QuickSightとAthenaを活用!データ分析入門


こんにちは。データサイエンスチームのhongsです。
この記事は、DataScience Advent Calendarの11日目の記事です。
この記事では、AWS S3のデータをAthenaとQuickSightを活用して分析する方法について紹介したいと思います。
AWS上のシステム構成及びデータの流れは下記の図のようになります。
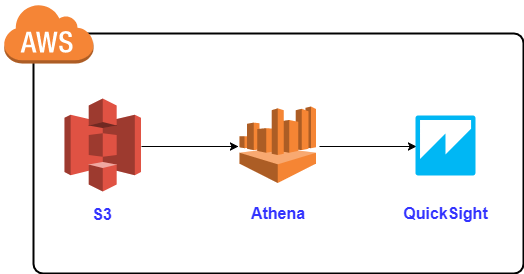
今回、紹介するAthenaはS3のデータに対して標準SQLで分析が出来るサービスです。
Athenaはサーバーレスなのでサーバーの構築や管理が不要です。
metadata管理も不要かと疑問に思うかもしれませんが、それもAthenaがやってくれます。
Athenaの詳細についてはAthena公式ページをご参照ください。
そして、QuickSightはAWSが提供しているBIサービスです。
データの可視化はもちろんアドホックな分析などで活用できます。
QuickSightの詳細についてはQuickSight公式ページをご参照ください。
では、S3データ確認、Athena設定、QuickSight設定の順で見て行きましょう。
S3データ確認
今回の例で使うのは日本のある市役所職員の3年間(2013~2015)のオープン給与データ(csvファイル形式)です。
元データから一部不要なデータを除外した形でS3に保存しています。
- バケット名
advent-techblog
- ファイル名
emp_salary/dt=2013/h25_salary.csv
emp_salary/dt=2014/h26_salary.csv
emp_salary/dt=2015/h27_salary.csv
Browserで確認すると下記のように見えます。
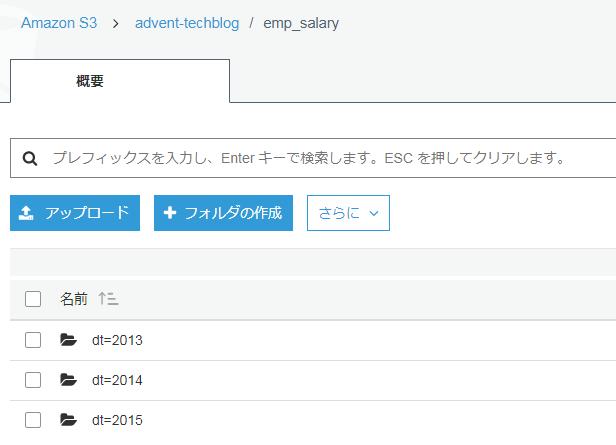
各folderの中にはcsvファイルが保存されています。
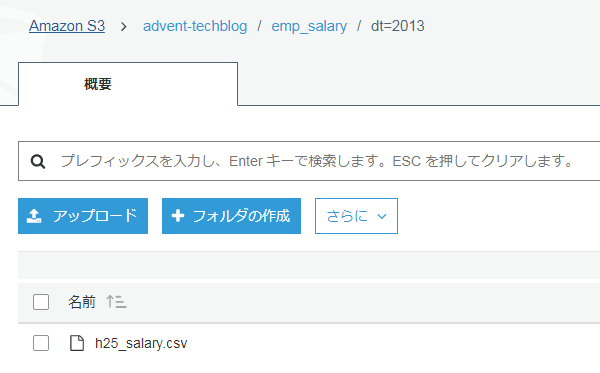
csvファイルには職員一人ひとりに対する年間人件費情報が記録されています。

ファイルはAthenaのSQLパフォーマンスを考え、年単位でPartition化しています。
PartitionについてはPartitioning DataとAthenaパフォーマンスをご参照ください。
それでは、このS3のデータをAthenaで扱えるように設定する方法を説明します。
Athena設定
AWSメニュー画面でAthenaを選択します。
そして、regionをバージニア北部に設定します。
※後で説明するQuickSightですが、まだ日本regionでは利用出来ないためバージニア北部を使います。
QuickSightは違うregionのAthenaは参照出来ないためAthenaもバージニア北部に設定する必要があります。

