Apache Sparkとpandasでデータ処理の時間を短縮する方法

2017.12.21

こんにちは。データサイエンスチームのHan-Cheolです。
この記事は、NHN テコラス DATAHOTEL:確率統計・機械学習・ビッグデータを語る Advent Calendar 2017の21日目の記事になります。
はじめに
PandasはPythonを利用したデータ分析で一番よく知られ、使われているツールです。
本記事では、データのサイズが大きく、またデータ分析を行うための前処理作業の計算量が多い時に、PySpark (Apache SparkのPythonインタフェース)の並列・分散処理能力を生かしてデータの前処理に掛かる時間を大きく短縮させる方法を紹介します。
今回の記事で例として使うタスクは、スコア付けの商品口コミデータからスコアに大きい影響を与える表現 (ここでは形容詞句)を抽出するデータマイニングタスクを想定します。このようなリソースは色んな場面で活用できます。たとえば、同じジャンルのテキストを教師無し機械学習で分類する時に貴重な資源になります。
具体的な手順としては、口コミテキストに対して文分割、形態素解析、句構造解析という前処理を行います。その後、形態素と句構造情報を利用して口コミに含まれている形容詞句を抽出 (ここではルールべス手法を利用)します。最後に、どの表現が口コミのスコア (例、高い・低い)に大きく影響を与えているのかを分析します。
データ処理を高速化するには色んな手法がありますが、PySparkを使うと下記のようなメリットがあります。
- 1台のサーバー上で並列処理 (multi-processing)が可能
- Hadoop clusterやSpark stand-alone clusterを利用した分散処理 (distributed computing)が可能
- 1と2は同じコードで実行可能 (ローカルまたは分散モードを指定するだけ)
1. 事前準備
実験に使うデータセットをダウンロードします。以前記事 (「口コミデータを活用したレコメンドシステムの可能性」)で使ったものと同じ、米アマゾンの商品口コミデータ(食品カテゴリー、約15万レビュー)です。まだダウンロードしてない方は下記のようにwgetでダウンロードできます。
wget -O /tmp/reviews_Grocery_and_Gourmet_Food_5.json.gz \
http://snap.stanford.edu/data/amazon/productGraph/categoryFiles/reviews_Grocery_and_Gourmet_Food_5.json.gz
今回も以前と同様、Python 3.xとJupyter notebookを利用します。下記のように必要なライブラリをインポートしましょう。もしインストールされてないライブラリがありましたらpipでインストールしてください。
import sys import os from collections import deque, Counter from itertools import chain import timeit import requests import pandas as pd import numpy as np import spacy from pyspark.sql import SparkSession from pyspark import Row from adjustText import adjust_text from matplotlib import pyplot as plt import matplotlib.font_manager %matplotlib inline
続けてデータを読み込みます。pandas DataFrameのread_json()メソッドで簡単に読み込みできます。
datapath= '/tmp/reviews_Grocery_and_Gourmet_Food_5.json.gz'
# pandas DataFrameで読み込む
pd_raw = pd.read_json(datapath,
lines=True,
encoding='utf-8',
compression='gzip')
# 一部、明示的に型を指定する
str_columns = ['asin','reviewText','reviewTime',
'reviewerID','reviewerName','summary']
for colname in str_columns:
pd_raw[colname] = pd_raw[colname].astype(str)
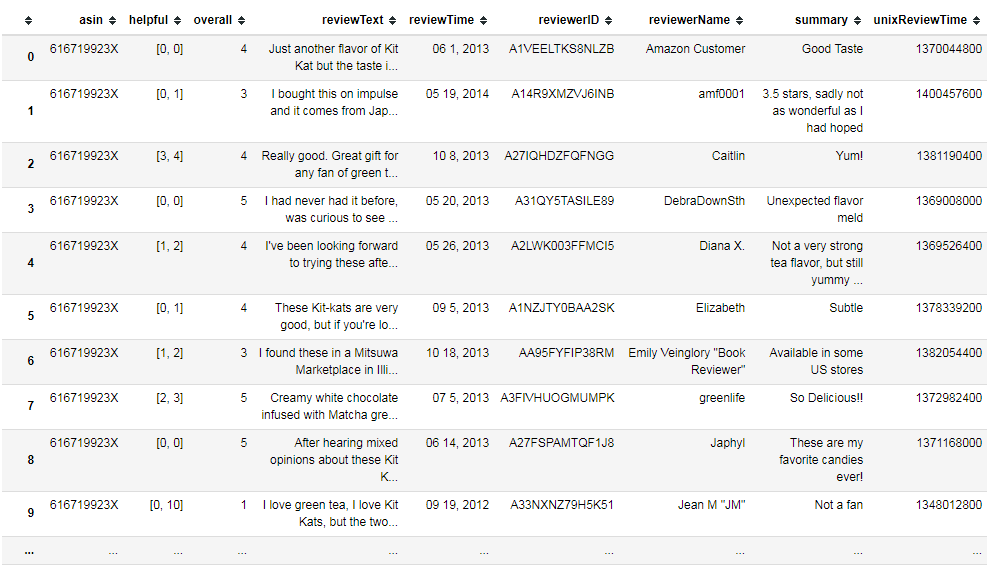
最終的に読み込まれたデータは下記のように9カラムで構成されたDataFrameになります。
2.1. 前処理段階 (基本バージョン)
前処理では、データのreviewTextカラムに存在する口コミから形容詞句を抽出します。自然言語処理用のライブラリとしてはspacy (実サービスでの利用を念頭において高性能ツールセットとして開発された自然言語処理ライブラリ)を使い、形容詞句の抽出のためには下記のAdjectivePhraseクラスを作りました。
class AdjectivePhrases(object):
