ARモデルの誤差分析について

Topics
こんにちは。データサイエンスチームもtmtkです。
この記事では、ARモデルの誤差分析について説明します。
はじめに
前の3回の記事にわたって、時系列解析の入門としてARモデルについて紹介し、AICによるARモデルのモデル選択について解説し、ARモデルの表現能力について議論しました。
ARモデルをつかうと過去の時系列データから未来のデータの値を予測することができます。実際に予測を行う場合には、その予測の信頼区間も知りたいことが多いと思います。つまり、予測がどれくらいずれうるのかまでを知りたいということです。
この記事では、ARモデルで未来のデータを予測するとき、予測の誤差について考察します。
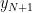 の誤差分析
の誤差分析
ARモデルは、式
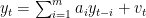
で表され、誤差項
 が誤差をつかさどっているのでした。
が誤差をつかさどっているのでした。そのため、いま、過去のデータ
 とARモデル
とARモデル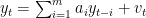 が与えられているとき、とそのARモデルからの推定値
が与えられているとき、とそのARモデルからの推定値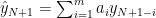 の差は、
の差は、 になります。よって、に関する信頼係数95%の信頼区間は、
になります。よって、に関する信頼係数95%の信頼区間は、
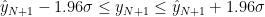
データ分析を実際にする状況では、誤差項
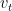 のしたがう確率分布の母分散
のしたがう確率分布の母分散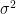 は知ることができません。そのため、最尤推定による推定値
は知ることができません。そのため、最尤推定による推定値 を母分散の近似値として使わざるをえません。この場合、と
を母分散の近似値として使わざるをえません。この場合、と の間にも誤差があるため、正規分布ではなくt分布を持ち出して議論する必要があります。
の間にも誤差があるため、正規分布ではなくt分布を持ち出して議論する必要があります。ただし、この記事では、今後の計算を簡単にするため、以下では
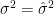 を仮定します。つまり、最尤推定による母分散の推定値が真の母数に等しいとみなして計算を進めることにします。あるいは、母分散が既知であると仮定していると考えてもいいです。
を仮定します。つまり、最尤推定による母分散の推定値が真の母数に等しいとみなして計算を進めることにします。あるいは、母分散が既知であると仮定していると考えてもいいです。
一般の場合(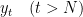 )の誤差分析
)の誤差分析
時刻

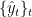
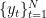




未来の時刻

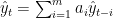
未来の時刻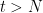


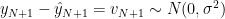

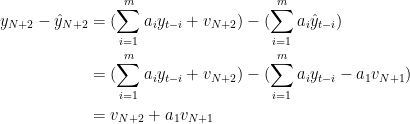

これまで時刻
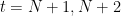 の場合について考察しました。時刻が一般の場合を考えましょう。誤差の確率変数の列
の場合について考察しました。時刻が一般の場合を考えましょう。誤差の確率変数の列 を
を と定義すれば、
と定義すれば、

 であることに注意すると、
であることに注意すると、 は平均
は平均 の正規分布に従い、その分散
の正規分布に従い、その分散 は
は
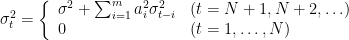
以上より、
に関する95%信頼区間は、上で定義した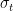 を使って、
を使って、

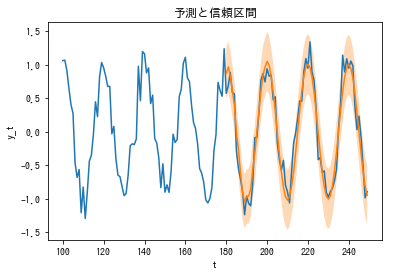
(真の値、予測値、95%信頼区間をプロットしたもの)
まとめ
この記事では、ARモデルの予測の信頼区間を計算しました。ただし、計算にあたって簡単のため誤差項
参考文献
- 北川源四郎『時系列解析入門』
テックブログ新着情報のほか、AWSやGoogle Cloudに関するお役立ち情報を配信中!
Follow @twitter
データ分析と機械学習とソフトウェア開発をしています。 アルゴリズムとデータ構造が好きです。
Recommends
こちらもおすすめ
-

AICによるARモデルのモデル選択
2019.2.28
-

ARモデルの表現能力を考察する
2019.3.1
-

基礎からはじめる時系列解析入門
2019.2.22
-

機械学習の受託案件を通じて気づいた5つのこと
2019.3.8
-

社内マッサージルーム利用状況がパレートの法則にしたがっているかを検証する
2018.9.26
Special Topics
注目記事はこちら

データ分析入門
これから始めるBigQuery基礎知識
2024.02.28

AWSの料金が 10 %割引になる!
『AWSの請求代行リセールサービス』
2024.07.16