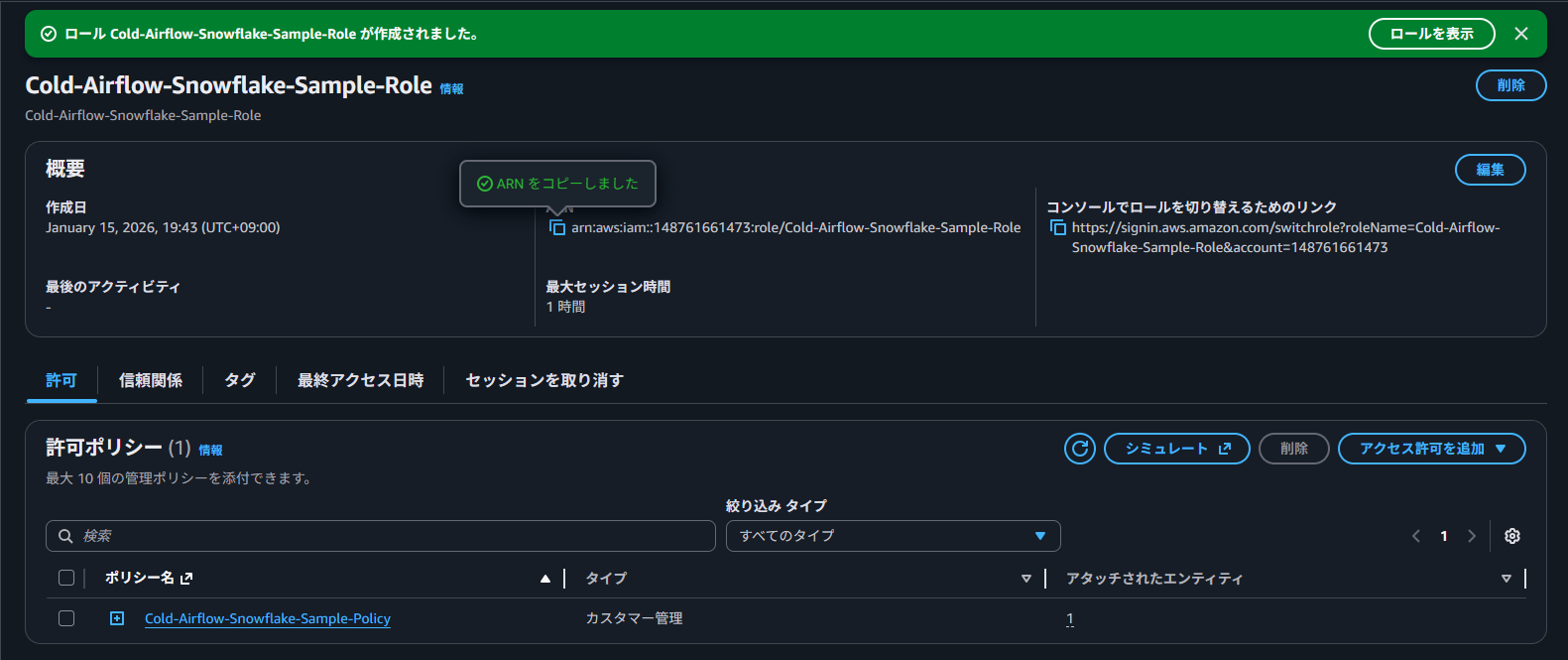
3. Snowflake ストレージ統合を作成
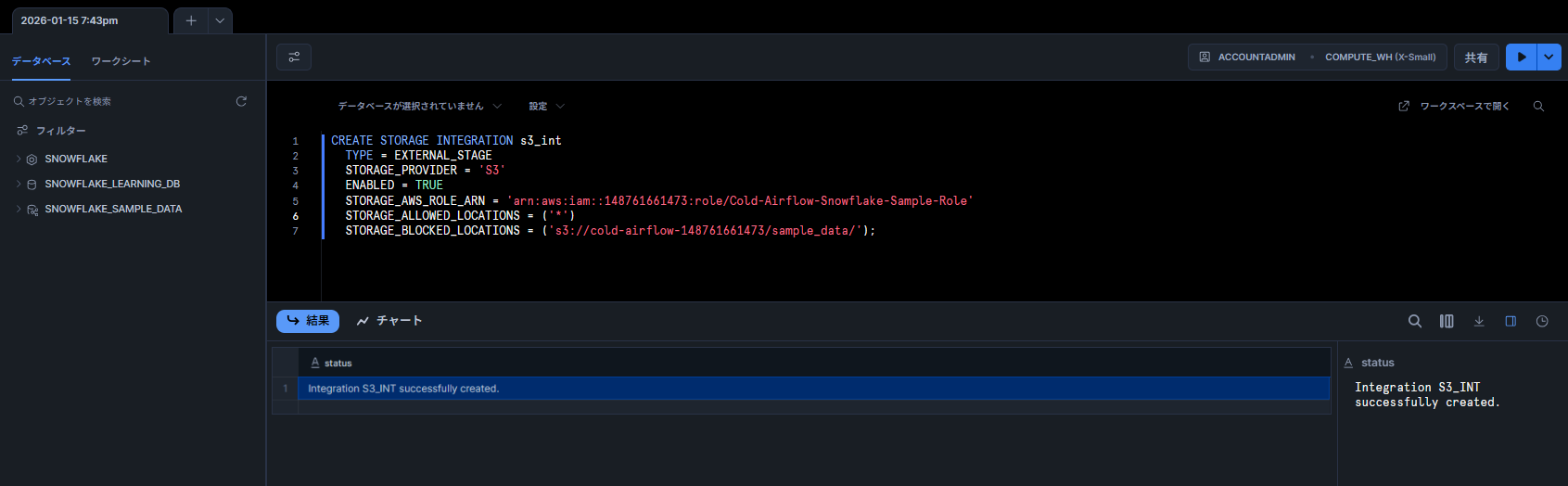
ここからは Snowflake 側での作業です。
CREATE STORAGE INTEGRATION コマンドを使用して、ストレージ統合オブジェクトを作成します。
※ 事前にデータベース(mydb 等)を作成しておきます。
CREATE DATABASE mydb;
CREATE or replace STORAGE INTEGRATION s3_int
TYPE = EXTERNAL_STAGE
STORAGE_PROVIDER = 'S3'
ENABLED = TRUE
STORAGE_AWS_ROLE_ARN = 'arn:aws:iam::123456789012:role/Snowflake-S3-Integration-Role' -- 先ほど作成したIAMロールARN
STORAGE_ALLOWED_LOCATIONS = ('*') -- または特定のパス ('s3://my-bucket/data/')
-- STORAGE_BLOCKED_LOCATIONS = ('...') -- 必要に応じて設定
;
IAM 連携に必要な情報の取得
作成したストレージ統合オブジェクトから、IAM ポリシーの修正に必要な情報を取得します。
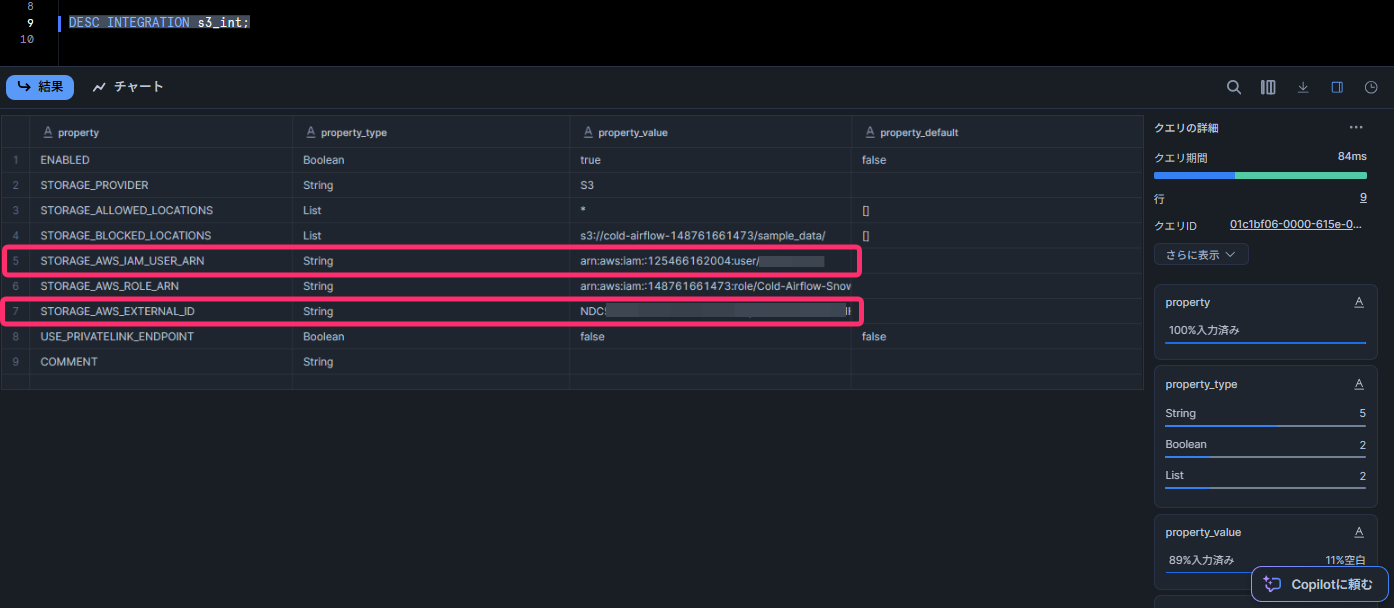
DESC INTEGRATION s3_int;