def __init__(self, sent):
"""形容詞句抽出器を初期化。
Params:
sent: spacyのsentオブジェクト
"""
self._phrases = []
# 対処とするtag
self._target_tags = set(['JJ', 'JJR', 'JJS'])
# 下記の子ノードは無視
# cc: coordination
# punct: punctuation
# xcomp: open clausal complement
self._exclude_deps = set(['cc', 'punct', 'xcomp'])
# 形容詞句を抽出
self._detect(sent)
def _is_neg(self, node):
"""形容詞句の意味を反転するべきかを決定。
"""
# Case 1. 親ノードへの依存関係がacompで、また親ノードがneg依存関係
# の子ノードを持っている場合にTrue.
if node.dep_ == 'acomp':
for child in node.head.children:
if child.dep == 'neg':
return True
return False
def _process_children(self, lr_children):
"""形容詞の左・右のsub-treeに対して、一定条件を満たす子ノードから
形容詞句を構成する文字列を抽出する。
params:
nodes: token.lefts/rights
return:
target_nodes: 形容詞句に含まれる子ノード
next_nodes: 今回抽出する形容詞句には含まれない子ノードで次回処理対象
"""
target_nodes = []
next_nodes = []
for node in lr_children:
if node.dep_ in self._exclude_deps:
pass
elif node.dep_ == 'conj':
# 同位接続詞は別の形容詞句として処理
next_nodes.append(node)
else:
# そのほかであれば、subtreeの文字列を使用
target_nodes.append(node)
return target_nodes, next_nodes
def _normalize_token_text(self, token):
"""tokenの文字列を正規化。
"""
t = token.text_with_ws
t = t.lower()
return t
def _detect(self, sent):
"""形容詞句を抽出。
"""
next_nodes = deque([(None, sent.root)])
while next_nodes:
b_neg, node = next_nodes.popleft()
if b_neg is None:
b_neg = self._is_neg(node)
if node.tag_ in self._target_tags:
phrase = []
left_res = self._process_children(node.lefts)
right_res = self._process_children(node.rights)
# 形容詞句を抽出
for sub_node in left_res[0]:
phrase.extend([self._normalize_token_text(t) for t in sub_node.subtree])
phrase.append(self._normalize_token_text(node))
for sub_node in right_res[0]:
phrase.extend([self._normalize_token_text(t) for t in sub_node.subtree])
# 同位接続詞は次回処理対象として追加
next_nodes.extend(
[(b_neg, child) for child in left_res[1]])
next_nodes.extend(
[(b_neg, child) for child in right_res[1]])
self._phrases.append(''.join(phrase).strip())
else:
# 違う場合は続けてchildノードを探索
next_nodes.extend(
[(None, child) for child in node.children])
def __iter__(self):
for p in self._phrases:
yield p
def udf_extract_adj_phrases(text):
for sent in nlp(text).sents:
for phrase in AdjectivePhrases(sent):
yield phrase
このクラスを利用して口コミから形容詞句を抽出していきます。複数の自然言語処理タスクを含むこの前処理段階はとても重い作業であり、ご覧の通り実際の分析段階より多くの時間を費やしています。PySparkを利用した時と実行時間を比較するため処理時間を測定しましょう。
