[AWS re:Invent 2024] How startups can create disruptive innovations with gen AI on AWS (GBL201)

はじめに
こんにちは。kisaragi です!
この記事では、AWS re:Invent 2024 で参加したセッションについて紹介します。
今回は、スタートアップ企業が AWS の 生成 AI でどうやって革新を起こしているかについての内容です。
セッション概要
タイトル
(和訳)
このセッションは韓国語で進行されます。スタートアップがエンタープライズ顧客向けの独自のFoundationモデルの提供から、エンドユーザー向けのコンテンツ生成に至るまで、多様な生成AIタスクのニーズを持っていることに注目します。本セッションでは、スタートアップがAWSを活用して生成AIを通じてどのようにイノベーションを達成できるかを探ります。UpstageのSolarモデルがAmazon SageMakerを通じて100%事前学習され、AWS Marketplaceを活用してグローバル顧客が簡単に独自のFine-tuningモデルを構築できる方法について紹介します。また、MiridihのMiriCanvasがAmazon BedrockとLangGraphを活用したプロンプトチェイニングによって、AIプレゼンテーション生成などのAIベースのクリエイティブデザイン機能を提供し、さらにAmazon OpenSearch Serviceを利用して4千万件以上のベクトルデータを基に類似のデザインテンプレートを推薦する方法についても解説します。
出典:AWS re:Invent 2024 – How startups can create disruptive innovations with gen AI on AWS (GBL201)
スピーカー
- AWS – Youngjoon Choi (AI/ML Expert Principal SA)
- Upstage – Stan Lee (CTO)
- MIRIDIH – Heekyu Kim (CTO)
生成 AI の重要な要素
データ処理の進化
過去には、製品、顧客、金融取引、価格、医療データといった構造化データに主に焦点が当てられていました。しかし最近では、画像、文書、動画といった非構造化データも積極的に活用できる環境が整備されつつあります。
特に、AWSは生成AIアプリケーション開発の重要な要素の一つであるベクトル検索(Vector Search)機能を、OpenSearch Serviceをはじめとするさまざまなサービスで提供しており、非構造化データの活用をさらに拡大しています。
AWS Foundation Model : 生成 AI を活用する2つの方法
AWSは、生成AIサービスを活用できる2つの主要なプラットフォームを提供しています。
- Amazon Bedrock
Amazon Bedrockは、業界トップのAI企業が開発した基盤モデル(Foundation Model)をサーバーレス方式で簡単に活用できるプラットフォームです。インフラ管理を必要とせず、柔軟かつ迅速な開発環境を提供します。 - Amazon SageMaker JumpStart
Amazon SageMaker JumpStartを利用すると、さまざまなモデルプロバイダーが提供する生成AIモデルやデータ前処理モデルを、サーバーベースの環境で設定して活用できます。このプラットフォームは、データ準備からモデルの学習およびデプロイに至るまで幅広くサポートし、エンドツーエンドのAIワークフローを最適化します。