Athenaの初期画面です。ここでCreate TableをクリックしてDBやTableを作成することが出来ます。
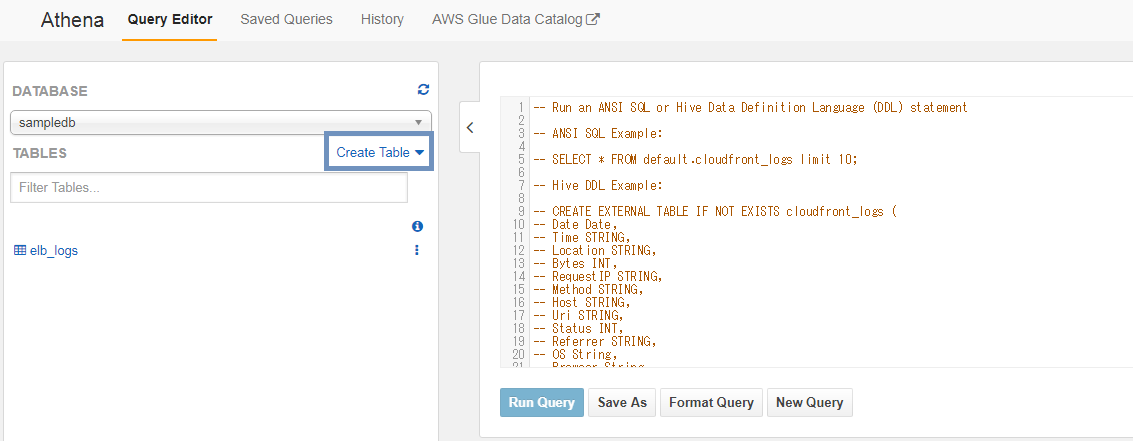
実際Create TableをクリックするとDB、Table、Data Formatなどの設定が出来るWizard画面が表示されます。
DB及びTableの作成はこのWizardを使う方法と直接にSQLで作成する方法の2パターンがありますが
ここではSQLを使って作成してみたいと思います。