先にspacyを実行するのに必要なモデルファイルをダウンロードします。英語の場合は下記の命令でダウンロードできます。そのほかの言語はhttps://spacy.io/usage/modelsを参照してください。
$ python -m spacy download en
続けて前処理を行います。
# 英語用の自然言語モジュールをロード
nlp = spacy.load('en')
# 形容詞句を抽出する。
# また、掛かった時間を測定する。
start_t = timeit.default_timer()
adj_col = pd_raw['reviewText'].apply(
lambda text: list(udf_extract_adj_phrases(text)))
end_t = timeit.default_timer()
# 実行時間を測定
print('Time elapsed: {:.5} seconds'.format(end_t-start_t))
Time elapsed: 4188.7 seconds.
約15万口コミを処理するのに70分ほどかかりました。実行環境のサーバは二つのXeon E5-2650 (2.0GHz/6core) CPUと24GBのメモリーを搭載しています。
2.2. 前処理段階 (PySparkバージョン)
ここでは、前処理段階をPySparkを使って高速化してみたいと思います。まず、下記のようにSparkSesssionを生成します。
os.environ['PYSPARK_PYTHON'] = '/path/to/python/executable'
# 各パラメータ値は、お使いのHadoopクラスタの環境に合わせて調節してください。
# ここでは12個のexecutorプロセスを使います。
nexec = 12
spark = SparkSession.builder\
.master('yarn')\
.config('spark.executor.instances', nexec)\
.config('spark.driver.memory', '5g')\
.config('spark.executor.memory', '2g')\
.config('spark.driver.maxResultSize', '2g')\
.appName('Parsing texts with spacy')\
.getOrCreate()
続けて、形容詞句抽出のための関数 (spark_udf_extract_adj_phrases)を定義します。このudfはPySparkで一般的に使われるmap()メソッドではなくmapPartitions()メソッド用になります。前者はデータ1個に対して関数を1回呼び出すためspacyのように初期化が重い処理をするには向いてないです。それにくらべ、パーティション単位で処理を行う後者はこのような問題を回避できます。
def spark_udf_extract_adj_phrases(rows):
"""spacyインスタンスの生成時間が多く掛かるため、データはrecordではなく
partition単位で処理する。
注意:
* 分散モード実行時にはすべてのworker nodeにspacyライブラリ
をインストールする必要がある。
"""
import spacy
nlp = spacy.load('en')
for row in rows:
index = row[0]
text = row[1]
res = [index, []] # [pandas index, phrases]
for sent in nlp(text).sents:
res[1].extend(list(AdjectivePhrases(sent)))
yield res
そして、データが保存されているpandas DataFrameをSpark RDDに変換し、形容詞句を抽出し、またpandas DataFrameに戻します。Sparkはlazy evaluationを行うため、実際に処理が必要な段階(rdd_parsed.collect()部分)になってプロセスが動き始めます。
# pandas DataFrameからSpark RDDへ変換
start_t = timeit.default_timer()
rdd_review = spark.sparkContext.parallelize(
pd_raw.reset_index()[['index', 'reviewText']].as_matrix())
end_t = timeit.default_timer()
print('Time elapsed: {:.5} seconds'.format(end_t-start_t))
# 形容詞句を抽出
start_t = timeit.default_timer()
rdd_parsed = rdd_review.mapPartitions(spark_udf_extract_adj_phrases)
end_t = timeit.default_timer()
print('Time elapsed: {:.5} seconds'.format(end_t-start_t))
# Spark RDDからpandas DataFrameへ再変換
start_t = timeit.default_timer()
