S3 Batch Operationsとライフサイクルルール使って、S3のデータの自動削除する処理を実装する

本記事は、NHN テコラス Advent Calendar 2023 11日目の記事です。
この記事ではAmazon S3 Batch Operationsとライフサイクルルールを使ってS3のデータを削除する方法を紹介します。
今回の構成
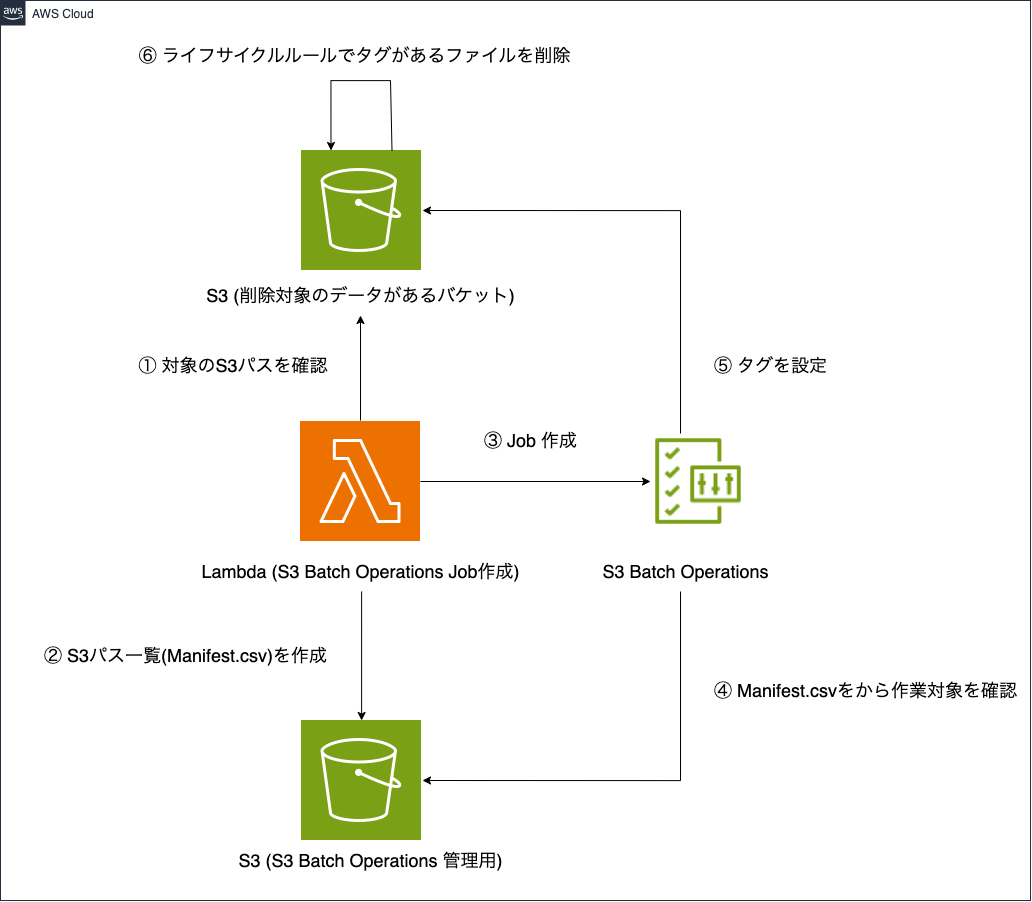
環境情報
OS: MacOS Monterey 12.6.1
言語: Java 17.0.8.1
ツール: AWS SAM 1.100.0
IDE: IntelliJ IDEA 2023.2.4
LambdaはJavaとAWS SAMを使って実装していきます。AWS SAMやInteliJについて今回は詳しく説明しないため、リンク先を参考にしてください。
実装の経緯
S3は非常に便利なオブジェクトストレージですが、コストもそれなりにかかるため費用削減のためにデータを消すことがあります。ですがデータを消そうと思うと意外に大変です。
私たちのチームでは毎月100万件ほどのデータを生成して、毎月1回必要ないデータの削除を行なっています。最初はCLIを作成して、実行前に対象となるデータを調べてからローカルでCLIを実行していました。しかし手動だとミスが発生する可能性も高く、データ量も多いため実行も何十分もかかっていました。
そのため、負担を減らすために処理全体を自動化をすることにしました。その際にS3 Batch Operationsとライフサイクルルールを利用してS3にあるデータの削除を行うことになりました。またロジックを明確にしてコード作成してLambdaから自動で動かせるように実装しました。
今回の記事では最初にS3 Batch Operationsとライフサイクルルールについて簡単に確認した後に、私のチームで行なっている処理を簡略化したものをコードを通して紹介します。S3にあるデータの削除を自動化したいと考えている場合は参考にしてみてください。
Amazon S3 Batch Operations とは何か
対象の一覧をもとにS3のデータをバッチ処理をしてくれるサービスです。対象のデータに対してタグのつけ外しやオブジェクトをコピーをするなどの操作をしてくれます。
何ができるか確認したい場合はS3 バッチ操作でサポートされるオペレーションに書いてあります。
また料金は以下になります(2023年12月現在)。無料ではないので作業前に料金を確認をしてみて下さい。
バッチ操作 – ジョブ: ジョブあたり 0.25USD
バッチ操作 – オブジェクト: 処理された 100 万オブジェクトあたり 1.00USD
バッチ操作 – マニフェスト (オプション): 0.015USD per 1 million objects in the source バケット
※ 以降この記事ではAmazon S3 Batch Operationsはバッチオペレーションと呼びます。
ライフサイクルルール とは何か
指定した条件が満たされるとS3のストレージクラスを変更したり、自動的に削除をしてくれるサービスです。例としてはアップロードして90日後にGlacierに自動で移行する、などがあります。
詳細な情報はストレージのライフサイクルの管理を確認してください。
実装してみる
実際に構成図の内容を実装してみます。以下の手順で進めます。
- リソースを作成する
- テストデータを準備する
- コードを実装する
- Lambdaを実行する
- ライフサイクルルールの結果を確認する
1. リソースを作成する
まずは今回の処理で使われるS3, IAM, Lambdaを作成していきます。
1-1.バッチオペレーション用のバケットを準備
普通のバケットを作ります。
BucketBatchOperation:
Type: 'AWS::S3::Bucket'
Properties:
AccessControl: Private
PublicAccessBlockConfiguration:
BlockPublicAcls: True
BlockPublicPolicy: True
IgnorePublicAcls: True
RestrictPublicBuckets: True
BucketEncryption:
ServerSideEncryptionConfiguration:
- ServerSideEncryptionByDefault:
SSEAlgorithm: AES256
1-2.削除対象が置いてあるバケットを準備する
こちらのバケットにはライフサイクルルールを設定します。
特定のタグがついていると1日後に削除する設定をしておきます。
BucketSource:
Type: 'AWS::S3::Bucket'
Properties:
AccessControl: Private
PublicAccessBlockConfiguration:
BlockPublicAcls: True
BlockPublicPolicy: True
IgnorePublicAcls: True
RestrictPublicBuckets: True
BucketEncryption:
ServerSideEncryptionConfiguration:
- ServerSideEncryptionByDefault:
SSEAlgorithm: AES256
LifecycleConfiguration:
Rules:
- Id: "expire"
Status: "Enabled"
ExpirationInDays: 1
TagFilters:
- Key: delete
Value: yes
1-3.バッチオペレーションが使用するRoleとPolicyを準備する