では、Create文を使ってDBを作成します。(DB名:tech_blog)
つづいて、Tableを作成します。(Table名:emp_salary)
create文で使うパラメータ詳細についてはこちらをご参照ください。
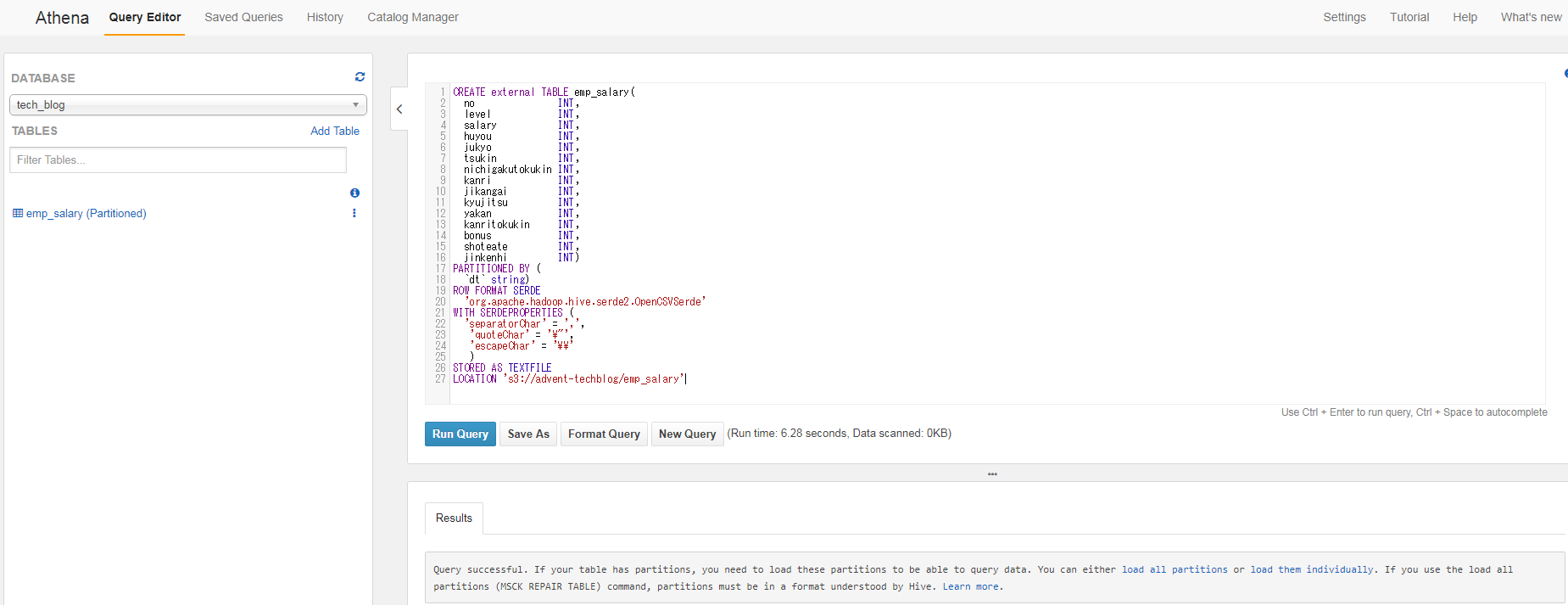
Table作成は正常に終わりましたが、Partition化されているTableの場合はMSCK REPAIR TABLEコマンドでPartition情報をロードする必要があります。
Table作成が完了した際のResultsメッセージにも書かれていますが、AthenaとしてはTableを作成しただけではPartitionの情報を認識出来ません。
そのため、実際の運用ではPartitionが追加されたら、そのPartition情報をロードする作業が発生します。
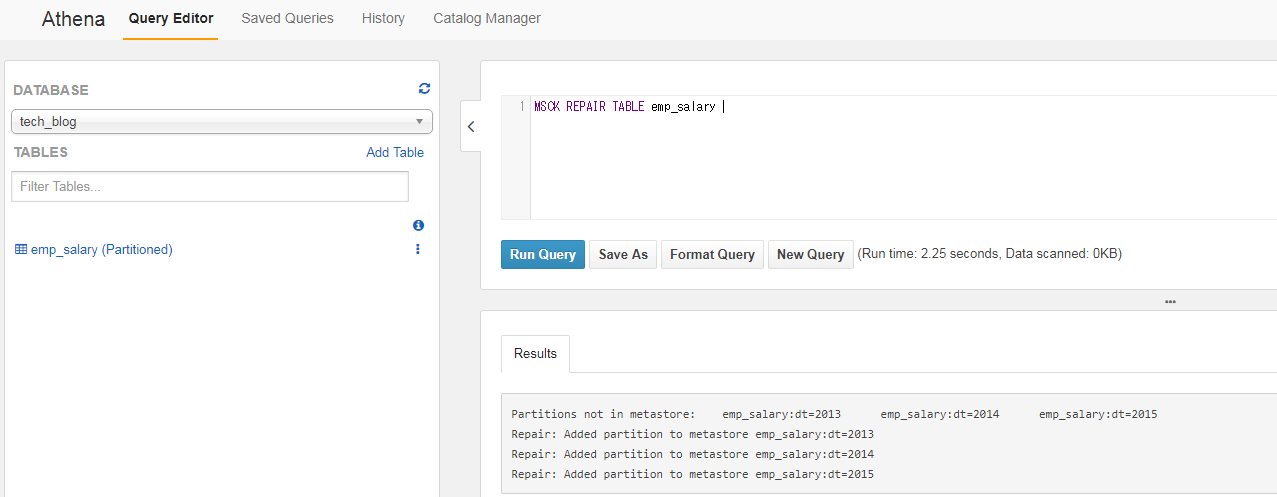
これでAthenaの設定は完了です。では、Select文でデータを確認してみましょう。
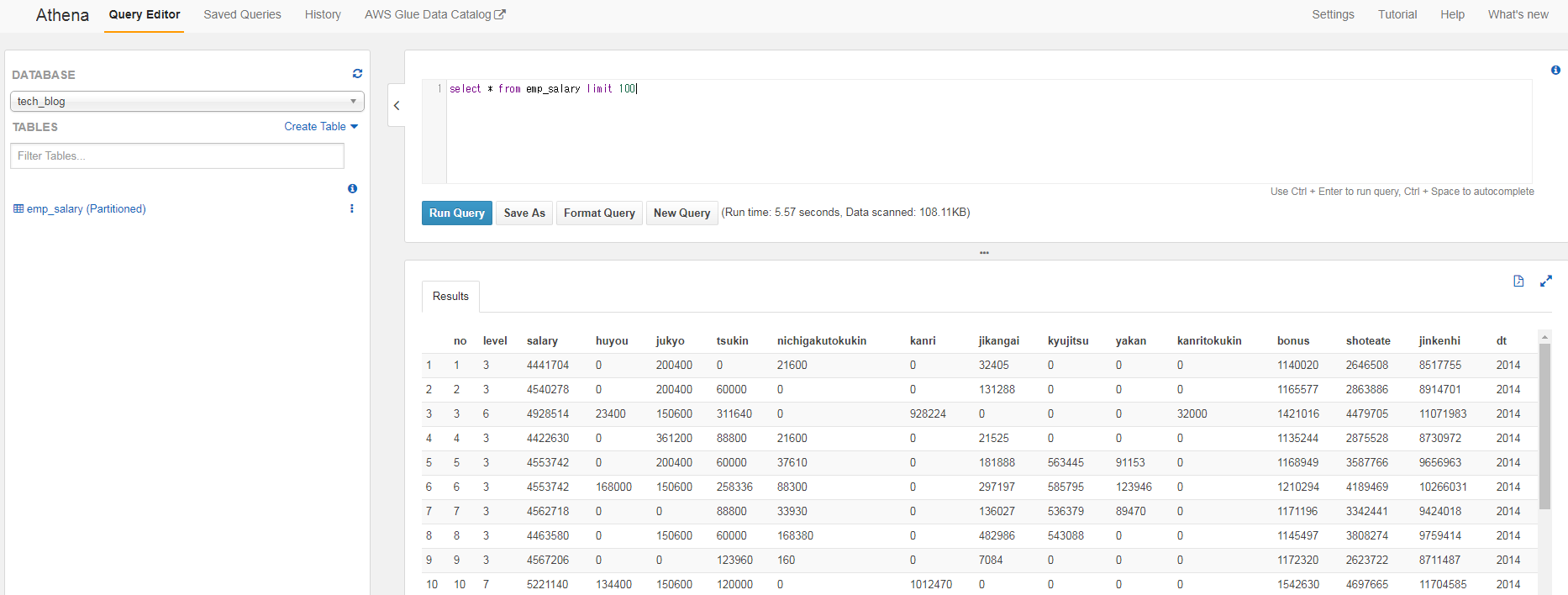
Select文でデータの中身が正常に確認出来ました。では、簡単な集計クエリを実行してみましょう。
この例では日付(年)、職員レベル別の平均残業代を集計し、残業代が高い順に表示してみました。
ここまでAthenaの設定、SQLを使いデータ分析が出来ることを確認しました。
では、つづいてQuickSightでデータを可視化してみましょう。