spark_adj_col = pd.DataFrame(rdd_parsed.collect(),
columns=['index', 'adjPhrases'])
end_t = timeit.default_timer()
print('Time elapsed: {:.5} seconds'.format(end_t-start_t))
Time elapsed: 1.6143 seconds.
Time elapsed: 0.00016939 seconds.
Time elapsed: 483.32 seconds.
データ変換に約1.6秒、そして形容詞句の抽出が約8分かかりました。処理時間が前回の4188秒と比べて、約80%短縮されたことが分かります。
タスクを実行したHadoopクラスタは総6台のworker nodeを持ち、それぞれXeon E3-1265L (2.5Ghz/8core) CPUを1個、16GBのメモリーを搭載しています。
3. 商品評価表現の分析
2.1.の結果 (adj_col)または2.2の結果(spark_adj_col)を元データと統合します。ここではspark_adj_colを使います。統合されたpd_reviewは、asin (アマゾン商品コード), overall (評価点数), reviewText (元の口コミ), adjPhrases (口コミから抽出された形容詞句)、そして評価点数に基づいて生成されたreviewScore (overallが1または2の場合はlow、3または4の場合はhigh)カラムを持ちます。
# asin, overall, reviewText, adjPhrases, reviewScoreのdataframeを生成
pd_review = pd.merge(
pd_raw[['asin','overall','reviewText']].reset_index(),
spark_adj_col,
on='index')
# score == 3のレビューを除外
pd_review = pd_review[pd_review['overall'] != 3]
# スコア4点以上とそれ以外に分類
pd_review['reviewScore'] = pd_review['overall'].apply(
lambda score: 'high' if score >= 4 else 'low')
pd_review = pd_review.set_index('index')
最初に下記の関数を定義します。
def comp_freq(df):
high_cnt = Counter()
low_cnt = Counter()
for idx, row in df.iterrows():
if row['reviewScore'] == 'high':
high_cnt.update(Counter(row['adjPhrases']))
else:
low_cnt.update(Counter(row['adjPhrases']))
return high_cnt, low_cnt
def build_term_info(df, min_total=5):
"""分析用データを作成。
"""
res = {'term':[], 'x':[], 'y':[], 'total':[], 'ratio':[]}
high_cnt, low_cnt = comp_freq(df)
terms = set(high_cnt.elements()) | set(low_cnt.elements())
for term in terms:
x_cnt = low_cnt.get(term, 0)
y_cnt = high_cnt.get(term, 0)
if x_cnt + y_cnt <= min_total:
pass
else:
res['term'].append(term)
res['x'].append(low_cnt.get(term, 0))
res['y'].append(high_cnt.get(term, 0))
res['total'].append(res['x'][-1] + res['y'][-1])
res['ratio'].append((res['y'][-1] * 1.0) / res['total'][-1])
return res
def get_terms(sorted_term_idx_and_score, start_, end_):
"""指定されたterm-scoreペアをdataframeで切り出す。
sorted_term_idx_and_score: [[term, score], ...]の形式で、scoreでソートされている
start_: 始まり
end_: 終わり
"""
terms = []
for term_idx, score in sorted_term_idx_and_score[start_:end_]:
terms.append([plt_data['term'][term_idx], term_idx, score])
return pd.DataFrame(terms, columns=['term', 'term_index', 'score'])
続けて、各形容詞句がスコアが高い口コミまたは低い口コミからどれぐらい出現したのか、その比率はどれぐらいなのかを計算します。