今回は対象のオブジェクトにタグを作成(更新)する必要があるのでそれに関連する権限を与えます。こちらはAmazon S3 バッチ操作に対するアクセス許可の付与の内容を参考にしています。
S3OperationRole:
Type: AWS::IAM::Role
Properties:
RoleName: s3-batch-operation
AssumeRolePolicyDocument:
Version: "2012-10-17"
Statement:
- Effect: "Allow"
Principal:
Service:
- "batchoperations.s3.amazonaws.com"
Action:
- "sts:AssumeRole"
Path: "/"
ManagedPolicyArns:
- !Ref S3BatchOperationPolicy
S3BatchOperationPolicy:
Type: AWS::IAM::ManagedPolicy
Properties:
PolicyDocument:
Version: '2012-10-17'
Statement:
- Effect: Allow
Action:
- s3:GetObject
- s3:GetObjectVersion
- s3:PutObject
- s3:PutObjectTagging
- s3:PutObjectVersionTagging
Resource:
- !Join
- "/"
- - !GetAtt BucketBatchOperation.Arn
- "*"
- !Join
- "/"
- - !GetAtt BucketSource.Arn
- "*"
1-4.Lambda用のRoleとPolicyを準備する
可能な限り最小の権限にしていますが、開発時はよくわからないエラーで止まっても時間がかかるので最初は大きな権限にすることをお勧めします。こちらもAmazon S3 バッチ操作に対するアクセス許可の付与を参考にしています。
ポイントとしては以下になります。
- LambdaがバッチオペレーションのJobを作成する際にはiam:PassRoleが必須
- Jobの更新やステータスの確認にs3:CreateJob, s3:DescribeJob, s3:UpdateJobStatusが必要
LambdaS3Role:
Type: AWS::IAM::Role
Properties:
RoleName: lambda-default-role
AssumeRolePolicyDocument:
Version: "2012-10-17"
Statement:
- Effect: "Allow"
Principal:
Service:
- "lambda.amazonaws.com"
Action:
- "sts:AssumeRole"
Path: "/"
ManagedPolicyArns:
- !Ref LambdaS3Policy
- arn:aws:iam::aws:policy/service-role/AWSLambdaBasicExecutionRole
LambdaS3Policy:
Type: AWS::IAM::ManagedPolicy
Properties:
PolicyDocument:
Version: '2012-10-17'
Statement:
- Effect: Allow
Action:
- s3:ListBucket
Resource:
- !GetAtt BucketSource.Arn
- !Join
- "/"
- - !GetAtt BucketSource.Arn
- "*"
- Effect: Allow
Action:
- s3:PutObject
Resource:
- !Join
- "/"
- - !GetAtt BucketBatchOperation.Arn
- "*"
- Effect: Allow
Action:
- s3:CreateJob
- s3:DescribeJob
- s3:UpdateJobStatus
Resource:
- !Join
- ""
- - "arn:aws:s3:ap-northeast-1:"
- !Ref AWS::AccountId
- ":job/*"
- Effect: Allow
Action:
- iam:PassRole
Resource:
- !GetAtt S3OperationRole.Arn
1-5.Lambdaを作成する
今回はjava17を使用しています。MemorySizeについてはデータ量に応じて最適な値に設定しなおしてください。
HelloWorldFunction:
Type: AWS::Serverless::Function
Properties:
CodeUri: HelloWorldFunction
Handler: helloworld.App::handleRequest
Runtime: java17
Architectures:
- x86_64
MemorySize: 512
Timeout: 900
Environment:
Variables:
AWS_ACCOUNT_ID: !Ref AWS::AccountId
S3_OPERATION_ROLE_ARN: !GetAtt S3OperationRole.Arn
BUCKET_NAME_S3_OPERATION: !Ref BucketBatchOperation
BUCKET_NAME_SOURCE: !Ref BucketSource
Role: !GetAtt LambdaS3Role.Arn
ここまででリソースの作成は完了しました。
2. テストデータ準備
次にテスト用に0BのデータをS3に作成しておきます。
export DEST_BUCKET_NAME=BucketSourceの名前
export MY_AWS_PROFILE=自分のawsのprofile
