AWS GlueとAmazon Machine Learningでの予測モデル

こんにちは。データサイエンスチームのhongsです。
この記事は、DataScience Advent Calendarの17日目の記事です。
この記事では、AWS GlueとAmazon Machine Learningを活用した
予測モデル作成について紹介したいと思います。
以前の記事(AWS S3 + Athena + QuickSightで始めるデータ分析入門)で
基本給とボーナスの関係を散布図で見てみました。
(基本給は年間の基本年収、ボーナスは年間ボーナスを意味します。)
その結果、基本給とボーナスは比例していて強い関係性を持っているように見えました。
つまり、基本給が分かれば何となくボーナスがいくら出るか予測が出来そうです。
この何となくの部分をAWSのMachine Learningを使って予測モデル化してみたいと思います。
相関係数と異常値の確認
予測モデルを作成する前に本当に基本給とボーナスは強い関係があるかRを利用して
相関係数で確認してみましょう。
社員レベルや残業時間もボーナスと関係がありそう?なので、こちらも一緒に見てみましょう。
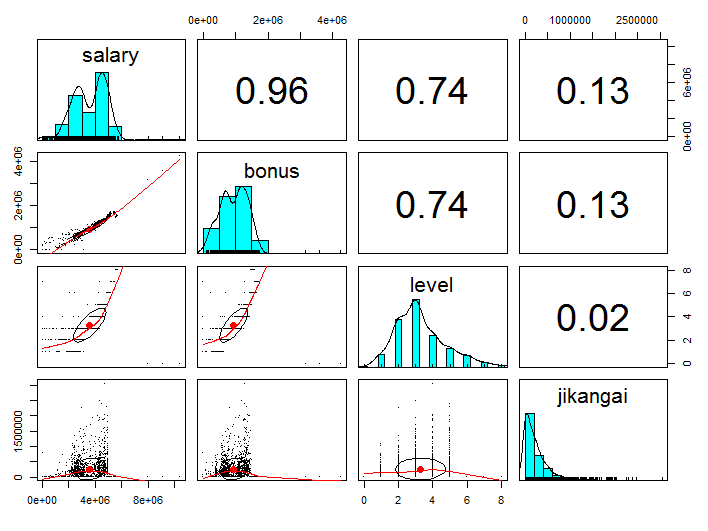
library(psych) library(dplyr) emp_salary <- read.csv(file="E:\\hongs\\tech_blog\\emp_salary.csv") emp_salary %>% select(salary, bonus, level, jikangai) %>% pairs.panels(pch = ".")
下記の結果を見ると、ボーナスは基本給と0.96、社員レベルと0.74、残業時間と0.13の相関があるようです。
相関係数が0.7以上の場合、強い相関があると言われてるので、やはりボーナスと基本給は密接な関係があることが分かりました。
相関の強さについてはこちらをご参照ください。
因みに、残業頑張ったらボーナスが多く出るという考え方はやはり古いようですね。