# 出現回数が5回未満は除外 info = build_term_info(pd_review, min_total=5) # 結果をソート sorted_term_idx_and_score = sorted(enumerate(plt_data['ratio']), key=lambda x: x[1])
それでは、実際に出現頻度比 (高いスコアの口コミからよく出てくるほど高い)が高い形容詞句100個を見てみます。
n = 100
top_n_terms = get_terms(
sorted_term_idx_and_score,
len(sorted_term_idx_and_score) - n,
len(sorted_term_idx_and_score))
top_n_terms.reset_index().sort_values(
['score', 'index'],
ascending=[False, True])
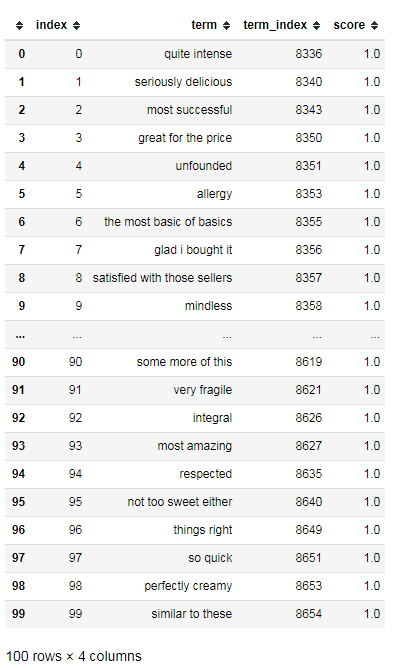
曖昧な表現も含まれていますが”seriously delicious”や”great for the price”など、なかなか納得がいく表現が多く含まれていることがわかります。
今回は、頻度の情報も含めて可視化してみたいと思います。頻度情報が分かれば高いスコアの口コミでもっと頻繁に出現する表現を探すことが可能です。そのため、先に下記の関数を定義します。
def customFont(fontpath='/usr/share/fonts/truetype/fonts-japanese-gothic.ttf',
fontsize=12):
return matplotlib.font_manager.FontProperties(
fname=fontpath,
size=fontsize)
font10 = customFont(fontsize=10)
font20 = customFont(fontsize=20)
def draw(terms, plt_data, rand_seed=12345):
"""Scatter plotでグラフを描く。
Params:
terms: [[term, term_index, score], ...]
plt_data: make_plot_data()で生成されたもの
"""
np.random.seed(rand_seed)
# xs, ysを生成
xs = []
ys = []
#indices = [item[0] for item in targets]
term_indices = terms.term_index.tolist()
for idx in term_indices:
xs.append(plt_data['x'][idx] + np.random.random()*0.3)
ys.append(plt_data['y'][idx] + np.random.random()*0.3)
# plotする
fig = plt.figure(figsize=(12,12))
ax = fig.add_subplot(111)
xmax_ = max(xs)+1
ymax_ = max(ys)+1
max_ = max([xmax_, ymax_, 10])
plt.xticks(np.arange(0, max_, int(max_/10)))
plt.xlim(0, max_)
plt.xlabel('形容詞句が含まれている低スコア(1,2)文書の数',
fontproperties=font20)
plt.yticks(np.arange(0, max_, int(max_/10)))
plt.ylim(0, max_)
plt.ylabel('形容詞句が含まれている高スコア(1,2)文書の数',
fontproperties=font20)
# annotateすると文字が被って見えない
texts = []
for xy_index, term_idx in enumerate(term_indices):
texts.append(plt.text(
xs[xy_index],
ys[xy_index],
'{}: {:.4}'.format(
plt_data['term'][term_idx],
terms.score.iloc[xy_index])
))
plt.grid()
# annotationの位置を微調整
adjust_text(texts,
arrowprops=dict(arrowstyle='->', color='blue', alpha=0.4),
lim=100)
# データをプロット
plt.scatter(xs, ys, s=5, c='red', alpha=0.5)
# x=y線を描く
plt.plot(np.arange(0, max_), np.arange(0, max_), c='black')
ある形容詞句に対して高いスコアの口コミから出現した数をy軸に、低いスコアの口コミから出現した数をx軸にしてプロットしてみたものが下記のグラフです。100個だけを絞って見せてます。また、グラフ上で同じ場所に点が集まらないように位置情報には少しノイズを加えています。
draw(top_n_terms, info)