touch zero_byte.csv
echo '# start craete dummy'
for count in $(seq -f "%03g" 1 300) ; do
aws s3 cp ./zero_byte.csv s3://${DEST_BUCKET_NAME}/sample-${count}.csv --profile ${MY_AWS_PROFILE}
done
echo '# finish create dummy'
3. Java実装
次にLambdaで実行されるコードをJavaで作成していきます。
3-1. Gradle設定
Gradleの設定します。
plugins {
id 'java'
}
repositories {
mavenCentral()
}
dependencies {
// Lambda
implementation 'com.amazonaws:aws-lambda-java-core:1.2.2'
implementation 'com.amazonaws:aws-lambda-java-events:3.11.0'
// S3
implementation platform('software.amazon.awssdk:bom:2.21.37')
implementation 'software.amazon.awssdk:s3:2.21.37'
implementation 'software.amazon.awssdk:s3control:2.21.37'
// その他
testImplementation 'junit:junit:4.13.2'
implementation 'commons-codec:commons-codec:1.16.0'
}
compileJava {
options.release = 17
}
3-2. S3から対象データを取得する
今回は簡略化のためS3にあるすべてのファイルを対象とします。またバッチオペレーションを使っている時点で対象が多いことが予想されるため、List処理ではページングを考慮した実装をするといいです。
/**
* オブジェクトの一覧を取得する(ページング考慮した実装)
*
* @param bucketName バケット名
* @return オブジェクト一覧
*/
public List<S3Object> listObjectsRequest(String bucketName) {
List<S3Object> result = new ArrayList<S3Object>();
ListObjectsV2Response res = listObjectsWithPaging(bucketName);
result.addAll(res.contents());
while (res.isTruncated()) {
res = listObjectsWithContinuationToken(bucketName, res.nextContinuationToken());
result.addAll(res.contents());
}
return result;
}
/**
* S3のオブジェクト一覧を取得する
*
* @param bucketName バケット名
* @return APIの結果
*/
private ListObjectsV2Response listObjectsWithPaging(String bucketName) {
ListObjectsV2Request listObjects = ListObjectsV2Request.builder()
.bucket(bucketName)
.maxKeys(MAX_REQUEST_NUMBER_S3)
.build();
return s3Client.listObjectsV2(listObjects);
}
/**
* S3のオブジェクト一覧を取得する
*
* @param bucketName バケット名
* @param token トークン
* @return APIの結果
*/
private ListObjectsV2Response listObjectsWithContinuationToken(String bucketName, String token) {
ListObjectsV2Request listObjects = ListObjectsV2Request.builder()
.bucket(bucketName)
.continuationToken(token)
.build();
return s3Client.listObjectsV2(listObjects);
}
3-3. CSVを作成する
バッチオペレーションはCSVで対象の一覧を作成しておき、その表をもとに特定のアクションをするようになっています。ここではLambdaの/tmpにCSVファイルを作成し、このCSVをS3にアップロードします。CSVの例はS3 バッチオペレーションジョブの作成を確認してみて下さい。
ポイントとしては、S3のパス(キー)はURLエンコードをする必要があります。
/**
* 対象のオブジェクトパス一覧を/tmpにCSV形式で作成する。
*
* @param file Lambda内の保存先のファイル(/tmp/**)
* @param targetBucketName 対象のオブジェクトがあるバケット名
* @param objectPathList S3にある対象のオブジェクトのパス一覧
*/
private void createCsvFile(File file, String targetBucketName, List<S3Object> objectPathList) throws IOException {
// CSVを作成する