実行結果の中から、以下の 2 つの値を控えます。
- STORAGE_AWS_IAM_USER_ARN: Snowflake 側の IAM ユーザー ARN
- STORAGE_AWS_EXTERNAL_ID: Snowflake 側で発行された外部 ID
検証中に一度、ストレージ統合の設定(STORAGE_BLOCKED_LOCATIONS)を間違えてしまい、CREATE OR REPLACE STORAGE INTEGRATION コマンドで作り直しを行いました。
すると、AWS 側の設定は変えていないにも関わらず、認証エラー(S3 へのアクセス拒否)が発生するようになりました。
ストレージ統合オブジェクトを再作成(REPLACE)したところ、STORAGE_AWS_EXTERNAL_ID(外部 ID)等の値が新しく再生成されました。
そのため、Snowflake 側でオブジェクトを作り直した場合は、必ず DESC INTEGRATION で新しい外部 ID を確認し、AWS IAM ロールの信頼ポリシーを更新する必要がありそうです。
設定変更時はご注意ください。
4. AWS IAM ポリシー 外部 ID 修正
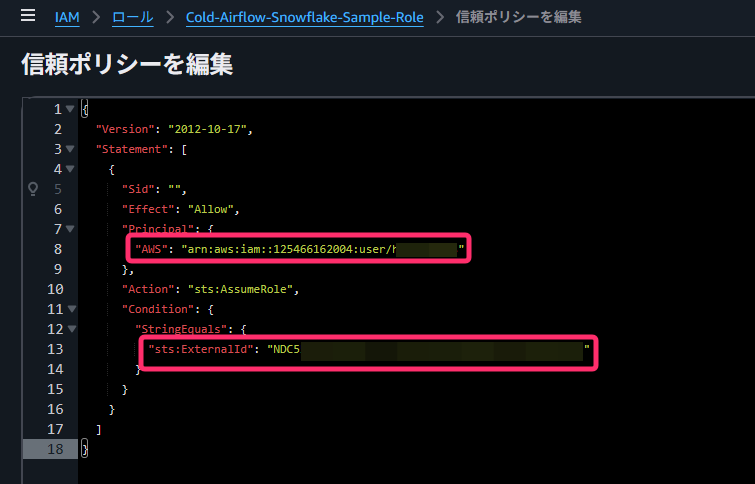
AWS コンソールに戻り、先ほど作成した IAM ロールの「信頼関係」タブから、信頼ポリシーを編集します。
Snowflake から取得した値を使って、Principal と sts:ExternalId を更新します。
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "",