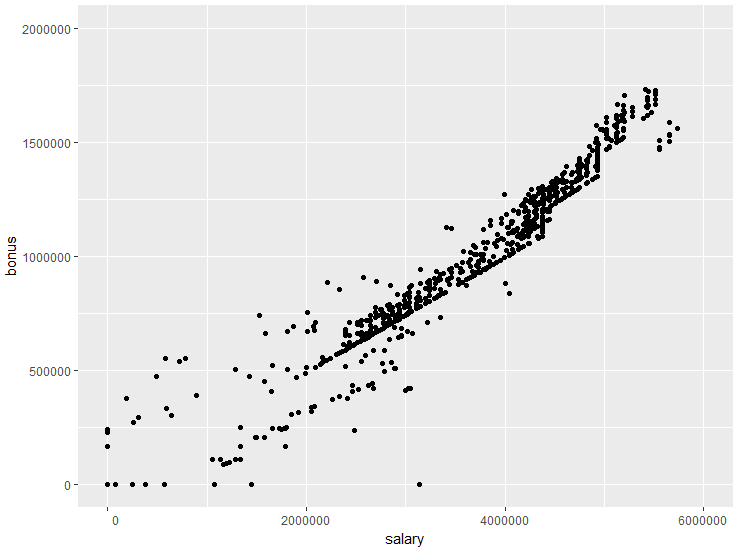
つづいて、データに異常値はないか確認してみましょう。
library(ggplot2)
ggplot(data = emp_salary) +
geom_point(aes(x = salary, y = bonus)) +
coord_cartesian(xlim = c(0, 6000000), ylim = c(0, 2000000)) +
scale_y_continuous(labels=function(n){format(n, scientific = FALSE)}) +
scale_x_continuous(labels=function(n){format(n, scientific = FALSE)})
基本給やボーナスが0のデータが気になります。ボーナスが0のケースはあるとしても
基本給が0のケースは考えにくいので異常値として基本給0のデータは除外します。
AWS GlueでETLジョブ作成
AWS GlueはETL(抽出、変換、ロード)がUI上で簡単に行えるサービスで
ここでは元データから学習に必要なカラムの抽出および異常値を除外する作業を行います。
具体的には複数のカラムから基本給とボーナスカラムだけ抽出します。
そして基本給が0のデータを除外するETLジョブを作成します。
因みに、まだ東京Regionでは利用出来ないため、バージニア北部Regionを利用します。
(12/22よりAWS Glueが東京Regionで利用可能になりました。)
AWS Glueの詳細についてはAWS Glueの公式ページをご参照ください。
まず、元のデータから必要なカラムだけ抽出するMappingを作成します。
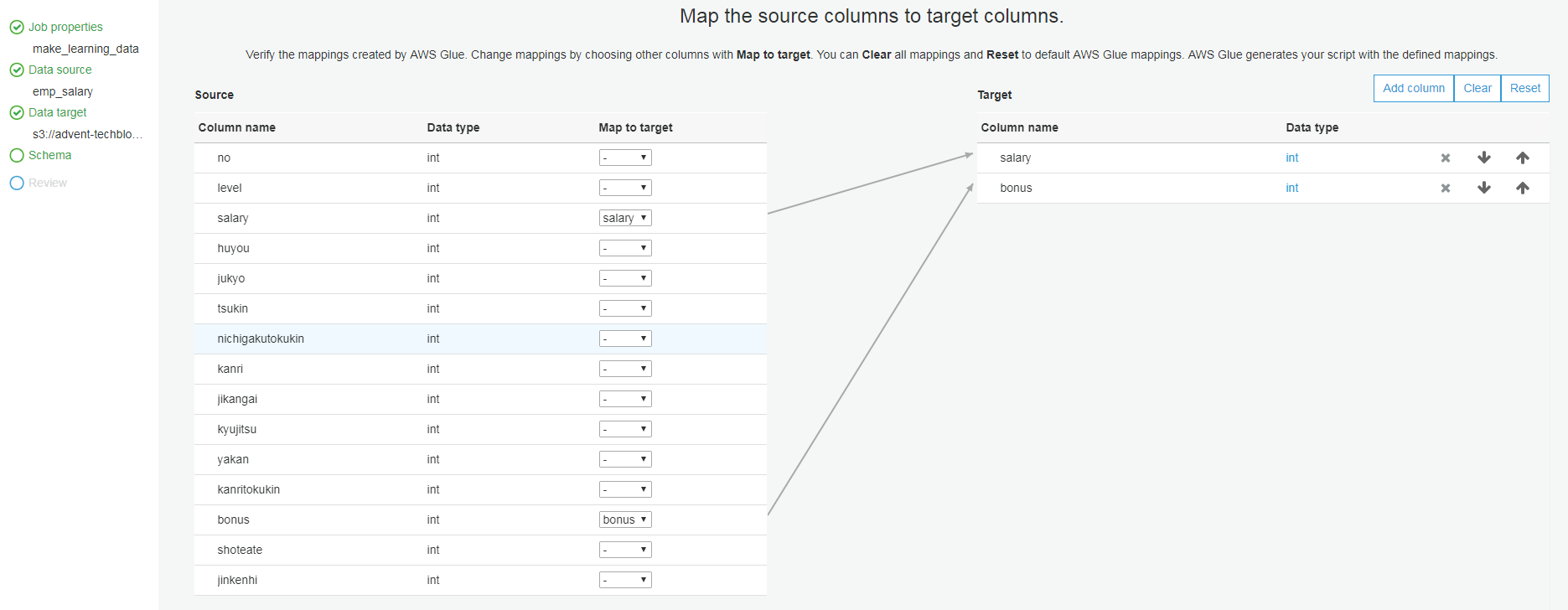
Mappingを作成した後、手順に沿って進めて行くとGlueは最終的に下記のような
ETL用のPythonコードを自動生成します。
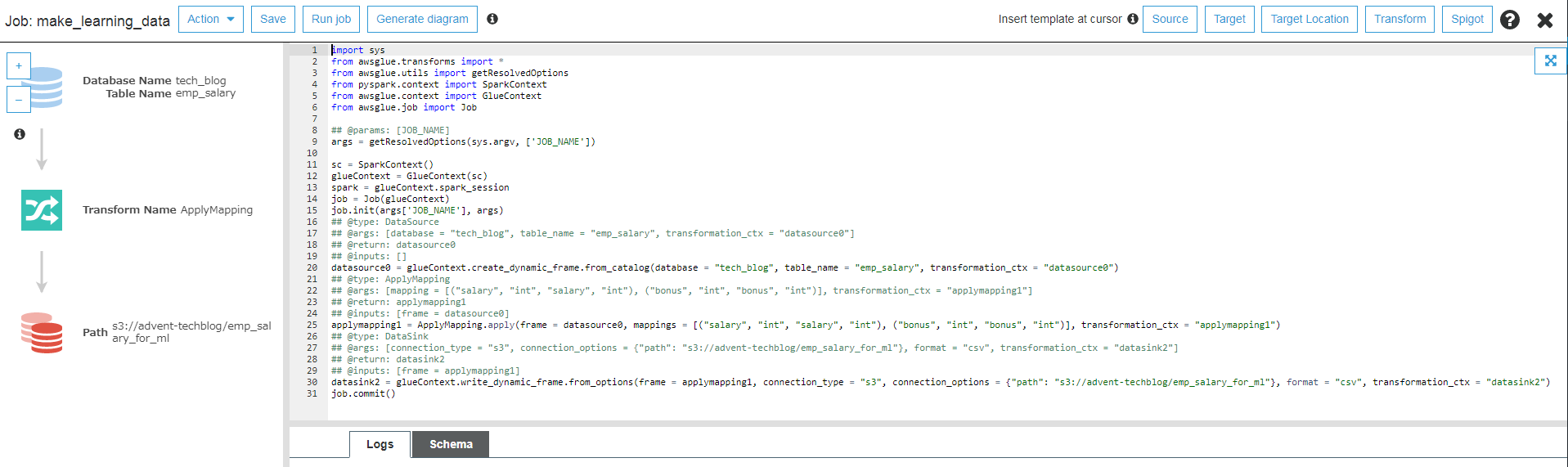