StringBuilder csvText = new StringBuilder();
// CSV作成
try (BufferedWriter bw = new BufferedWriter(new FileWriter(file, true))) {
for (S3Object target : objectPathList) {
// S3パスはURLエンコードが必須
String encodedKey = URLEncoder.encode(target.key(), StandardCharsets.UTF_8);
// CSV追加
csvText.append(String.format("\"%s\",\"%s\"\n", targetBucketName, encodedKey));
}
// 最後にファイルを追記する
bw.write(csvText.toString());
}
}
3-4. CSVをバッチオペレーション用のバケットに保存する
/**
* 特定のパスにあるオブジェクトをS3に保存する
*
* @param bucketName バケット名
* @param key S3のパス
* @param path 保存したいオブジェクトがあるパス
* @return 結果
*/
public void putObjectFileItem(String bucketName, String key, Path path) {
try {
PutObjectRequest objectRequest = PutObjectRequest.builder()
.bucket(bucketName)
.key(key)
.build();
s3Client.putObject(objectRequest, path);
} catch (Exception ex) {
throw new RuntimeException();
}
}
3-5. バッチオペレーション準備
この時ETagが必要なので、事前に作成しておきます。
/**
* S3BatchOperationのClientを作成
*
* @return Client
*/
private S3Operation s3OperationClient() throws IOException {
// Etag作成
String ETag = createETag();
// S3バッチを起動する
return new S3Operation(
AWS_ACCOUNT_ID,
BUCKET_NAME_S3_OPERATION,
MANIFEST_PATH,
S3_OPERATION_ROLE_ARN,
ETag,
REPORT_PATH,
TAG_KEY,
TAG_VALUE
);
}
/**
* ETagを作成する
*
* @return ETag
*/
private String createETag() throws IOException {
try (InputStream is = Files.newInputStream(Paths.get(TMP_PATH))) {
return DigestUtils.md5Hex(is);
}
}
3-6. バッチオペレーションを実行する
Jobを作成して、ステータスがSuspendedになったらJobを開始します。ステータスについてはジョブステータスと完了レポートの追跡を確認してみて下さい。
Jobの開始して終了するまでの時間はデータ量に依存します。Lambdaだとタイムアウトになる可能性があるので、Jobの終了は待たずに先に進みます。詳細な内部の処理は最後に記載するS3Operation.javaを確認してみて下さい。
/**
* S3バッチオペレーションを実行する
*
* @param s3Operation バッチオペレーションの対象
*/
private void execS3Batch(S3Operation s3Operation) {
// Job作成
String jobId = s3Operation.createBatchJob();
// Jobのステータスチェック
s3Operation.checkJobStatus(jobId);
// Job開始
s3Operation.startJob(jobId); // 実行するとお金がかかる。テストの場合はコメントアウトして実行直前で止めると良い
// 終了時間が未定のため、完了まで待たない
}
4. Lambdaを実行する
ここまでの内容をSAMでデプロイして、Lambdaを実行するとバッチオペレーションのJobが作成されて実行されているはずです。失敗した合計(率)が0%であれば、対象のオブジェクトにタグが付与されているはずです。
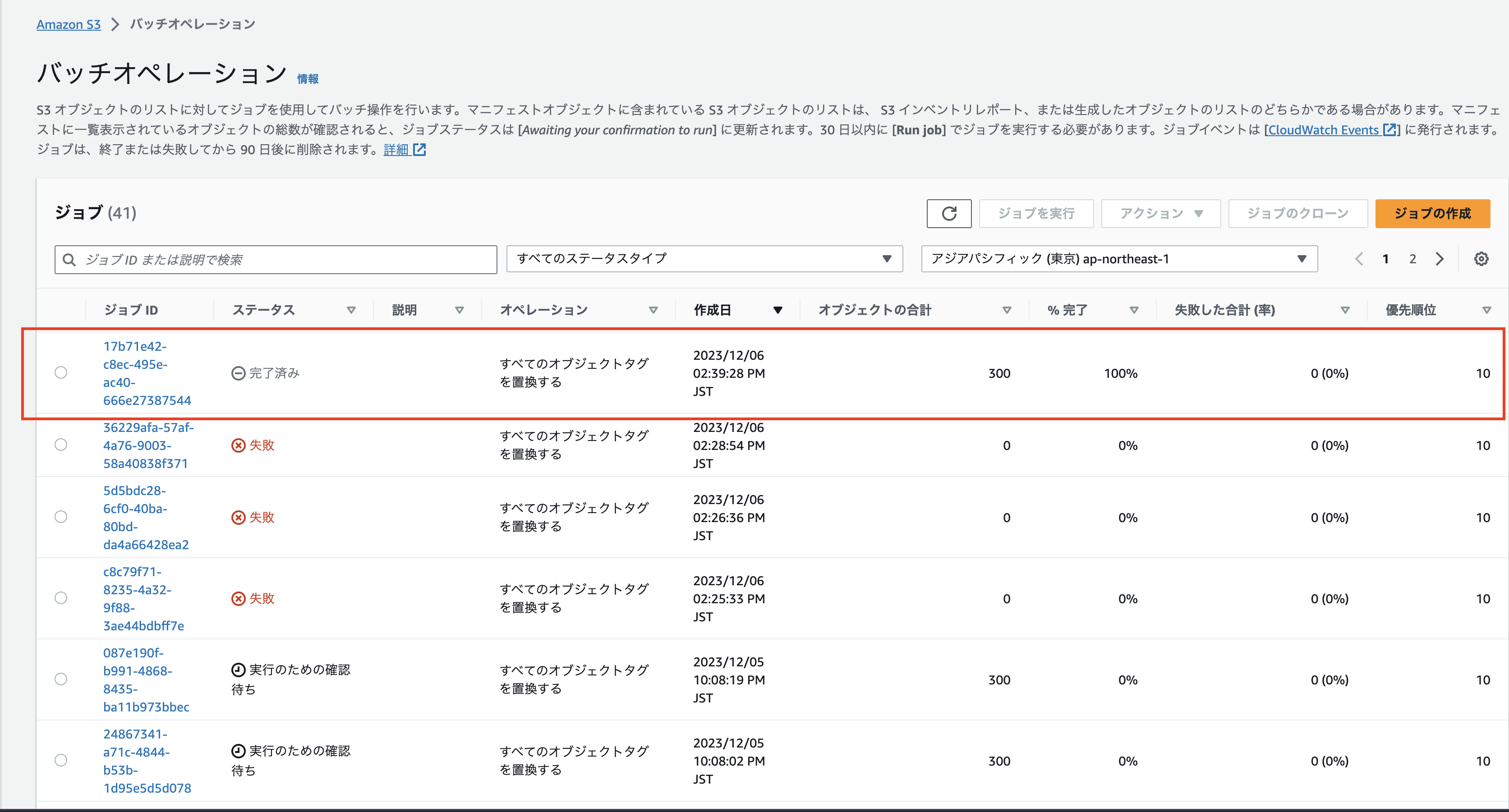
問題がある場合はバッチオペレーションのトラブルシューティングを参考にしてみてください。
5. ライフサイクルルールの結果を確認する
バッチオペレーションはタグを付与するだけでデータの削除は行われません。データの削除はライフサイクルルールの担当になります。
ライフサイクルルールが設定されていて、かつ対象のタグが付与されていれば、24時間後に順次削除されていきます。
Tips
今回は実装をシンプルにするため必要な部分のみを書きました。しかし実際に運用するとなるとほかにも考慮することがあるためいくつか挙げておきます。
S3のListの量を減らす
今回はサンプルであるため、バケットにあるすべてのオブジェクトを対象にしました。しかし毎回S3のバケット全体をListするのにも時間がかかります。またList自体も費用がかかるので、費用が段々と増加していくことになります。
そのためS3のパスを適切に区切ることで、対象の範囲を絞って実行することができます。もしくはListに頼らない設計をするのも手だと思います。
例.