"Effect": "Allow",
"Principal": {
"AWS": "<STORAGE_AWS_IAM_USER_ARNの値>"
},
"Action": "sts:AssumeRole",
"Condition": {
"StringEquals": {
"sts:ExternalId": "<STORAGE_AWS_EXTERNAL_IDの値>"
}
}
}
]
}
これで、Snowflake から S3 へのアクセス権限設定は完了です。
5. Snowflake ステージを使ったデータロード
準備が整ったので、実際にデータをロードしてみます。
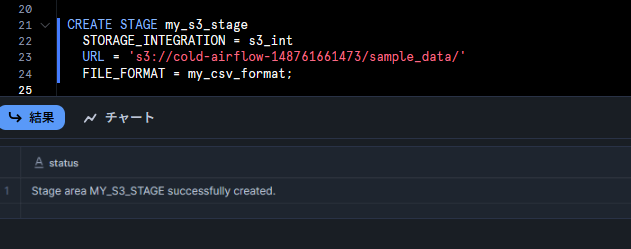
外部ステージとファイルフォーマットの作成
ロードする CSV ファイルの形式を定義し、S3 を参照する外部ステージを作成します。
-- ファイルフォーマットの作成 CREATE OR REPLACE FILE FORMAT my_csv_format TYPE = 'CSV', FIELD_DELIMITER = ',', SKIP_HEADER = 1; -- 外部ステージの作成 CREATE STAGE my_s3_stage STORAGE_INTEGRATION = s3_int URL = 's3://my-bucket/sample_data/' FILE_FORMAT = my_csv_format;
ステージが正しく作成されているか、ファイル一覧を表示して確認します。
LIST @my_s3_stage;