異常値を除外するため、自動生成されたPythonコードにFilter機能を追加します。
追加したFilter機能を含んだ、全体のPythonコードは下記のようになります。
このコードを保存してETLジョブを実行すれば学習に使うデータが作成されます。
import sys
from awsglue.transforms import *
from awsglue.utils import getResolvedOptions
from pyspark.context import SparkContext
from awsglue.context import GlueContext
from awsglue.job import Job
## 今回追加した部分(基本給が0より大きいデータのみ扱うため)
## @type: Filter
## @args: [f = filter_function, transformation_ctx = "<transformation_ctx>"]
## @return: <output>
## @inputs: [frame = <frame>]
def filter_function(dynamicRecord):
if dynamicRecord.salary > 0:
return True
else:
return False
## @params: [JOB_NAME]
args = getResolvedOptions(sys.argv, ['JOB_NAME'])
sc = SparkContext()
glueContext = GlueContext(sc)
spark = glueContext.spark_session
job = Job(glueContext)
job.init(args['JOB_NAME'], args)
## @type: DataSource
## @args: [database = "tech_blog", table_name = "emp_salary", transformation_ctx = "datasource0"]
## @return: datasource0
## @inputs: []
datasource0 = glueContext.create_dynamic_frame.from_catalog(database = "tech_blog", table_name = "emp_salary", transformation_ctx = "datasource0")
## 今回追加した部分(基本給が0のデータを除外)
## @type: DataSource
## @args: [frame = datasource0, f = filter_function, transformation_ctx = "filteringdata"]
## @return: filteringdata
## @inputs: []
filteringdata = Filter.apply(frame = datasource0, f = filter_function, transformation_ctx = "filteringdata")
## @type: ApplyMapping
## @args: [mapping = [("salary", "int", "salary", "int"), ("bonus", "int", "bonus", "int")], transformation_ctx = "applymapping1"]
## @return: applymapping1
## @inputs: [frame = filteringdata]
applymapping1 = ApplyMapping.apply(frame = filteringdata, mappings = [("salary", "int", "salary", "int"), ("bonus", "int", "bonus", "int")], transformation_ctx = "applymapping1")
