最小二乗法とは?平均との関係を解説

こんにちは。データサイエンスチーム tmtkです。
この記事では、最小二乗法と平均の関係について説明します。最小二乗法は標準的には回帰分析で用いられますが、実は平均も最小二乗法で捉えることができます。
また、最小二乗法と平均の間と同じ関係が、“最小一乗法”と中央値の間にもあることを説明します。
最小二乗法と回帰
最小二乗法とは、回帰分析のパラメータとして、残差の二乗和を最小にするパラメータを選択する手法です。
線形回帰を例にとって具体的に説明します。線形回帰とは、
1. データ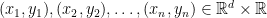
2. 変数
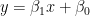
3. 
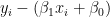

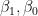
4. 3. で得られた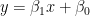
という手続きです。
このような、回帰の手続きのうち、残差の二乗和を最小化する手順のことを、最小二乗法といいます。
AWSのビッグデータ活用・機械学習導入支援サービス
最小二乗法と算術平均
データ
いま、距離の二乗和関数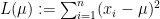


したがって、二次関数の一般論から、
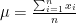

したがって、算術平均は“最小二乗法”で計算できると考えることができます。これで、最小二乗法と算術平均の意外な関係が明らかになりました。

【事例集】AIや機械学習によるビッグデータ活用をしたい方にオススメ!

「AIによるキャスト評価システムの構築」「データ分析基盤の運用費用9割削減」など、AWSを利用したAI、機械学習の成功事例をご紹介します。
“最小一乗法”と中央値
実は、最小二乗法と算術平均の間の関係が、“最小一乗法”と中央値の間にもあてはまることがわかります。以下で、これを説明します。なお、残差のL1ノルムの和の最小化をする方法はよく最小絶対値法などと呼ばれていますが、ここでは最小二乗法との対比を強調して“最小一乗法”と呼ぶことにします。
まず、中央値の定義を復習します。
定義. 中央値
- データの数が奇数個の場合。
データが与えられているとする。いま、データは昇順にならんでいるとする。すなわち、
が成り立っているとする。
このとき、このデータの中央値を
で定義する。 - データの数が偶数個の場合。
データが与えられているとする。いま、データは昇順にならんでいるとする。すなわち、
このとき、このデータの中央値
で定義する。
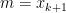

さて、前の議論を、“最小一乗法”に変えて実行してみましょう。すると、次の定理が成り立ちます。
定理.

関数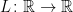
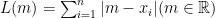
このとき、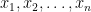
証明の方針.
正確な証明を与える前に、証明の方針を述べます。
簡単な例として、
このとき、中央値は3です。

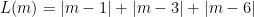
定理の主張は、この距離の和が
いま、はじめ
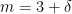

このとき、
から
から
に変化し、
だけ増える。
から
から
に変化し、
から
から
に変化し、

ということで、
これらを合計した
ということがわかります。
これを一般化すると、おおざっぱに言って、
数直線上で
ということがいえます。したがって、数直線上で
この描像に沿って、証明をします。
証明.
データの数が偶数の場合も同様なので、奇数の場合にだけ証明する。

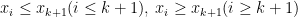
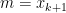
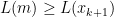

のとき。
に対して、
が成り立つ。
また、に対して、三角不等式より
が成り立つ。したがって、
が成り立つ。
以上より、となって、
のとき。
- の場合と同様。
以上より、定理が成立することがわかる。
まとめ
差の二乗和を最小化するのが算術平均であり、差の絶対値の和を最小化するのが中央値です。
参考
倉田博史・星野崇宏『入門統計解析』新世社,2009年
インフラ担当者の業務負荷を軽減!AWS運用の自動化機能とは?

AWSにはシステム運用を自動化できるサービスが多数取り揃えられており、本資料では、これら機能の概要をわかりやすく解説します。

データ分析と機械学習とソフトウェア開発をしています。 アルゴリズムとデータ構造が好きです。


Recommends
こちらもおすすめ
-

Office 365入門【1】Office 365のID管理とは?
2017.10.2
-

機械学習を学ぶための準備 その4(行列の掛け算について)
2015.12.13
-

Zabbix6.0のネイティブHA機能を試してみた
2022.3.1



Special Topics
注目記事はこちら

データ分析入門
これから始めるBigQuery基礎知識
2024.02.28

AWSの料金が 10 %割引になる!
『AWSの請求代行リセールサービス』
2024.07.16