QuickSight設定
AWSメニュー画面でQuickSightを選択します。

Accountを作成する画面が表示されます。
ここではStandard editionを選択します。今現在60日間無料で使えます。(60日以降は課金されますのでご注意を)

つづいて、account name、email address、region、Athenaへのアクセス許可、使用するS3 bucketなどを設定します。
regionに関してはQuickSightがまだ東京regionをサポートしていないためここではUS East(N. Virginia)を選択しています。
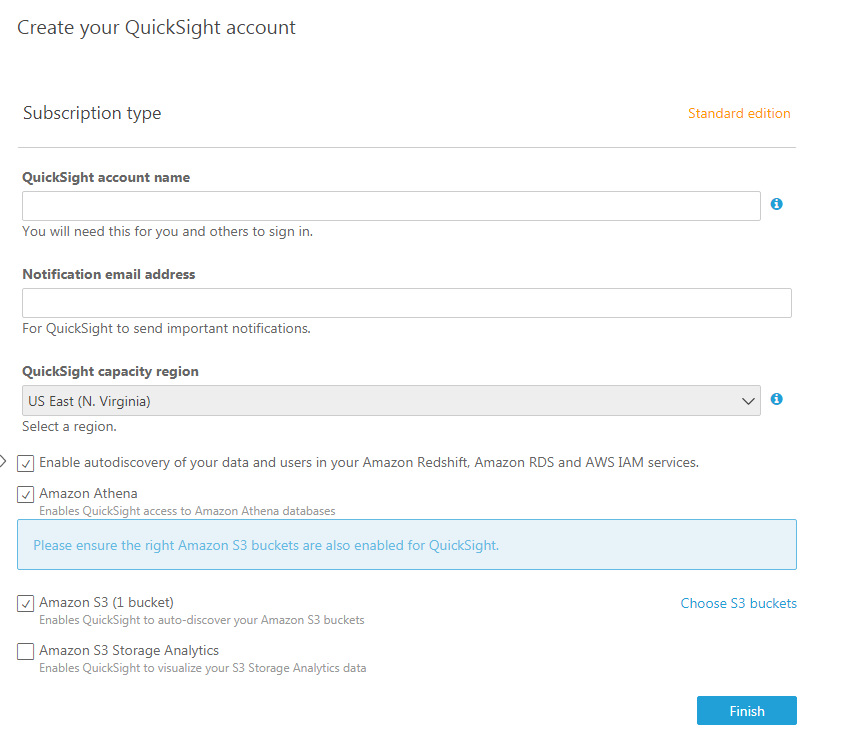
使用するS3 bucketの選択はChoose S3 Bucketsをクリックして設定します。
そして上記の画面でFinishボタンをクリックするとQuickSightのAccount設定が完了します。
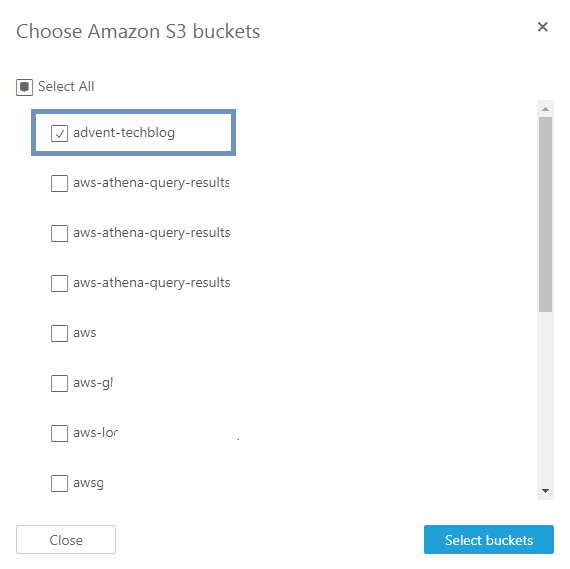
QuickSight account設定完了画面