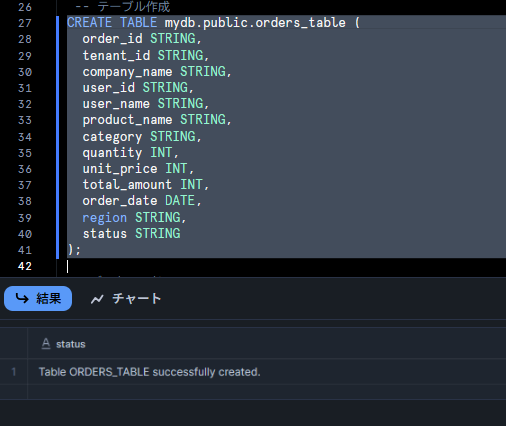
テーブルへのデータロード
データの受け皿となるテーブルを作成し、COPY INTO コマンドでデータをロードします。
-- テーブル作成
CREATE TABLE mydb.public.orders_table (
order_id STRING,
tenant_id STRING,
company_name STRING,
user_id STRING,
user_name STRING,
product_name STRING,
category STRING,
quantity INT,
unit_price INT,
total_amount INT,
order_date DATE,
region STRING,
status STRING
);
-- データロード COPY INTO mydb.public.orders_table FROM @my_s3_stage PATTERN='sample_data_1.csv' FILE_FORMAT = my_csv_format;
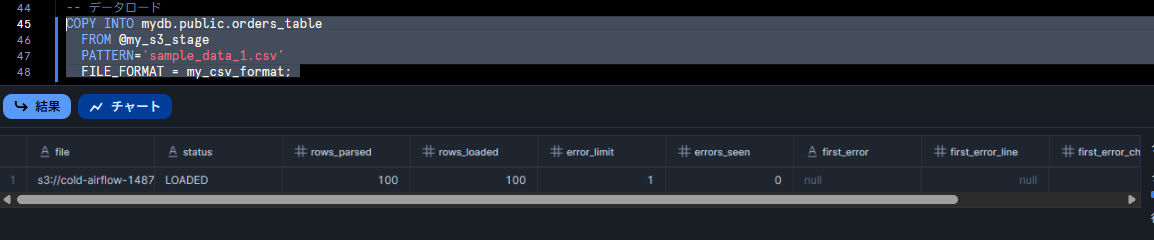
ロードが成功したら、データを SELECT して確認します。
SELECT * FROM orders_table;
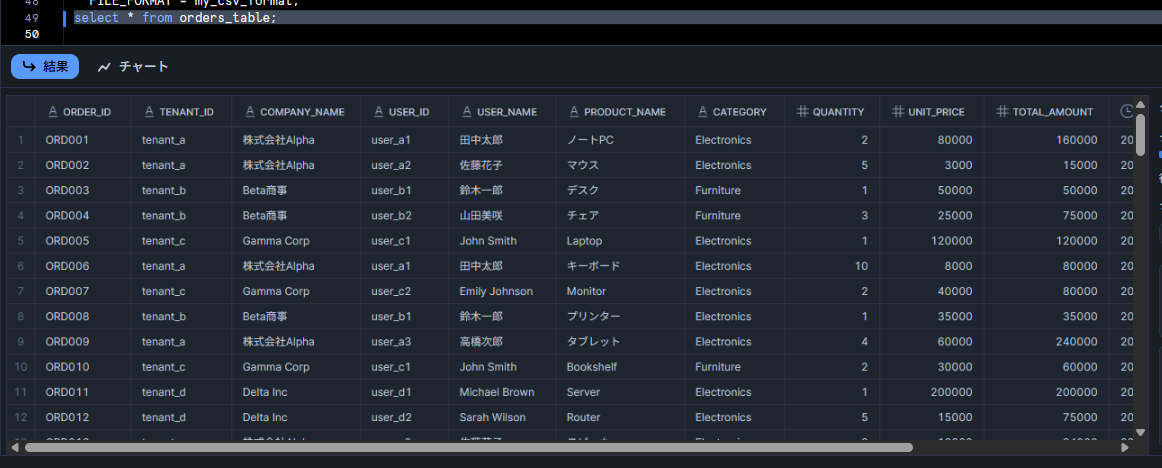
無事に S3 上の CSV データを Snowflake のテーブルにロードすることができました。
まとめ