生成 AI 発展ロードマップ
生成AIは、初期のシンプルな質疑応答中心の構造から始まり、徐々に進化を重ねながら新しい手法を取り入れてきました。
- プロンプトエンジニアリング
初期段階では、プロンプトエンジニアリングの手法により、簡単な質疑応答が主な活用事例でした。この方法は、ユーザーが入力した質問に対してAIが直接回答を生成するというシンプルな構造で、生成AIの基本的な活用方法です。 - RAG (Retrieval-Augmented Generation)
その後、応答の正確性や信頼性を向上させるために、RAG(Retrieval-Augmented Generation)という手法が注目され始めました。この方法は、知識ベースやデータベースから関連情報を検索し、それを基により信頼性の高い回答を提供することで、単純な生成AIモデルの限界を克服する手段となっています。 - エージェント方式
最近では、複雑な作業やワークフローを処理できるエージェント方式へと進化しています。この方式では、さまざまな役割を持つエージェントが思考や検討を繰り返し行い、最終的な回答の品質を大幅に向上させることが可能です。
Fine-tuning : 効率的な性能向上の鍵
Foundation モデルを基盤としたFine-tuningがトレンドとして浮上しています。Fine-tuningを活用することで、各段階でモデルの性能をコスト効率よく向上させることが可能となり、ユーザーに最適化された結果を提供する上で大きな強みを発揮します。
FOUNDATION MODELの革新事例 : Upstage
Document AI = 非構造化データを構造化データに変換する革新的技術
Document AIとは何か?
Document AIは、非構造化データを構造化データに変換する技術です。従来のOCR(光学文字認識)技術の限界を超え、文書から主要な情報を自動的に抽出し、自然言語処理を可能にします。単に画像内のテキストを認識するだけでなく、文書の内容をキーと値のペア(Key-Valueペア)として整理してデータ化する点が特徴です。
Document AIがもたらした変化
従来は、文書処理を行う際に人が文書の種類を直接確認し、必要な情報を手作業で入力してデータを整理していました。しかし、Document AIを活用することで、以下のプロセスを自動化できます。
- 文書の種類を自動的に分類
- 文書内の主要情報をKey-Value形式で抽出および保存
これにより、手作業に比べて大幅に高い精度を維持しつつ、人件費を大幅に削減できるとされています。
Document AIの実際の活用例:保険会社の成功事例
ある保険会社では、Document AIを導入し、過去10年間に蓄積された文書をデータ化することに成功しました。それまでリソース不足で分析されなかった資料をデータベース化した結果、以下のような付加価値を生み出しました。
- データ分析を基にした新しいがん保険商品の開発
- 既存データを活用した顧客向けカスタマイズサービスの提供
Embeddingモデル:Solar Embeddingの強み
Embeddingモデルは、非構造化テキストデータをベクトルデータに変換し、多様な分析や活用を可能にする重要な技術です。最近、Upstate社が開発したSolar Embeddingモデルは、OpenAIのEmbeddingモデルと比較して、日本語、韓国語、英語において優れた性能を示したと評価されています。