Go to Amazon QuickSightボタンをクリックするとQuickSightのメイン画面が表示されます。
ここでNew analysisボタンをクリックし実際のデータ可視化作業を進めて行きます。

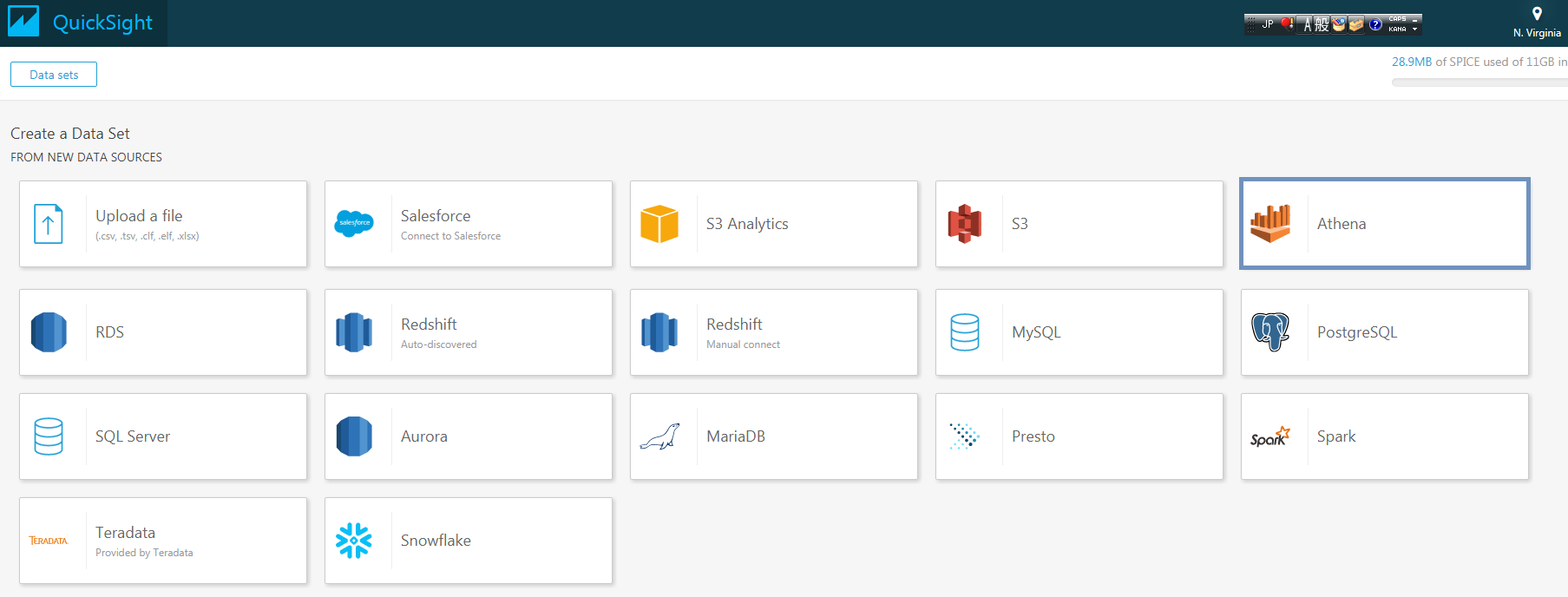
まずはNew data setボタンをクリックし使用するData Setを設定します。