## @type: DataSink
## @args: [connection_type = "s3", connection_options = {"path": "s3://advent-techblog/emp_salary_for_ml"}, format = "csv", transformation_ctx = "datasink2"]
## @return: datasink2
## @inputs: [frame = applymapping1]
datasink2 = glueContext.write_dynamic_frame.from_options(frame = applymapping1, connection_type = "s3", connection_options = {"path": "s3://advent-techblog/emp_salary_for_ml"}, format = "csv", transformation_ctx = "datasink2")
job.commit()
Amazon Machine Learningで予測モデル作成
AWS Machine Learningはその名の通り、AWS上で機械学習ができるサービスで、
Python、R、Scalaなどでコードを書く必要がなくUI上の設定で手軽に出来ます。
詳細についてはこちらのページをご参照ください。
まず、データソースを作成します。
学習データはS3とRedshiftから選ぶことが出来ます。今回はS3のデータを使うため、
S3 locationに学習データの場所を指定します。
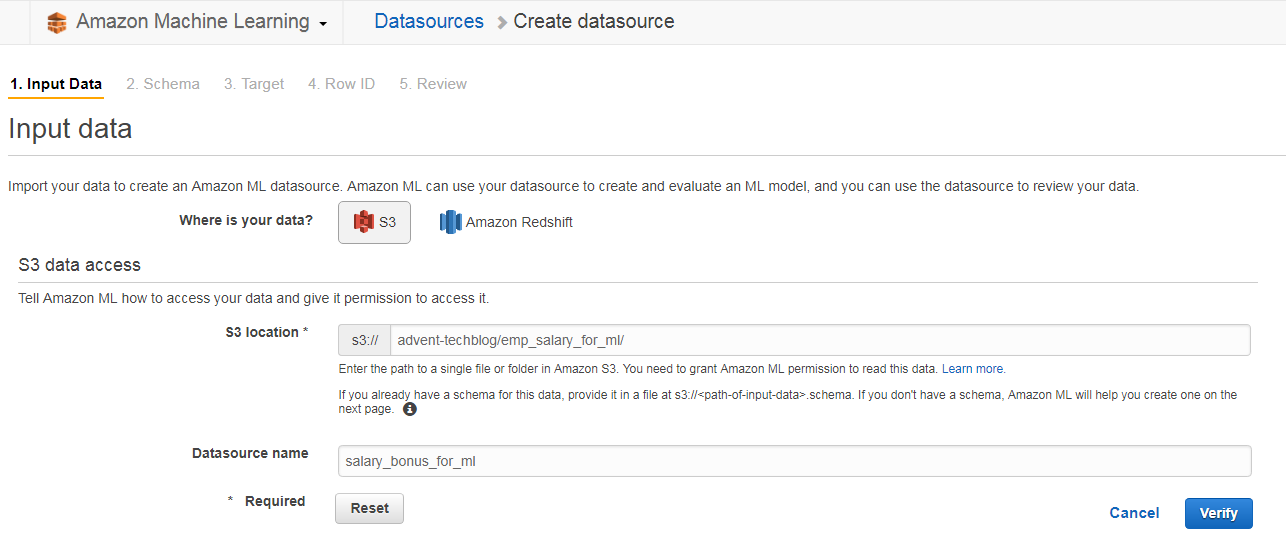
次に、Schema確認とCSVファイルのheaderの扱いについて設定します。
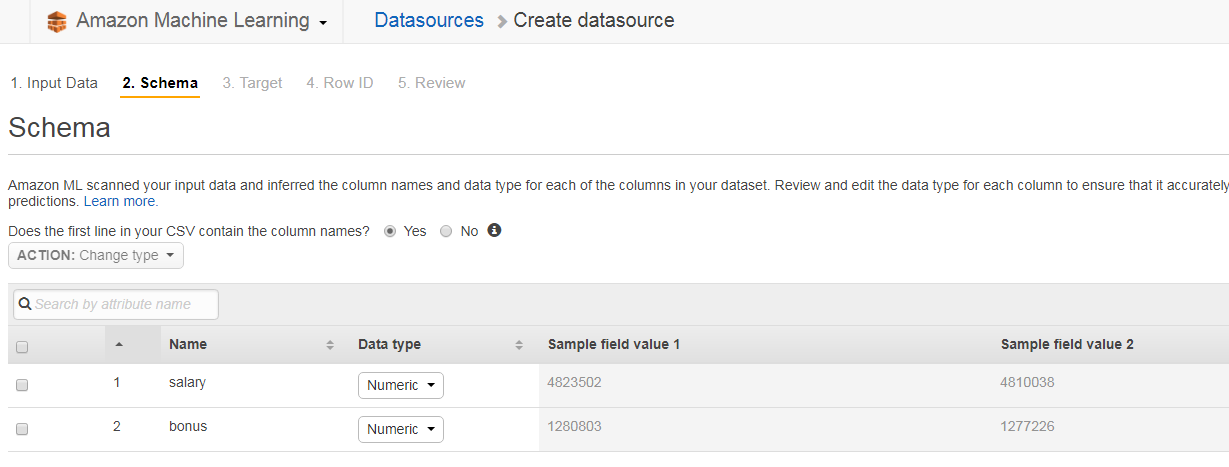
つづいて、予測したい項目(bonus)を選択して、手順に沿って進めて行くとデータソース作成が完了します。

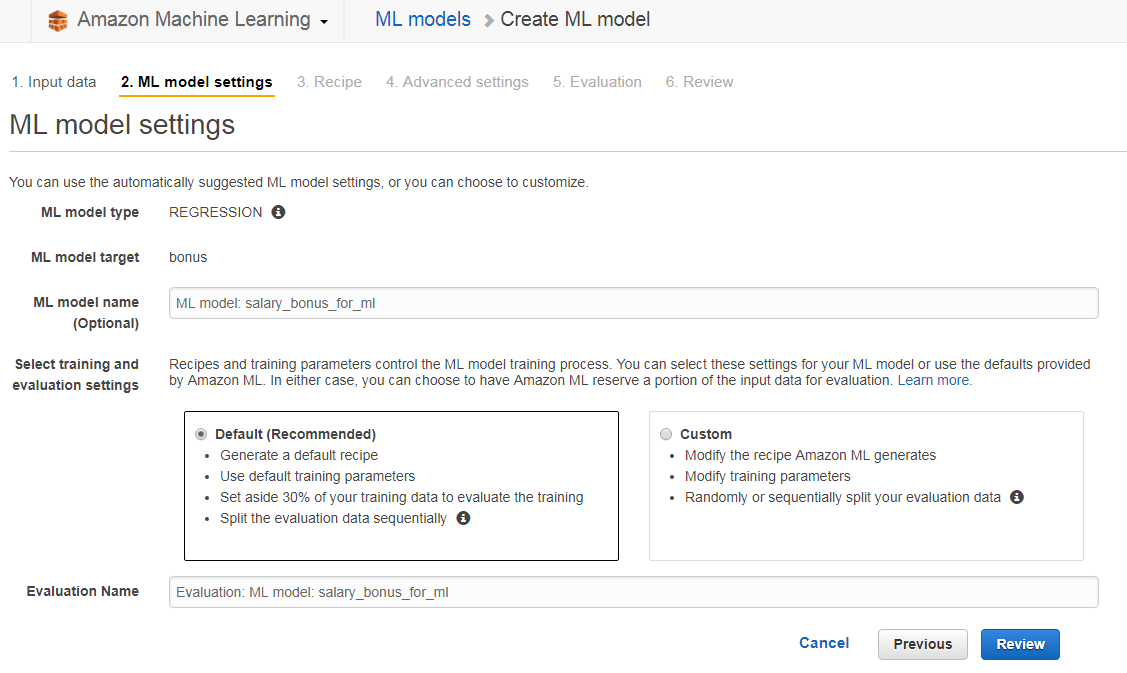
データソース作成が完了したら下記のようにML model settings画面が表示されます。