特に、非構造化テキストデータをベクトルに変換した後、RAG(Retrieval-Augmented Generation)方式を使用するユースケースでは、Solar Embeddingがより正確な処理を可能にします。これは、データの言語的特性をより適切に反映し、複雑な質疑応答や文書検索などのタスクで優れた結果を提供するためです。
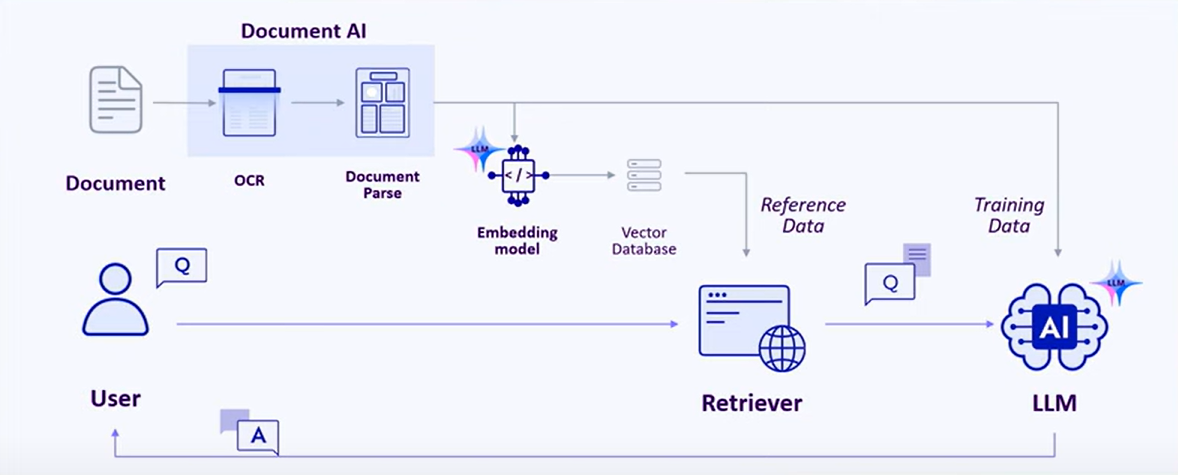
Document AIとLLMの組み合わせ:データ処理への新たなアプローチ
Document AIとLLM(Large Language Model)の組み合わせは、非構造化テキストデータをさらに効果的に処理するための新たな可能性を提示しています。Document Parseエンジンを活用して文書をMarkdownやHTML形式に解析し、それをLLMが処理できる形式に変換する方法です。これにより、顧客データが非構造化テキスト形式であっても高精度で処理できる環境が提供されています。
Document Parseエンジンの効果
Document Parseエンジンを使用して生成したMarkdown形式のデータを活用し、モデルをFine-tuningした結果、LLM(Large Language Model)の性能が向上したとされています。これは、データの前処理プロセスにおいてDocument Parseエンジンが重要な役割を果たしていることを示しています。正確なデータ前処理はモデルの性能に大きな影響を与え、特に複雑な文書構造を扱う場合において非常に有用です。
このようにパイプラインを構築することで、LLMのハルシネーション現象を減少させる取り組みが進められているとのことです。
FOUNDATION MODELとしての革新の提供
現在、Amazon SageMaker JumpStartを通じて、Upstageが開発したSolarモデルを利用することができます。
特に日本語と韓国語の処理において優れた性能を発揮するらしいので、一度活用してみたいと思います!
生成 AI サービスの革新事例:MIRIDIH
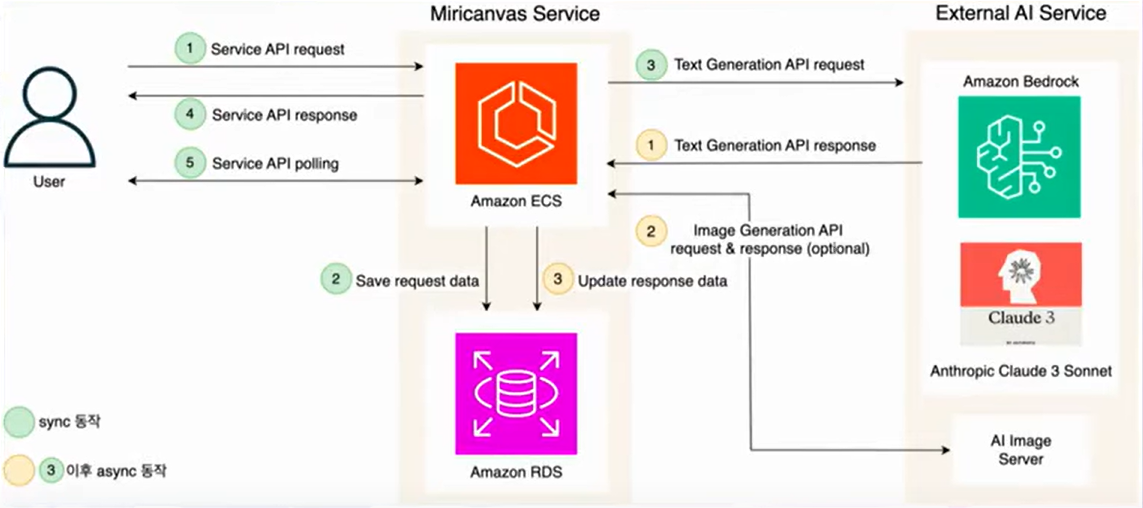
AWS アーキテクチャ
Sync動作
- クライアントがサーバーに生成リクエストを送信します。
- リクエスト情報をAmazon RDSに保存し、状態を管理します。
- サーバーがAmazon Bedrockにテキスト生成リクエストを送信します。
- リクエスト処理は非同期で行われるため、サーバーはクライアントに即座にAPIレスポンスを返します。
- その後、クライアントはサーバーに一定間隔でポーリングリクエストを送信し、結果を確認します。
Async動作
- Amazon Bedrockでテキスト生成が完了すると、結果がサーバーに返されます。
- サーバーは追加の画像生成が必要な場合、画像生成サーバーにリクエストを送信します。
- すべての生成結果はAmazon RDSに保存されます。
- クライアントは保存された結果をサーバーから取得し、活用できます。
実際やってみました
- あるテーマについて何枚のスライドで構成するかをリクエストします。(今回は「ラスベガス」というテーマで8枚のスライド構成をリクエストしました)