ここでAthenaを選択します。
Data Source Nameを設定します。(Data Source Name: tech_blog)
そしてCreate data sourceボタンをクリックします。
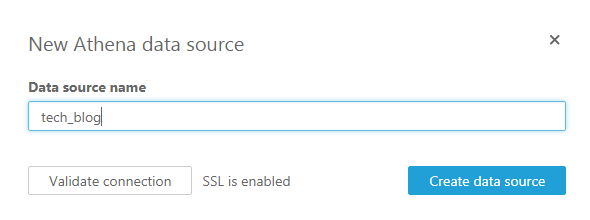
そうするとAthenaのDBとTableを選択する画面が表示されます。
ここでは先ほどAthenaで作成したDBとTableを選択してSelectボタンをクリックします。
最後にSPICEを使用するかどうかの選択画面が表示されます。
SPICEはAthenaのインメモリエンジンで高いパフォーマンスを実現出来るそうですが、
まだ文字データのSort機能がないため
ここではDirectly query your dataを選択しVisualizeボタンをクリックします。
これでData Setの設定が終わり、データの可視化を行う画面が表示されました。
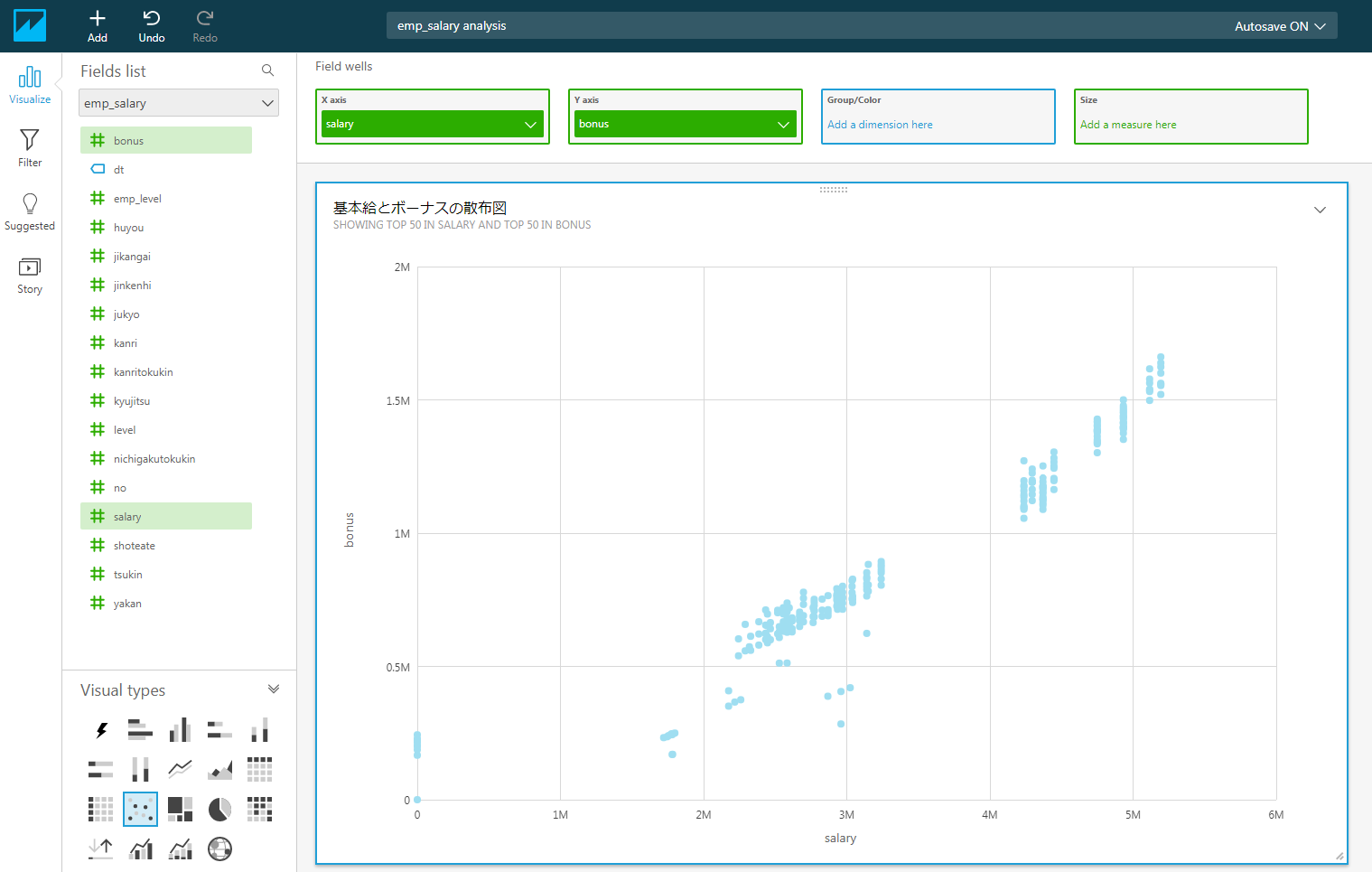
では、可視化の例として、基本給とボーナスの散布図を表示してみましょう。