- 削除処理は月に1回ごとに実行する。
- そのためS3のパスをs3://バケット名/year=2023/month=12/ のようにする。
- Lambdaでは特定のyearとmonthのみを対象とするようにコードを書く。
String prefix = String.format("s3://%s/year=%s/month=%s/", bucketName, year, month)
private ListObjectsV2Response listObjectsWithPaging(String bucketName, String prefix) {
ListObjectsV2Request listObjects = ListObjectsV2Request.builder()
.bucket(bucketName)
.prefix(prefix)
.maxKeys(MAX_REQUEST_NUMBER_S3)
.build();
return s3Client.listObjectsV2(listObjects);
}
特定のファイルを残したい場合
今回はサンプルであるため、バケットにあるすべてのオブジェクトを対象にしました。しかし「対象のパスにあるこのファイルだけは残したい」ということがあると思います。この場合、一覧CSVを作成する時にパスに対して正規表現などで判定を行うことで、削除したくないものを省くことができます。
バッチオペレーションをコード化している理由は、このような複雑なパターンに対応するためというのが大きいです。私たちのチームでも特定の年月をバッチオペレーションの対象として、その中から特定のパターンをもつS3パスを除いてManifest.csvを作成しています。
例. s3のパスはs3://バケット名/year=2023/month=12/day=xx/ となっている。この時day=30だけは残したい
// 例外 正規表現
String regexp=".*day=30.*"
Pattern p = Pattern.compile(regexp);
for (S3Object target : objectPathList) {
// 特定のパターンのパスを除外する
Matcher m = p.matcher(target.key());
if (m.matches()) {
continue;
}
// S3パスはURLエンコードが必須
String encodedKey = URLEncoder.encode(target.key(), StandardCharsets.UTF_8);
// CSV追加
csvText.append(String.format("\"%s\",\"%s\"\n", targetBucketName, encodedKey));
}
検証時の費用を抑える
S3バッチオペレーションのJobの実行にはお金がかかります。そのため検証中はジョブの作成まで行い、ジョブの実行前でコメントアウトすると無駄な費用を抑えることができます。
// Job開始 // s3Operation.startJob(jobId);
Lambdaの実行を自動化する
本当の意味で自動化するためにはLambdaを起動する何かが必要になります。私たちのチームでは別の処理のLambdaの処理が完了後に、バッチオペレーション用のLambdaを呼び出しています。
他にはEventBridgeのスケジュール機能を使うということもできます。
# EventBridge 例
CronEventRule:
Type: AWS::Scheduler::Schedule
DependsOn: EventBridgeRole
Properties:
Description: "Execute Lambda"
State: "ENABLED"
ScheduleExpression: cron(0 7 1 * ? *) # 毎月1日7時にLambdaを実行する
ScheduleExpressionTimezone: Asia/Tokyo
Target:
Arn: !GetAtt HelloWorldFunction.Arn
RoleArn: !GetAtt EventBridgeRole.Arn
FlexibleTimeWindow:
Mode: "OFF"
EventBridgeRole:
Type: AWS::IAM::Role
Properties:
RoleName: event-bridge
AssumeRolePolicyDocument:
Version: "2012-10-17"
Statement:
- Effect: "Allow"
Principal:
Service:
- "scheduler.amazonaws.com"
Action:
- "sts:AssumeRole"
Condition:
StringEquals:
aws:SourceAccount: !Ref AWS::AccountId
Path: "/"
ManagedPolicyArns:
- arn:aws:iam::aws:policy/service-role/AWSLambdaRole
まとめ
今回はS3バッチオペレーションとライフサイクルルールを用いたS3のデータ削除方法について、実際のコードと合わせて紹介しました。データの手動やCLIでも実行は可能ですが、バッチオペレーションとライフサイクルをコードから利用することによって複雑なパターンを自動化することが可能になります。
S3は便利なサービスですが、データが溜まってくるとだんだんと費用も大きくなっています。S3のデータ削除を自動化したいなと思った時に、今回の内容が役に立ってもらえれば幸いです。
サンプルコード全体
templata.yaml
AWSTemplateFormatVersion: '2010-09-09'
Transform: AWS::Serverless-2016-10-31
Description: s3-batch-operation-sample
Resources:
# S3
BucketBatchOperation:
Type: 'AWS::S3::Bucket'
Properties:
AccessControl: Private
PublicAccessBlockConfiguration:
BlockPublicAcls: True
BlockPublicPolicy: True
IgnorePublicAcls: True
RestrictPublicBuckets: True
BucketEncryption:
ServerSideEncryptionConfiguration:
- ServerSideEncryptionByDefault:
SSEAlgorithm: AES256
BucketSource:
Type: 'AWS::S3::Bucket'
Properties:
AccessControl: Private
PublicAccessBlockConfiguration:
BlockPublicAcls: True
BlockPublicPolicy: True
IgnorePublicAcls: True
RestrictPublicBuckets: True
BucketEncryption:
ServerSideEncryptionConfiguration:
- ServerSideEncryptionByDefault:
SSEAlgorithm: AES256
LifecycleConfiguration:
Rules:
- Id: "expire"
Status: "Enabled"
ExpirationInDays: 1
TagFilters:
- Key: delete
Value: yes
# Lambda
HelloWorldFunction:
Type: AWS::Serverless::Function
Properties:
CodeUri: HelloWorldFunction
Handler: helloworld.App::handleRequest
Runtime: java17
Architectures:
- x86_64
MemorySize: 512
Timeout: 900
Environment:
Variables:
AWS_ACCOUNT_ID: !Ref AWS::AccountId
S3_OPERATION_ROLE_ARN: !GetAtt S3OperationRole.Arn
BUCKET_NAME_S3_OPERATION: !Ref BucketBatchOperation
BUCKET_NAME_SOURCE: !Ref BucketSource
Role: !GetAtt LambdaS3Role.Arn
# IAM Role
LambdaS3Role:
Type: AWS::IAM::Role
Properties:
RoleName: lambda-default-role
AssumeRolePolicyDocument:
Version: "2012-10-17"
Statement:
- Effect: "Allow"
Principal:
Service:
- "lambda.amazonaws.com"
Action:
- "sts:AssumeRole"
Path: "/"
ManagedPolicyArns:
- !Ref LambdaS3Policy
- arn:aws:iam::aws:policy/service-role/AWSLambdaBasicExecutionRole
LambdaS3Policy:
Type: AWS::IAM::ManagedPolicy
Properties:
PolicyDocument:
Version: '2012-10-17'
Statement:
- Effect: Allow
Action:
- s3:ListBucket
Resource:
- !GetAtt BucketSource.Arn
- !Join
- "/"
- - !GetAtt BucketSource.Arn
- "*"
- Effect: Allow
Action:
- s3:PutObject
Resource:
- !Join
- "/"
- - !GetAtt BucketBatchOperation.Arn
- "*"
- Effect: Allow
Action:
- s3:CreateJob
- s3:DescribeJob
- s3:UpdateJobStatus
Resource:
- !Join
- ""
- - "arn:aws:s3:ap-northeast-1:"
- !Ref AWS::AccountId
- ":job/*"
- Effect: Allow
Action:
- iam:PassRole
Resource:
- !GetAtt S3OperationRole.Arn
S3OperationRole:
Type: AWS::IAM::Role
Properties:
RoleName: s3-batch-operation
AssumeRolePolicyDocument:
Version: "2012-10-17"
Statement:
- Effect: "Allow"
Principal:
Service:
- "batchoperations.s3.amazonaws.com"
Action:
- "sts:AssumeRole"
Path: "/"
ManagedPolicyArns:
- !Ref S3BatchOperationPolicy
S3BatchOperationPolicy:
Type: AWS::IAM::ManagedPolicy
Properties:
PolicyDocument:
Version: '2012-10-17'
Statement:
- Effect: Allow
Action:
- s3:GetObject
- s3:GetObjectVersion
- s3:PutObject
- s3:PutObjectTagging
- s3:PutObjectVersionTagging
Resource:
- !Join
- "/"
- - !GetAtt BucketBatchOperation.Arn
- "*"
- !Join
- "/"
- - !GetAtt BucketSource.Arn
- "*"
build.gradle
plugins {
id 'java'
}
repositories {
mavenCentral()
}
dependencies {
// Lambda
implementation 'com.amazonaws:aws-lambda-java-core:1.2.2'
implementation 'com.amazonaws:aws-lambda-java-events:3.11.0'
// S3
implementation platform('software.amazon.awssdk:bom:2.21.37')
implementation 'software.amazon.awssdk:s3:2.21.37'
implementation 'software.amazon.awssdk:s3control:2.21.37'
// その他
testImplementation 'junit:junit:4.13.2'
implementation 'commons-codec:commons-codec:1.16.0'
}
compileJava {
options.release = 17
}
App.java
package helloworld;
import java.io.BufferedWriter;
import java.io.File;
import java.io.FileWriter;
import java.io.IOException;
import java.io.InputStream;
import java.net.URLEncoder;
import java.nio.charset.StandardCharsets;
import java.nio.file.Files;
import java.nio.file.Paths;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
import org.apache.commons.codec.digest.DigestUtils;
import com.amazonaws.services.lambda.runtime.Context;
import com.amazonaws.services.lambda.runtime.RequestHandler;
import software.amazon.awssdk.services.s3.model.S3Object;
public class App implements RequestHandler<Map<String, String>, Map<String, String>> {
// 定数
final String TMP_PATH = "/tmp/output.csv"; // Lambdaのtmpファイルのパス。一時的に保存する場所なのでなんでもいい。
final String MANIFEST_PATH = "operation/manifest.csv"; // S3Operationのmanifestファイルの出力先
final String REPORT_PATH = "operation/report"; // S3Operationの結果の保存先
final String TAG_KEY = "delete";
final String TAG_VALUE = "yes";
// 環境変数
final String AWS_ACCOUNT_ID = System.getenv("AWS_ACCOUNT_ID");;
final String S3_OPERATION_ROLE_ARN = System.getenv("S3_OPERATION_ROLE_ARN");;
final String BUCKET_NAME_S3_OPERATION = System.getenv("BUCKET_NAME_S3_OPERATION");
final String BUCKET_NAME_SOURCE = System.getenv("BUCKET_NAME_SOURCE");
public Map<String, String> handleRequest(Map<String, String> event, Context context) {
try {
// 準備
S3 s3 = new S3();
// tmpファイル作成
File file = new File(TMP_PATH);
// S3の対象のオブジェクト一覧取得
List<S3Object> s3ContentList = s3.listObjectsRequest(BUCKET_NAME_SOURCE);
// /tmpにManifestファイル作成
createCsvFile(file, BUCKET_NAME_SOURCE, s3ContentList);
// S3にBatchOperation用のCSVを保存する
s3.putObjectFileItem(BUCKET_NAME_S3_OPERATION, MANIFEST_PATH, file.toPath());
// client作成
S3Operation s3Operation = s3OperationClient();
// Job実行
execS3Batch(s3Operation);
// tmpの削除
file.delete();
return createReturnItem();
} catch (IOException e) {
throw new RuntimeException(e);
}
}
/**
* 対象のオブジェクトパス一覧を/tmpにCSV形式で作成する。
*
* @param file Lambda内の保存先のファイル(/tmp/**)
* @param targetBucketName 対象のオブジェクトがあるバケット名
* @param objectPathList S3にある対象のオブジェクトのパス一覧
*/
private void createCsvFile(File file, String targetBucketName, List<S3Object> objectPathList) throws IOException {
// CSVを作成する
StringBuilder csvText = new StringBuilder();
// CSV作成
try (BufferedWriter bw = new BufferedWriter(new FileWriter(file, true))) {
for (S3Object target : objectPathList) {
// S3パスはURLエンコードが必須
String encodedKey = URLEncoder.encode(target.key(), StandardCharsets.UTF_8);
// CSV追加
csvText.append(String.format("\"%s\",\"%s\"\n", targetBucketName, encodedKey));
}
// 最後にファイルを追記する
bw.write(csvText.toString());
}
}
/**
* S3BatchOperationのClientを作成
*
* @return Client
*/
private S3Operation s3OperationClient() throws IOException {