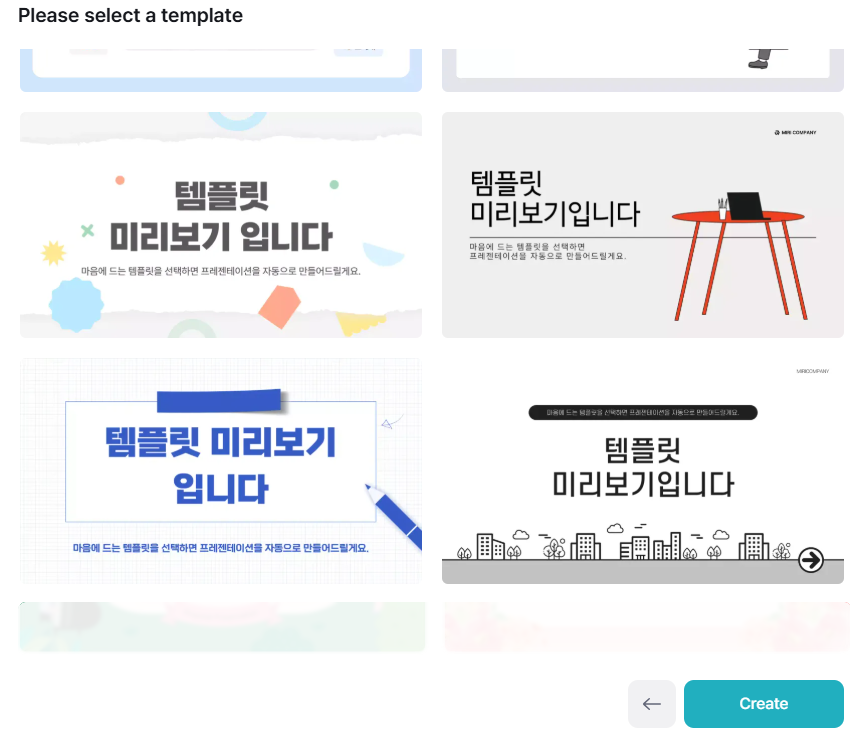
- プレゼンテーションテンプレートのプレビューから、どのテンプレートで生成するかを選択します。
- 生成AIが資料を作成するのを待ちます。
結果