左下にあるVisual typesでScatter plotを選択し、左のField Listから表示する項目を
Drag&DropでField wells領域にあるX axis、Y axisに設定します。
そうすると、下記のようなグラフが出来ます。
これで基本給とボーナスは比例していること、そして一部の区間では基本給の格差があることが分かります。
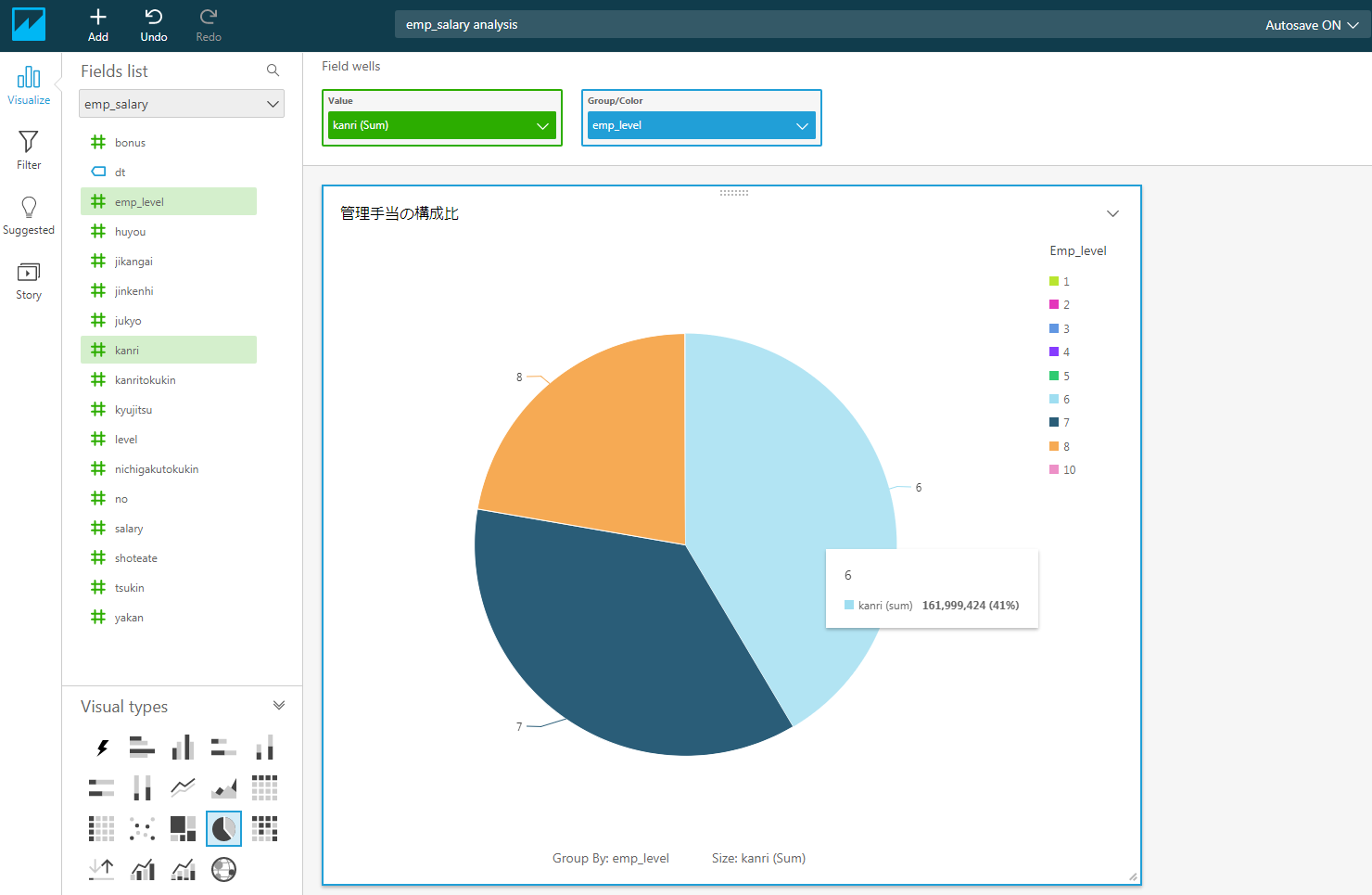
つづいて、Pie Chartで管理手当の構成比をレベル別で表示してみましょう。
この結果では管理手当はレベル6、7、8の職員が対象で
レベル6の場合は全体管理手当の41%を占めていることが分かります。
そして、レベル6、7、8の職員が管理職であることが推測できます。
ここまでQuickSightの設定と簡単な操作方法について説明しました。
iPhoneでQuickSightを使おう
QuickSightはiPhone用のAppがありiPhoneでも操作することが出来ます。
因みに、Androidの方はまだないようです。
まずはApp StoreでQuickSightで検索してインストールします。