ここでは自動的に設定されているDefault設定でModelを作成します。
モデルの作成が完了したらEvaluation Summary画面で評価結果の確認が出来ます。
評価にはRMSEを使っていて、基準値より高い評価結果になっていることが分かります。
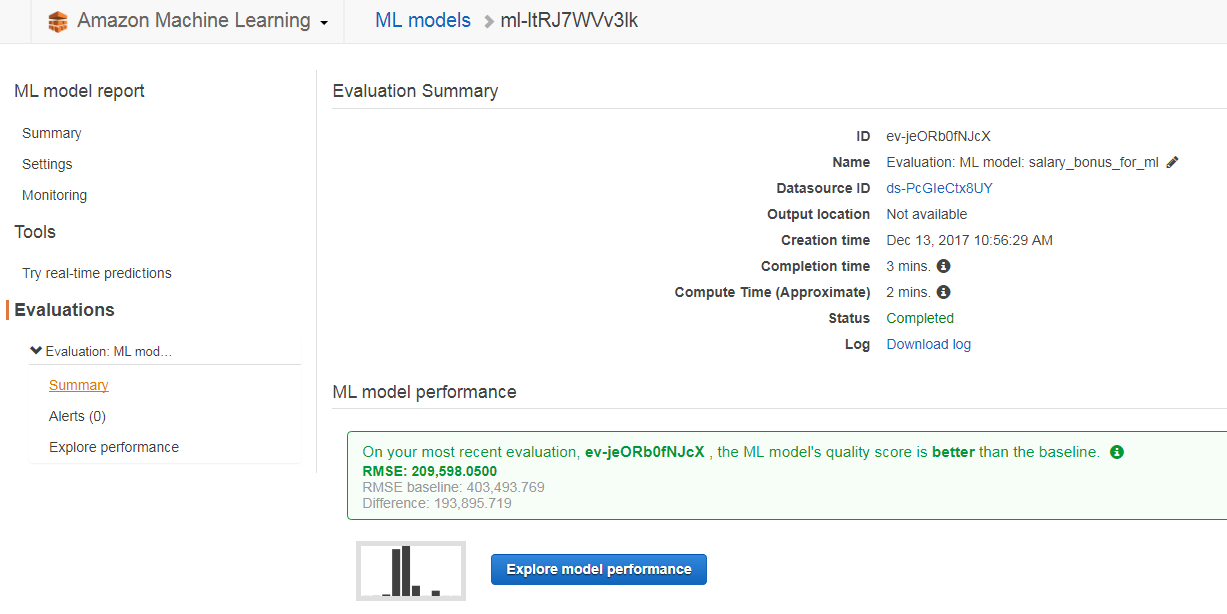
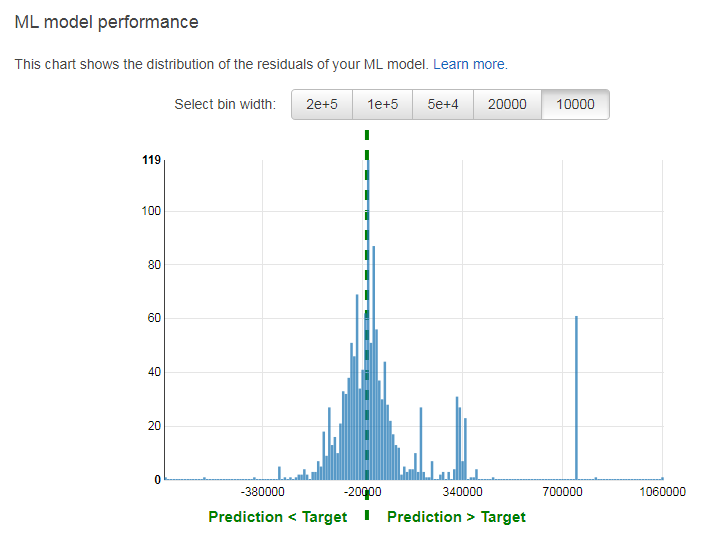
そして、Explore model performanceボタンをクリックするとモデルの残差の分布グラフが表示されます。
概ね正規分布の形をしていますが、残差70万超えのデータが60件以上あることから
モデルの改善の余地があることが分かります。(この記事ではモデル改善については省略します)
予測モデル実行
ここでは、モデルの実行方法について見て行きます。
モデル実行にはBatchとReal-timeの2つの方法があります。
Batchの実行はPredictions画面にあるGenerate batch predictionsボタンをクリックします。
予測で使うinput dataを選択します。
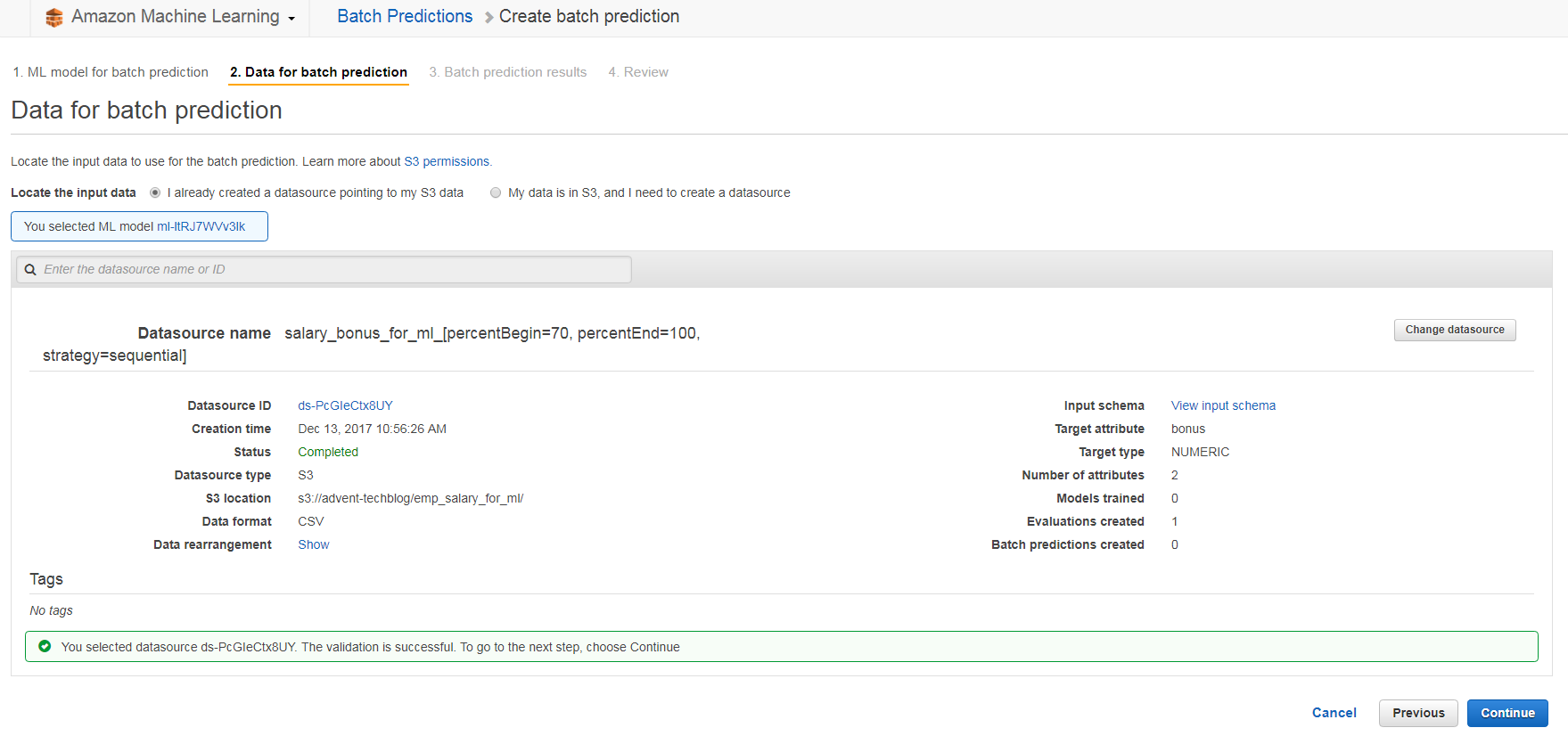
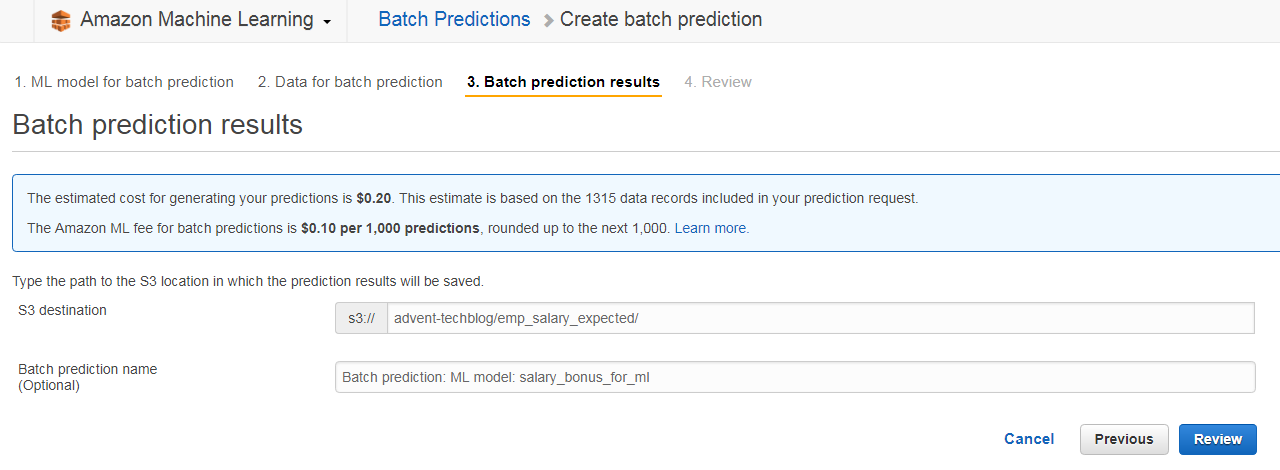
Batchの結果(予測結果データ)の保存場所を設定します。
このまま手順に沿って進めばBatch実行完了となります。
次に、Real-time実行方法ですが、Real-time実行にはTry real-time predictionsを使った
Browser上で実行する方法とEndpointを作成し外部からAPIを通じて実行する方法の2つがあります。
まず、Browser上で実行するためにはPredictions画面のTry real-time predictionsボタンをクリックします。
Try real-time predictions画面が表示されます。
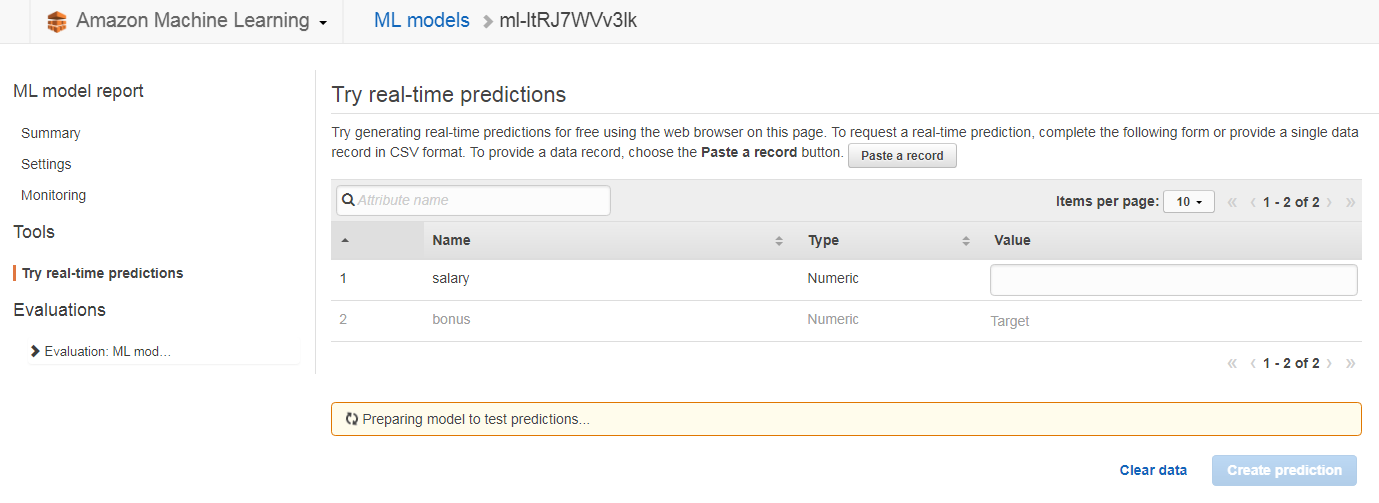