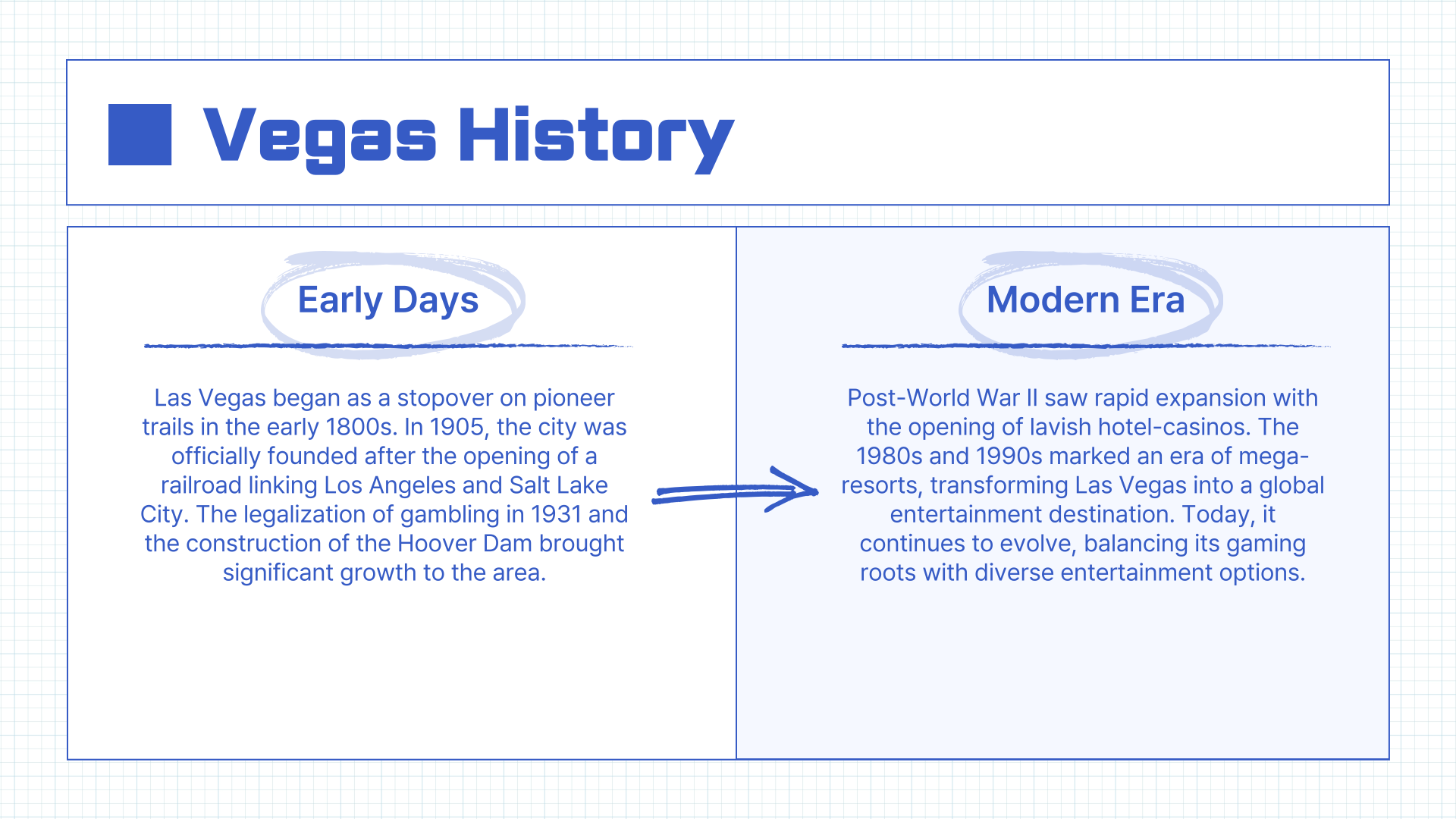
実際に使用してみた結果、選択したテンプレートを基に、リクエストしたテーマについて資料を調査し構成してくれるプロセスが非常に便利に感じられました。
生成AIが提供した下書きを元に、わずかな修正を加えるだけで完成度の高い資料を素早く作成できるため、資料作成にかかる時間を大幅に短縮できる点が魅力的なサービスですね!
Service 2: デザインテンプレート推薦チャットボット
5000万点以上のデザイン要素を活用したテンプレート推薦システム
膨大なデザイン要素の保有量は強みですが、ユーザーにとって適切なテンプレートを探すのに時間がかかるという問題がありました。
これを解決するために、チャットボットとベクトル検索を組み合わせ、ユーザーの意図に合ったデザインテンプレートを推薦する機能を開発したそうです。
実装詳細
1. 画像テンプレートの特性抽出
テンプレートのサムネイル画像から色や雰囲気などの視覚的特性をテキストで表現するため、Amazon Bedrockにプロンプトを送信します。
GPT-4 Visionモデルに比べてコストが半分以下でありながら、文学的な表現力と文章記述力に優れたClaude 3 Sonnetモデルを採用し、性能とコスト効率を確保しています。
2. 埋め込みプロセス
LLMが返した応答テキストからJSON形式のデータを抽出し、各Valueを自然言語の文として変換します。
変換されたテキストは埋め込みモデルを通じてベクトル形式に変換され、Pineconeベクトルデータベースに保存されます。
3. チャットボットとの対話によるユーザーコンテキストの把握
Amazon Bedrockモデルがユーザーと対話し、要件や意図を把握した上でベクトルデータベースにクエリを実行します。
ユーザーの入力と最も関連性が高いテンプレートを見つけるためのコンテキストベース検索を行います。
4. 最適なテンプレートの結果を返す
ベクトルデータベースがベクトル類似度を計算し、メタデータを基にフィルタリングして最適なテンプレートを推薦します。
推薦されたテンプレートはAmazon S3から対応する画像を検索し、サムネイルとしてチャットボット経由でユーザーに提供されます。
感想
非構造化データの活用価値がますます高まる中、ベクトルデータを活用した企業の多様なサービスを紹介した今回のセッションは非常に印象的でした。
私は生成AIを使う中でハルシネーション現象を経験したことがあり、その解消のためにプロンプトエンジニアリングの段階でMarkdown形式で質問を作成する方法を試してきました。
さらに、非構造化データを扱う際にDocument Parseを活用してデータをMarkdown形式に整理し、生成AIに質問することで性能を向上させた事例は非常に印象的でした。
こうした取り組みは、非構造化データの活用可能性をさらに広げる重要な技術的アプローチだと感じました。
また、資料作成に多くの時間を費やす立場として、生成AIを活用してプレゼンテーションの草案を作成できるサービスは非常に魅力的でした。
今後、このサービスを積極的に活用し、資料作成の時間を節約しながら効率性を向上させたいと考えています。

- 2024 Japan AWS Jr. Champions
- 2025 Japan AWS Top Engineers
- 2025 Japan All AWS Certifications Engineers
2023年度新卒入社。出身は韓国です。
好きな AWS サービス:AWS Control Tower
好きなこと:ピアノ、自転車


Recommends
こちらもおすすめ
-

Amazon Bedrock 経由で Codex CLI を利用するまで
2026.6.11
-

AWS re:Invent 2023に行ってきました!
2023.12.9
-

AWS re:Invent を最小の持ち物で攻略する方法
2024.12.19


Special Topics
注目記事はこちら

データ分析入門
これから始めるBigQuery基礎知識
2024.02.28

AWSの料金が 10 %割引になる!
『AWSの請求代行リセールサービス』
2024.07.16