Appを起動し、ログインします。
ログインにはAccount name、email address or username、passwordが必要です。
Account nameにはQuickSight account作成時に設定したaccount nameを入力します。
email address or usernameにはusernameを入力します。
因みに、email addressも入力可能のようですが、私の場合はログイン失敗になりました。

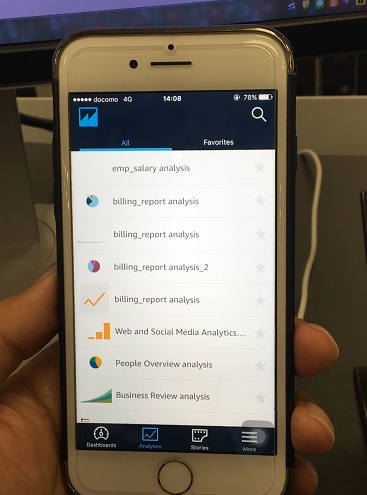
ログインするとAnalysisリストが表示されます。ここで先ほど作成したAnalysisを選択します。
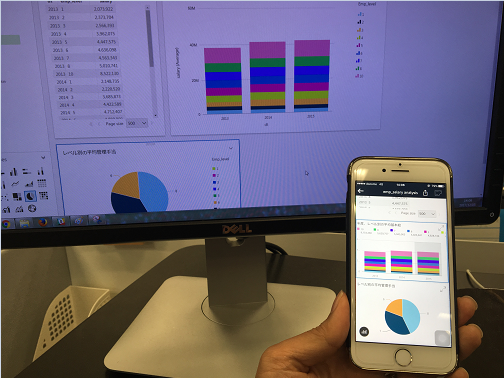
これでiPhoneでもPCと同じ内容を確認することが出来ます。
まとめ
s3 + Athena + QuickSightでデータ分析、データの可視化が手軽に出来ます。
Hadoopクラスターを構築してその上にHiveなどのSQL on Hadoopサービスを入れる必要もありません。
データ分析がしたくてもデータ分析環境がない、データ分析環境が欲しくても初期費用が高い、
サーバー構築に時間がかかるなどで悩んでいた方々どうぞ!
今すぐデータ分析を始められます。


Recommends
こちらもおすすめ
-

2017年は本当に「ビッグデータ利活用元年」だったのか
2017.12.16
-

AWS GlueとAmazon Machine Learningでの予測モデル
2017.12.17
-

R からシームレスに Python を呼べる reticulate が便利だった
2018.4.13
-

Amazon EC2 F1インスタンスを試してみた!
2017.12.22


Special Topics
注目記事はこちら

データ分析入門
これから始めるBigQuery基礎知識
2024.02.28

AWSの料金が 10 %割引になる!
『AWSの請求代行リセールサービス』
2024.07.16