同じく高スコアの口コミ vs. 低スコアの口コミの出現比率が1.0であっても、出現頻度は結構違うことが分かります。たとえば、”most amazing”や”it nice”などが”as good as”や”seriously delicious”よりは頻繁に出現することがわかります。
もう一つの特徴としては、上位100の結果はそのすべてが割合1.0、つまりスコアが低い口コミからは1回も出てない表現でした。
続けて、スコアが低い口コミにも同じ分析を行って見ます。
n = 100
bottom_n_terms = get_terms(
sorted_term_idx_and_score,
0, n)
bottom_n_terms.sort_values('score', ascending=True)
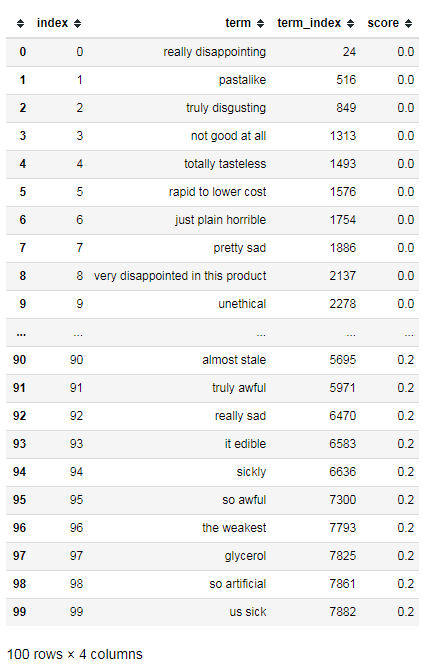
“really disappointing”や”truly disgusting”、”totally tasteless”など、スコアが低い口コミによく出現する表現もよく納得がいくものです。
下は頻度情報も含めて可視化してみた結果です。
draw(bottom_n_terms, info)
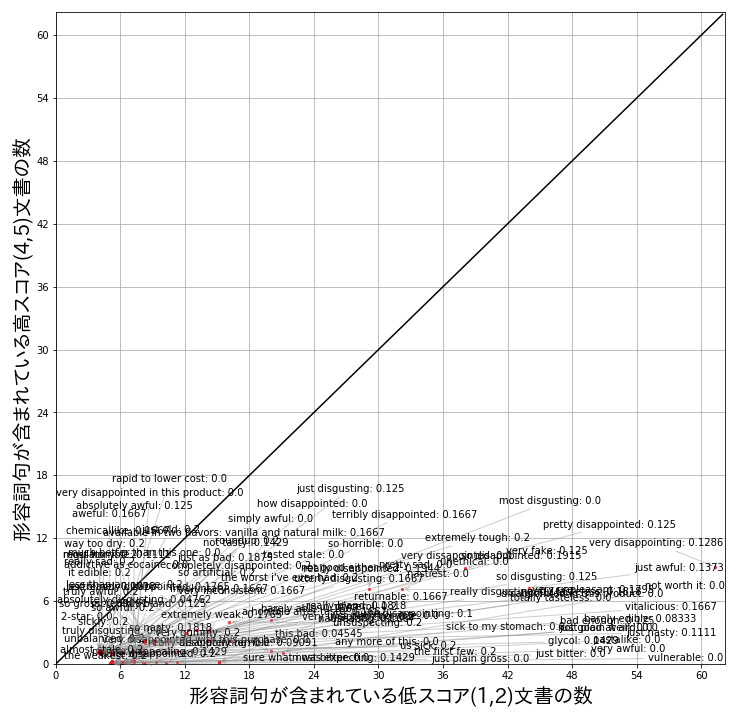
多くの表現が0.0~0.2ぐらいの比率を持っていて、x軸の近くによっていることが分かります。頻度が多い表現としては、”very disappointing”や”just awful”そして”absolutely disgusting”などの表現が含まれていました。
4. まとめ
今回の記事では、PySparkを利用して処理時間が多く掛かるデータ分析の前処理を高速化する方法を調べてみました。他の手法と比べて、並列・分散処理をシームレスに連動させることが可能なのはスケーラビリティの面ではとても強い長所だと思います。
また、前処理の高速化だけではなく、分析内容でも口コミデータから評判が良い時 (または悪い時)によく使われる表現を抽出する方法を見てみました。教師なし評判分析のための辞書構築に活用できるのではないかと思います。


Recommends
こちらもおすすめ
-

Pythonで時系列データをクラスタリングする方法
2017.12.12
-

Apache Sparkのパーティション分割について
2022.12.29
-

純粋数学専攻がデータサイエンティストに転身してからの半年間を振り返る
2017.12.19
-

pyenvによるPythonの開発環境構築【Mac】
2023.6.12


Special Topics
注目記事はこちら

データ分析入門
これから始めるBigQuery基礎知識
2024.02.28

AWSの料金が 10 %割引になる!
『AWSの請求代行リセールサービス』
2024.07.16