ETL ツールなどを挟まずに、Snowflake の SQL だけで S3 と連携できるのは非常に便利です。
一度設定してしまえば、あとは SQL ベースでデータのロード・アンロードが自由に行えるため、データ基盤の構築における選択肢の一つとして有用だと感じました。
参考
オプション 1: Amazon S3 にアクセスするための Snowflake ストレージ統合の構成 | Snowflake Documentation
クラウドストレージからデータをロードする: Amazon S3 | Snowflake Documentation
第三者が所有する AWS アカウント へのアクセス – AWS Identity and Access Management
NHN テコラスの採用情報はこちら


2021年新卒入社。インフラエンジニアです。RDBが三度の飯より好きです。 主にデータベースやAWSのサーバレスについて書く予定です。あと寒いのは苦手です。


Recommends
こちらもおすすめ
-

Amazon S3のデータをAmazon Auroraにインポートする
2023.9.28
-

ETL ツール TROCCO で始める AWS コスト分析ダッシュボード構築
2025.9.25
-
TROCCO のデータマート機能で実現する AWS コスト分析の月次比較ダッシュボード
2025.11.26



Special Topics
注目記事はこちら

データ分析入門
これから始めるBigQuery基礎知識
2024.02.28

AWSの料金が 10 %割引になる!
『AWSの請求代行リセールサービス』
2024.07.16