AICによるARモデルのモデル選択

こんにちは。データサイエンスチームのtmtkです。
この記事では、AICによるARモデルのモデル選択について説明します。
背景
前回の記事では、時系列解析の入門としてARモデルを紹介しました。そこでは、パラメータのうち次数
次数
AIC(An Information CriterionまたはAkaike Information Criterion、赤池情報量規準)というのはARモデルの“ちょうどいい”次数
AICとは
AICについての詳細は各種書籍にゆずることにし、ここでは簡単に定義と結論だけ述べます。
AICは
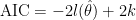
 はモデルのパラメータ、
はモデルのパラメータ、 はの最尤推定量、関数
はの最尤推定量、関数 は対数尤度関数、
は対数尤度関数、 はモデルのパラメータの数です。
はモデルのパラメータの数です。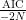 は平均対数尤度
は平均対数尤度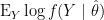 の近似的な推定量になっているため、
の近似的な推定量になっているため、 を最小にする次数を選択することで、最適なモデルを選ぶことができるとされています。
を最小にする次数を選択することで、最適なモデルを選ぶことができるとされています。
ARモデルのAIC
それでは、実際にARモデルのAICを計算し、最適なモデル選択をしてみます。
データとして、コサインカーブに正規分布ノイズを加えたデータを使います。
import numpy as np np.random.seed(1234) N = 200 std = 0.2 x = np.arange(0, N) y = np.cos(x*np.pi/10) + np.random.normal(0, std, N)
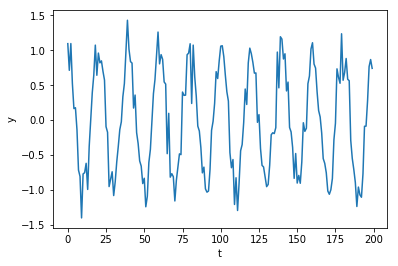
200個のサンプルのうち、最後の20個のサンプル
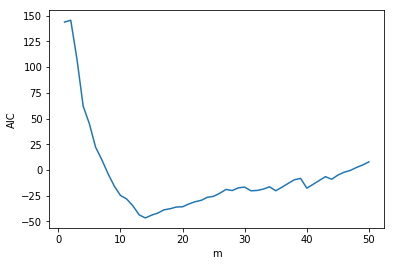
次数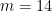



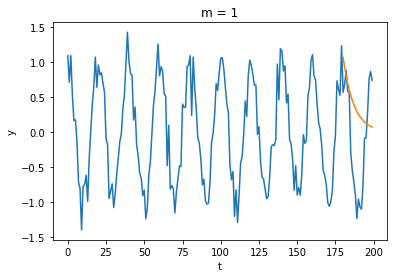
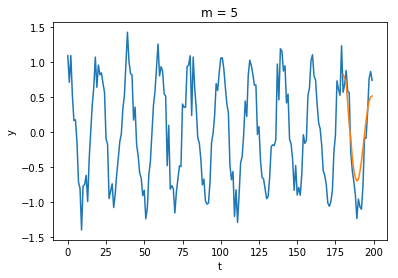
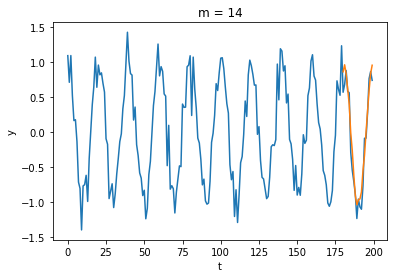
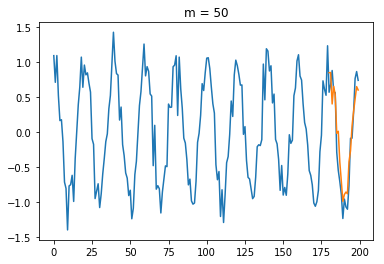
AICとホールドアウト法
以上で、AICによるARモデルの選択を説明しました。機械学習の文脈では、モデル選択の方法として、ホールドアウト法やそれを発展させた交差検証法(Cross Validation)がよく使われていると思います。そこで、AICによるモデル選択と、ホールドアウト法によるモデル選択の関係を実験的に調べてみます。
上の実験と同様の状況で、各次数
AICと平均二乗誤差をプロットすると、以下のようになります。
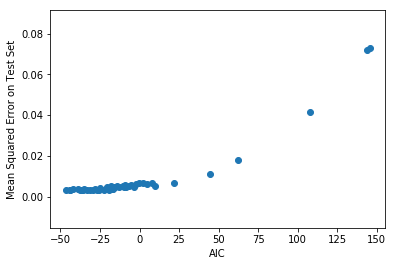
AICが小さくなるほど平均二乗誤差も小さくなる傾向を読み取ることができます。したがって、この場合はAIC最小のモデルを選ぶことと、ホールドアウトしたデータセットに対する平均二乗誤差が最小になるモデルを選ぶことは、おおむね同じことになります。
まとめ
この記事では、AICを説明し、AICを使ってARモデルの次数選択を行いました。
また、AICが小さいモデルほど、予測誤差が小さくなる傾向を、実験的に確認しました。
参考文献
- 北川源四郎『時系列解析入門』
- 坂元慶行・石黒真木夫・北川源四郎『情報量統計学』
- 信号解析 第8回講義録

データ分析と機械学習とソフトウェア開発をしています。 アルゴリズムとデータ構造が好きです。


Recommends
こちらもおすすめ
-

ARモデルの誤差分析について
2019.3.7
-

基礎からはじめる時系列解析入門
2019.2.22
-

ARモデルの表現能力を考察する
2019.3.1
-

機械学習の受託案件を通じて気づいた5つのこと
2019.3.8
-

社内マッサージルーム利用状況がパレートの法則にしたがっているかを検証する
2018.9.26
Special Topics
注目記事はこちら

データ分析入門
これから始めるBigQuery基礎知識
2024.02.28

AWSの料金が 10 %割引になる!
『AWSの請求代行リセールサービス』
2024.07.16