機械学習 曲線フィッテングについて 後編
2016.4.13

一ヶ月ぶりの更新となってしまいました。
橘です。
今後しばらくはペースアップを図って行きます!
さて、前回は曲線フィッティングをを実際に見ていきました。
前回までの内容をざっとまとめると、
- 目的は、「過去のデータにフィットするような曲線を引き、新たなデータを予測したい
- 曲線は、多項式
で表すことができる
- 多項式のnの値を増やすことで、曲線をたくさん曲げることができ、より過去のデータにフィットした線を引くことができる
というものでした。
今回は曲線フィッティングのメリット・デメリットと数学的背景をご紹介します。
曲線フィッティングのメリット・デメリット
曲線フィッティングのメリットをさらっと挙げると
- 機械学習で使われる手法の中では比較的簡単に実装できる
- 簡単な割には使われる場面が多い
という点です。しかし、どちらかというとデメリットの方が重要です。
- データが少ないと思うように予測できるいい曲線が引けない
- 不用意に多項式のnを増やし過ぎると過学習が起こる
- 曲線の係数{
}を求める計算に時間がかかる
1つずつ説明していきます。
1. データが少ないと思うように予測できるいい曲線が引けない
次のGIFアニメをご覧ください。

元々予測したいデータの個数が少ないと、曲線の引き方がかなり自由になってしまい、思ったような曲線を引くことができなくなってしまいます。
これは機械学習全般にいえることですが、データは多いにこしたことはありません。
2. 不用意に多項式のn を増やし過ぎると過学習が起こる
詳細は後ほどの数学的背景で述べますが、前回と今回の冒頭でご説明した通り、多項式のnを増やすことで曲線の曲げる数を増やすことができます。であれば増やせば増やすほどよさそうなものですが、「過ぎたるは及ばざるが如し」で、過学習と呼ばれる現象が起こります。
過学習とは、「1. データが少ないと思うように予測できるいい曲線が引けない」ではデータの個数が少なすぎて曲線が自由になってしまいましたが、
その逆で曲線を曲げる回数を増やしすぎることで、曲線が束縛されてしまう起こる現象です。
またGIFアニメで見てみましょう。

曲げる回数に束縛されてしまい、予測したいデータが予測できないことがわかるかと思います。データがたくさんある場合、なるべく多くのデータを通るような曲線を描きたくなりますが、多ければいいというものではありません。適切なnを見つけることが大事です。
「3. 計算量が増えてしまう」に関しては、数学的背景でご紹介することにします。
曲線フィッティングの数学的背景について
ここからやっと、数学の話です。前にご紹介した微分の話や行列の話を復習しつつ、ご紹介していきます。
曲線
曲線に関しては、今まで通りの多項式で表していきます。

誤差関数
曲線フィッティングのそもそもの目的を今一度思い出すと、目的に焦点を絞れば
(i) 適当な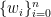
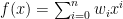
(ii) 過去のデータから計算して、曲線の係数{
(iii) (ii)で決めたa_{i}を曲線の多項式に代入して曲線を変形させる
でした。(くどいようですが、多項式に不安を感じる方は機械学習を学ぶための準備 その2(級数と積分について)をご覧ください。)
(i)で適当な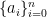

ごちゃごちゃしていますが、「実データ(赤)のy座標
実データの真上か真下にある曲線のy座標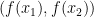
M個のデータに関してそれぞれの誤差を二乗して足しあわせたものが「誤差関数」、今回の場合は「二乗誤差」といいます。なぜ二乗するかというと、実データと曲線がどちらが上にあるかによって誤差がプラス/マイナスが反転してしまうため、誤差をプラスにそろえるために2乗します。 最後に、あとで計算を楽にするために、すべての誤差を足しあわせたものを2で割ります。
上の図で見たように、ただ「データと曲線にどれだけ差があるか」を見ているにすぎません。
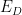
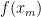
という形でした。これを

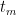
さて、遡ること4ヶ月前、当テックブログで微分について書きました。そこで
「関数がある点で最大値、もしくは最小値を取るとき、その点で微分した値は0になる」
という事実についてお話ししました。上の事実を適用すると、
「誤差関数がある
ということになります。この事実を使うことで、誤差関数が最も小さくなる
今回は、



誤差関数が最小となる曲線の係数wの求め方
いきなり行列が出てきていたりしていますが、以下がwの求め方です。

一見複雑に見えますが、実際に複雑です。。。が、計算結果だけを求めたいのであれば、前回利用したPythonのscikit-learnライブラリを使うことで、wの値をすぐに求めることができます。このwの値を取得することで、ようやく曲線を描くことができます。
実際にコードで書いてみる
前回はscikit-learnライブラリで結果だけを求めましたが、今回は自力で最小二乗法による曲線フィッティングを書いてみました。上述の通り、コードの具体的な説明は次回行います。
umentu/least_square
※ソースコードの改変、再配布は認めますが、一切の責任は持たないことをご了承して頂いた上でご利用下さい。
環境に関しては、前回の通りこちらをごらんください。また、わからない場合はFacebookでお気軽にご相談ください。
#! -*- coding: utf-8 -*-
import numpy as np
import scipy as sp
import matplotlib.pyplot as plt
import pandas as pd
from pandas import Series, DataFrame
from numpy.random import normal
def create_dataset(tsv):
data_set = DataFrame(columns=["x", "t"])
data = sp.genfromtxt(tsv, delimiter=",")
for d in data:
data_set = data_set.append(Series(d, index=["x", "t"]),ignore_index=True)
return data_set
def least_square(dataset, n):
"""
最小二乗法で解を求める
"""
# phi を求める
phi = DataFrame()
for i in range(0,n+1):
p = dataset.x**i
p.name = "x**{0}".format(i)
phi = pd.concat([phi,p], axis=1)
w = np.dot(np.dot(np.linalg.inv(np.dot(phi.T, phi)), phi.T), dataset.t)
def f(x):
y = 0
for i, wt in enumerate(w):
y += wt * (x ** i)
return y
return (f, w)
if __name__ == '__main__':
# 訓練データ作成
train_data = create_dataset("./access_data.csv")
# テストデータ作成
test_data = create_dataset("./access_data.csv")
N = 5
(f, w) = least_square(train_data, N)
plt.scatter(test_data.x, f(test_data.x))
plt.scatter(test_data.x, test_data.t)
plt.show()
以下がコードの実行結果です。

なんとなくフィッティングしている感じがしますね。
次回予告
次回は、おまけ編として、今回求めたwの証明と、機械学習を始めた時に陥りがちな、どのようにしてコードに落とし込むかの方法をご紹介したいと思います。
次回まではかなりゆっくり進めていきますが、次回以降は1テーマ1回分で更新していく予定です。
お疲れ様でした。
テックブログ新着情報のほか、AWSやGoogle Cloudに関するお役立ち情報を配信中!
Follow @twitter
AWSを中心としたクラウドインフラやオンプレミス、ビッグデータ、機械学習などの技術ネタを中心にご紹介します。
Recommends
こちらもおすすめ
-

BERTの学習済みモデルを使ってみる
2018.11.9
-

AWS無料セミナー開催レポート | 大人気のAWS入門セミナー
2018.11.17
-

機械学習 曲線フィッテングについて おまけ?編
2016.4.28
-

Pythonで実装する画像認識アルゴリズム SLIC 入門
2018.2.13


Special Topics
注目記事はこちら

データ分析入門
これから始めるBigQuery基礎知識
2024.02.28

AWSの料金が 8 %割引になる!
『AWSの請求代行リセールサービス』
2023.01.15