統計的仮説検定とは?サンプルサイズの決め方も解説

こんにちは。データサイエンスチーム tmtkです。
この記事では、統計的仮説検定をするときのサンプルサイズの決め方の入門的解説を行います。
この記事は、永田靖『サンプルサイズの決め方』を参考に書かれています。
統計的仮説検定の枠組み
最初に、統計的仮説検定について復習します。
まずは身近な例で説明します。いま、表と裏が等確率で出るとされているコインがあるとします。このコインを10回投げて、10回とも全部表が出たとしたら、コインの表が出る確率が裏が出る確率より高いと疑うのではないでしょうか。実際、表と裏が等確率で出るコインを10回投げて、10回連続で表が出る確率は
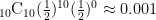
です。つまり、表裏が等確率で出るコインを投げて表が10回連続で出たとすると、0.1%程度の確率しかないことが起こっているということになります。この場合、非常に低確率なことが起こっているので、「このコインはおかしい」と判断することができそうです。統計的仮説検定はこのような判断を統計的に正しく行う枠組みです。
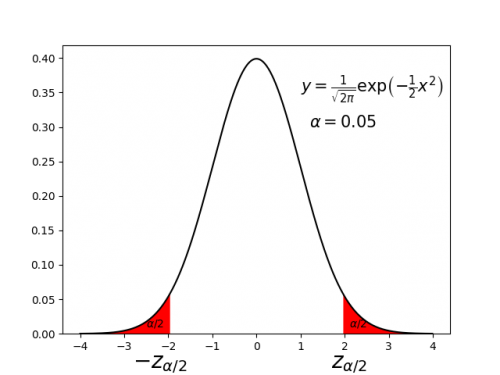
統計的仮説検定をより正確に説明します。ここでは、母分散が既知の正規分布について、母平均を両側検定する場合について説明します。現実には母分散が既知であることは考えづらいのですが、話が簡単になるため学習用によく持ち出される設定です。
いま、データ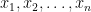
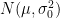
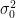





が上側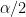
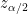
を満たしていれば、帰無仮説
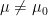
(
以下、統計的仮説検定を単に仮説検定と呼びます。
また、サンプルの大きさをサンプルサイズと呼びます。上のコイン投げの例でいう

【事例集】AIや機械学習によるビッグデータ活用をしたい方にオススメ!

「AIによるキャスト評価システムの構築」「データ分析基盤の運用費用9割削減」など、AWSを利用したAI、機械学習の成功事例をご紹介します。
なぜサンプルサイズを決める必要があるか
サンプルサイズが大きくなればなるほど、推定量の精度は高くなることが多いです。たとえば、正規分布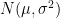




サンプルサイズが大きくなれば、推定の精度はどんどん上がっていきます。精度は高ければ高いほどいいので、統計的仮説検定を行うサンプルサイズは大きければ大きいほどよいようにも思えます。
しかし、現実には仮説検定でつかうサンプルサイズは大きすぎないほうがよいといわれています。なぜでしょうか。
その答えは、仮説検定は帰無仮説
帰無仮説の母平均と真の母平均が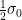 離れている場合
離れている場合
例として、母分散が既知の正規分布の母平均の両側検定について考えます。有意水準

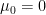
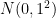
ここで、真の母平均
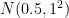
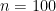

この設定のもとでは、検定統計量

は正規分布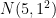


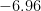
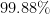
したがって、まとめると、真の母平均と帰無仮説の母平均が
この場合は
帰無仮説の母平均と真の母平均が 離れている場合
離れている場合
次に、前の例と同様にして、今度は真の分布が
前の例と同様の計算で、サンプルサイズが