salaryのvalueに値を入力してCreate predictionボタンをクリックします。
そうすると画面の右のところに予測結果が表示されます。
基本給400万の場合、ボーナスが約111万になるという結果が返ってきました。
実際のデータと比べてもそれらしい結果に見えます。
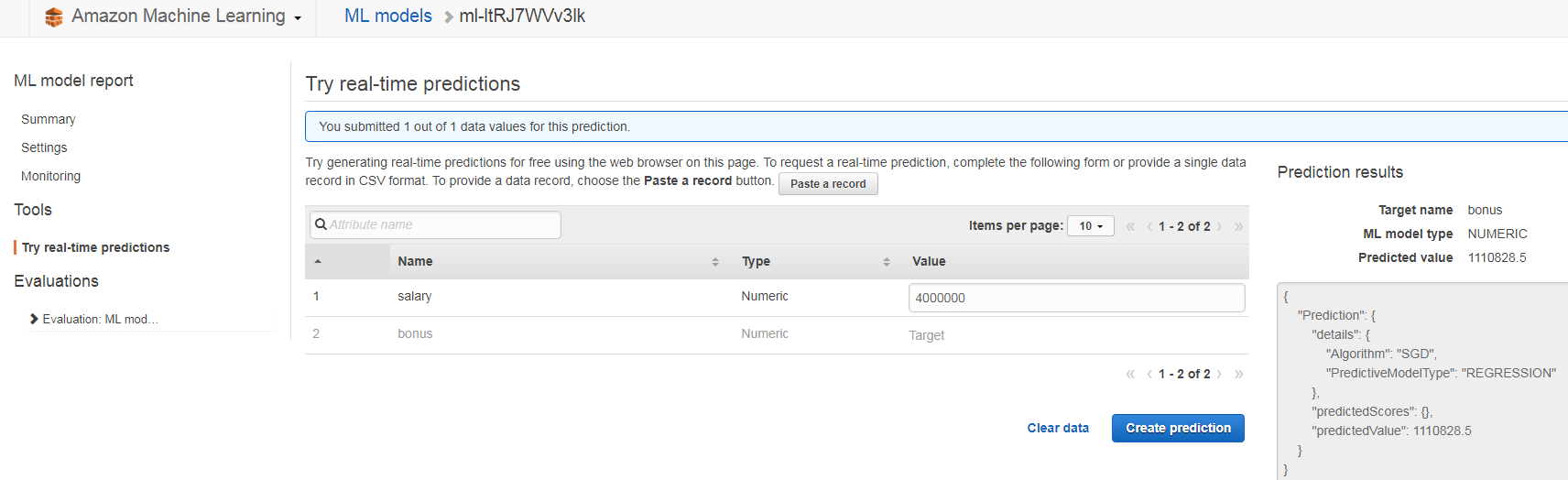
つづいて、APIを通じて実行する方法です。
まずはCreate endpointボタンをクリックしてReal-time Endpointを作成します。
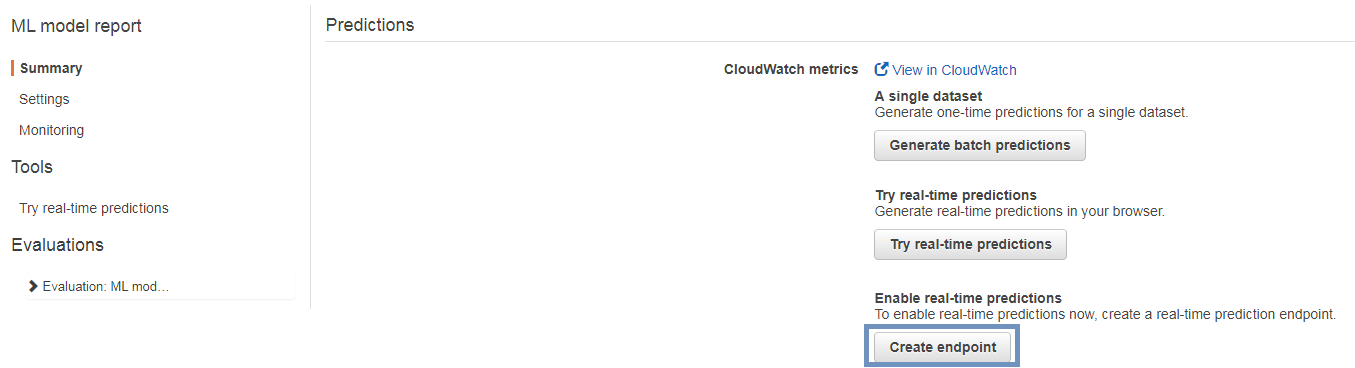
料金の説明と共に、Real-time Endpoint作成の確認画面が表示されます。
ここでCreateボタンをクリックするとEndpoint作成が完了します。
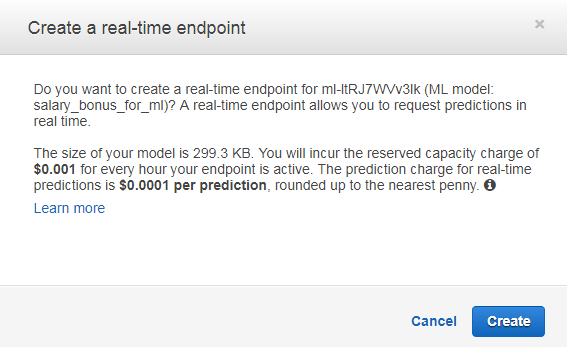
Endpoint作成が完了したらEndpointのURL情報が表示されます。
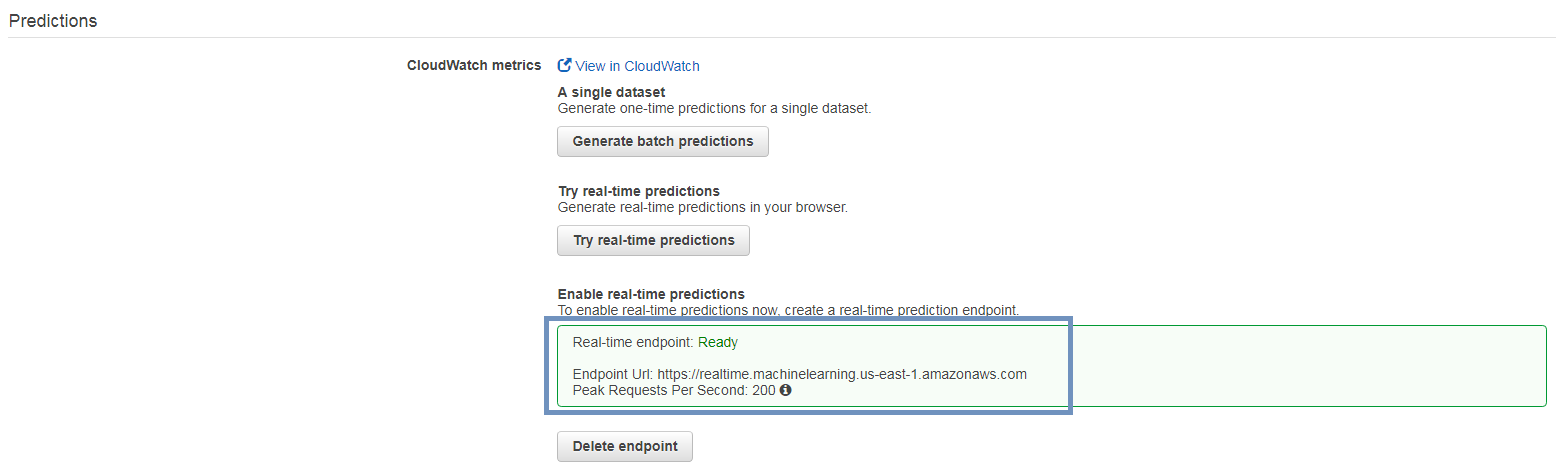
では、AWS CLIでReal-time予測を実行してみましょう。
まず今回のAmazon Machine Learningサービスはバージニア北部Regionを利用しているため
Region情報を更新します。(普段は東京Regionを使っているため)
[ec2-user]$ aws configure AWS Access Key ID [********************]: ******************** AWS Secret Access Key [********************]: ******************** Default region name [ap-northeast-1]: us-east-1 Default output format [json]:
Model-idとEnpoint urlを設定し、基本給が400万の場合のボーナスをReal-timeで予測してみましょう。