// Etag作成
String ETag = createETag();
// S3バッチを起動する
return new S3Operation(
AWS_ACCOUNT_ID,
BUCKET_NAME_S3_OPERATION,
MANIFEST_PATH,
S3_OPERATION_ROLE_ARN,
ETag,
REPORT_PATH,
TAG_KEY,
TAG_VALUE
);
}
/**
* ETagを作成する
*
* @return ETag
*/
private String createETag() throws IOException {
try (InputStream is = Files.newInputStream(Paths.get(TMP_PATH))) {
return DigestUtils.md5Hex(is);
}
}
/**
* S3バッチオペレーションを実行する
*
* @param s3Operation バッチオペレーションの対象
*/
private void execS3Batch(S3Operation s3Operation) {
// Job作成
String jobId = s3Operation.createBatchJob();
// Jobのステータスチェック
s3Operation.checkJobStatus(jobId);
// Job開始
// s3Operation.startJob(jobId); // 実行するとお金がかかる。テストの場合は、コメントアウトして実行直前で止めると良い
// 終了時間が未定のため、完了まで待たない
}
private Map<String, String> createReturnItem() {
Map<String, String> item = new HashMap<>();
item.put("message", "success!");
return item;
}
}
S3.java
package helloworld;
import java.nio.file.Path;
import java.util.ArrayList;
import java.util.List;
import software.amazon.awssdk.regions.Region;
import software.amazon.awssdk.services.s3.S3Client;
import software.amazon.awssdk.services.s3.model.ListObjectsV2Request;
import software.amazon.awssdk.services.s3.model.ListObjectsV2Response;
import software.amazon.awssdk.services.s3.model.PutObjectRequest;
import software.amazon.awssdk.services.s3.model.PutObjectResponse;
import software.amazon.awssdk.services.s3.model.S3Object;
public class S3 {
S3Client s3Client;
/**
* 最大リクエスト数
*/
public static final Integer MAX_REQUEST_NUMBER_S3 = 1000;
public S3() {
s3Client = S3Client.builder()
.region(Region.AP_NORTHEAST_1)
.build();
}
/**
* 特定のパスにあるオブジェクトをS3に保存する
*
* @param bucketName バケット名
* @param key S3のパス
* @param path 保存したいオブジェクトがあるパス
* @return 結果
*/
public void putObjectFileItem(String bucketName, String key, Path path) {
try {
PutObjectRequest objectRequest = PutObjectRequest.builder()
.bucket(bucketName)
.key(key)
.build();
PutObjectResponse objectResponse = s3Client.putObject(objectRequest, path);
} catch (Exception ex) {
throw new RuntimeException();
}
}
/**
* オブジェクトの一覧を取得する(ページング考慮した実装)
*
* @param bucketName バケット名
* @return オブジェクト一覧
*/
public List<S3Object> listObjectsRequest(String bucketName) {
List<S3Object> result = new ArrayList<S3Object>();
ListObjectsV2Response res = listObjectsWithPaging(bucketName);
result.addAll(res.contents());
while (res.isTruncated()) {
res = listObjectsWithContinuationToken(bucketName, res.nextContinuationToken());
result.addAll(res.contents());
}
return result;
}
/**
* S3のオブジェクト一覧を取得する
*
* @param bucketName バケット名
* @return APIの結果
*/
private ListObjectsV2Response listObjectsWithPaging(String bucketName) {
ListObjectsV2Request listObjects = ListObjectsV2Request.builder()
.bucket(bucketName)
.maxKeys(MAX_REQUEST_NUMBER_S3)
.build();
return s3Client.listObjectsV2(listObjects);
}
/**
* S3のオブジェクト一覧を取得する
*
* @param bucketName バケット名
* @param token トークン
* @return APIの結果
*/
private ListObjectsV2Response listObjectsWithContinuationToken(String bucketName, String token) {
ListObjectsV2Request listObjects = ListObjectsV2Request.builder()
.bucket(bucketName)
.continuationToken(token)
.build();
return s3Client.listObjectsV2(listObjects);
}
}
S3Operation.java
package helloworld;
import java.util.ArrayList;
import java.util.List;
import java.util.UUID;
import software.amazon.awssdk.services.s3control.model.DescribeJobResponse;
import software.amazon.awssdk.services.s3control.model.S3Tag;
import software.amazon.awssdk.services.s3control.model.JobOperation;
import software.amazon.awssdk.services.s3control.model.S3SetObjectTaggingOperation;
import software.amazon.awssdk.services.s3control.model.JobManifest;
import software.amazon.awssdk.services.s3control.model.JobManifestSpec;
import software.amazon.awssdk.services.s3control.model.JobManifestFormat;
import software.amazon.awssdk.services.s3control.model.JobManifestFieldName;
import software.amazon.awssdk.services.s3control.model.JobManifestLocation;
import software.amazon.awssdk.services.s3control.model.JobReport;
import software.amazon.awssdk.services.s3control.model.JobReportFormat;
import software.amazon.awssdk.services.s3control.model.JobReportScope;
import software.amazon.awssdk.services.s3control.S3ControlClient;
import software.amazon.awssdk.services.s3control.model.CreateJobRequest;