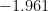
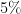
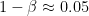
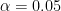
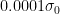
しかし、サンプルサイズを莫大にして、
この場合には、統計検定量
母平均がたったの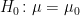
これまで見てきたように、サンプルサイズを大きくすれば大きくするほど、検出力は上がります。サンプルサイズをいくらでも大きくすれば検出力をいくらでも大きくすることができるため、帰無仮説で設定した母数が非常に小さい誤差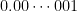
これの現象を防ぐためには、サンプルサイズを調節して、帰無仮説と真の値で意味のある差があれば帰無仮説を棄却できる程度にサンプルサイズを大きく、意味のない微小な差なら帰無仮説が棄却されない程度にサンプルサイズを小さく設定する必要があります。これがサンプルサイズを決めることが必要な理由です。
AWSのビッグデータ活用・機械学習導入支援サービス
サンプルサイズの決め方(母分散が既知の正規分布の母平均を仮説検定する場合)
それでは、母分散が既知の正規分布の母平均を仮説検定する場合について、サンプルサイズの決め方を説明します。とはいっても、上でやった計算とほとんど同じです。上の計算ではサンプルサイズから検出力を計算しましたが、サンプルサイズを設計するときには逆に検出力からサンプルサイズを計算します。
これまでと同様に、母分散が既知の正規分布の母平均を仮説検定する場合について考えます。
これまでと同じように、既知の母分散は
帰無仮説が棄却されるのは統計検定量
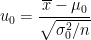
が
を満たすときでした。ここで、
この条件
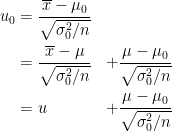
となります。ただし、
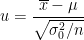
とおきました。すると

したがって、帰無仮説が棄却される確率は
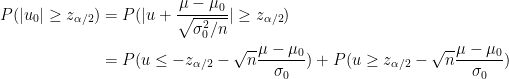
となります。これが検出力
具体例
具体的な数値を使って、計算方法を実際に確認してみましょう。有意水準を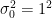
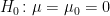

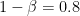
ここで成り立つべき式は
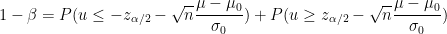
ですから、今回の値では
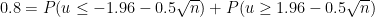
が成り立つようにサンプルサイズ
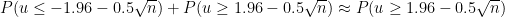
が成り立つと仮定して計算を進めると、これが検出力

が成り立てばよいことがわかります。これを計算すると
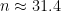
となるので、サンプルサイズ
とすればよいことがわかります。また、上でおいた仮定の近似が成り立っていることも確認できます。
上のほうでサンプルサイズを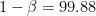

以上がサンプルサイズの計算の仕方です。
まとめ
この記事では、サンプルサイズを決める必要性についての説明と、母分散が既知の正規分布の母平均を仮説検定する場合のサンプルサイズの決め方について解説しました。
母分散が既知の正規分布の母平均を仮説検定する状況は現実にはあまりありませんが、別の状況でもここで説明した考え方を応用することができます。たとえば、A/Bテストのサンプルサイズの決定に応用することが考えられます。ただし、ユーザの多いウェブサービス上でのA/Bテストの場合は、非常に大きいサンプルサイズを取得することができることが多いため、統計的仮説検定やサンプルサイズの決定などの手続きを踏む必要性が低い場合があります。
AWSのビッグデータ活用・機械学習導入支援サービス
参考
- 倉田博史、星野崇宏『入門統計解析』
統計学の入門書です。仮説検定の枠組みなど基本的なことがわからない場合は参照してください。 - 永田靖『サンプルサイズの決め方』
サンプルサイズの決め方について書かれた本です。この記事はこの本を参考に書かれました。
これからビッグデータ活用を始める方にオススメ!

AIブームなどにより、先端ビジネスの主要テーマのひとつとなっている「ビッグデータ」。事例を交えながら、ビッグデータの解析や活用方法について解説します。

データ分析と機械学習とソフトウェア開発をしています。 アルゴリズムとデータ構造が好きです。


Recommends
こちらもおすすめ
-

Office 365入門【1】Office 365のID管理とは?
2017.10.2
-

Firefox Quantumリリース! VimFxの後継について調べてみた
2017.11.16
-

【Linux】Webアプリ開発における簡単なトラブルシューティング
2023.9.1
-

ラズパイと対話する植物と自称IoT女子
2016.8.19


Special Topics
注目記事はこちら

データ分析入門
これから始めるBigQuery基礎知識
2024.02.28

AWSの料金が 10 %割引になる!
『AWSの請求代行リセールサービス』
2024.07.16