上記で行ったTry real-time predictionsの結果と同じく予測ボーナスは約111万であることが確認出来ました。
[ec2-user]$ aws machinelearning predict --ml-model-id ml-********** \
--record salary=4000000 \
--predict-endpoint https://realtime.machinelearning.us-east-1.amazonaws.com
{
"Prediction": {
"predictedValue": 1110828.5,
"details": {
"PredictiveModelType": "REGRESSION",
"Algorithm": "SGD"
}
}
}
まとめ
AWS上でETLと機械学習を行う上でこれから必須であろう、
AWS GlueとAWS Machine Learningを組み合わせて予測モデルを作成してみました。
予測モデルの評価結果も高く、実際のテストでもそれらしい結果が得られました。
今回はAWSのDefault設定で予測モデルを作成したのですが、
学習を繰り返しながらParameterを調整すればもっと優れたモデル作成が期待できそうです。
では、皆さんの年末ボーナスが多いことを祈りつつ、
これからAWSでETL処理やMachine Learningを始める方に少しでも参考になれたら幸いです。
テックブログ新着情報のほか、AWSやGoogle Cloudに関するお役立ち情報を配信中!
Follow @twitterRecommends
こちらもおすすめ
-

混合ユニグラムモデルについて(トピックモデリング入門)
2017.12.18
-

機械学習を学ぶための準備 その5(行列のいろいろ)
2015.12.19



Special Topics
注目記事はこちら

データ分析入門
これから始めるBigQuery基礎知識
2024.02.28

AWSの料金が 10 %割引になる!
『AWSの請求代行リセールサービス』
2024.07.16