import software.amazon.awssdk.services.s3control.model.CreateJobResponse;
import software.amazon.awssdk.services.s3control.model.DescribeJobRequest;
import software.amazon.awssdk.services.s3control.model.JobStatus;
import software.amazon.awssdk.services.s3control.model.UpdateJobStatusRequest;
import software.amazon.awssdk.services.s3control.model.RequestedJobStatus;
import software.amazon.awssdk.regions.Region;
public class S3Operation {
private final S3ControlClient s3ControlClient;
private final String awsAccountId;
private final String bucketArn;
private final String manifestArn;
private final String roleArn;
private final String ETag;
private final String reportPath;
private final String tagKey;
private final String tagValue;
public S3Operation(
String awsAccountId,
String bucketName,
String manifestFilePath,
String roleArn,
String ETag,
String reportPath,
String tagKey,
String tagValue
) {
// Client作成
this.s3ControlClient = S3ControlClient.builder()
.region(Region.AP_NORTHEAST_1)
.build();
// パラメータ準備
this.awsAccountId = awsAccountId;
this.bucketArn = String.format("arn:aws:s3:::%s", bucketName);
this.manifestArn = String.format("%s/%s", this.bucketArn, manifestFilePath);
this.roleArn = roleArn;
this.ETag = ETag;
this.reportPath = reportPath;
this.tagKey = tagKey;
this.tagValue = tagValue;
}
public String createBatchJob() {
// 対象のタグを作成
ArrayList<S3Tag> tagSet = new ArrayList<S3Tag>();
S3Tag tags = S3Tag.builder().key(tagKey).value(tagValue).build();
tagSet.add(tags);
// S3バッチで実行する内容を設定 => タグを付与する
S3SetObjectTaggingOperation s3SetObjectTaggingOperation = S3SetObjectTaggingOperation.builder().tagSet(tagSet).build();
JobOperation jobOperation = JobOperation.builder().s3PutObjectTagging(s3SetObjectTaggingOperation).build();
// 削除対象のCSVの構造を設定する
// => データ形式: CSV, データ構造: Bucket,Key
List<JobManifestFieldName> JobManifestFieldNameList = new ArrayList<JobManifestFieldName>() {
{
add(JobManifestFieldName.BUCKET);
add(JobManifestFieldName.KEY);
}
};
JobManifestSpec jobManifestSpec = JobManifestSpec.builder()
.format(JobManifestFormat.S3_BATCH_OPERATIONS_CSV_20180820)
.fields(JobManifestFieldNameList)
.build();
// 削除対象のCSVの情報の場所を設定する
JobManifestLocation jobManifestLocation = JobManifestLocation.builder().objectArn(manifestArn).eTag(ETag).build();
// Manifestの情報を作成する
JobManifest jobManifest = JobManifest.builder().spec(jobManifestSpec).location(jobManifestLocation).build();
// 完了、失敗した際のレポートの保存方法を設定する
JobReport jobReport = JobReport.builder()
.bucket(bucketArn)
.prefix(reportPath)
.format(JobReportFormat.REPORT_CSV_20180820)
.enabled(true)
.reportScope(JobReportScope.ALL_TASKS)
.build();
// S3バッチを実行する
String uuid = UUID.randomUUID().toString();
CreateJobRequest createJobRequest = CreateJobRequest.builder()
.accountId(awsAccountId)
.operation(jobOperation)
.manifest(jobManifest)
.report(jobReport)
.priority(10)
.roleArn(roleArn)
.clientRequestToken(uuid)
.build();
// 実行
CreateJobResponse response = s3ControlClient.createJob(createJobRequest);
System.out.println(response.jobId());
return response.jobId();
}
public Boolean checkJobStatus(String jobId) {
// Client作成
DescribeJobRequest describeJobRequest = DescribeJobRequest.builder()
.accountId(awsAccountId)
.jobId(jobId)
.build();
DescribeJobResponse response = s3ControlClient.describeJob(describeJobRequest);
// ステータスチェック
while (response.job().status() != JobStatus.SUSPENDED) {
// ステータス表示
System.out.println(response.job().status());
if (response.job().status() == JobStatus.FAILED) {
throw new RuntimeException();
}
System.out.println("wait 5 second");
try {
Thread.sleep(5000);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
response = s3ControlClient.describeJob(describeJobRequest);
}
System.out.println(response.job().status());
return true;
}
public void startJob(String jobId) {
UpdateJobStatusRequest updateJobStatusRequest = UpdateJobStatusRequest.builder()
.accountId(awsAccountId)
.jobId(jobId)
.requestedJobStatus(RequestedJobStatus.READY)
.build();
s3ControlClient.updateJobStatus(updateJobStatusRequest);
}
}

2018年新卒入社。エンジニア。フロントエンド&サーバサイドを担当。 Vue.js, Ruby on Rails, Ruby, Javaを主に使用する。 会社では全力で働き、家では全力で遊ぶ。


Recommends
こちらもおすすめ
-

AWS初心者におすすめの勉強法と運用のポイント
2019.5.30
-

【Amazon Route53】AWS CLIで特定文字列レコードを抽出してみた
2023.12.5




Special Topics
注目記事はこちら

データ分析入門
これから始めるBigQuery基礎知識
2024.02.28

AWSの料金が 10 %割引になる!
『AWSの請求代行リセールサービス』
2024.07.16