画像の特徴を用いたランク学習の論文紹介

こんにちは。データサイエンスチームの t2sy です。
ランク学習 (Learning to Rank; LTR) はランキング問題を教師あり機械学習を用いて解く手法 [1] です。情報検索や自然言語処理をはじめ多くの分野に応用されています。この記事では、画像の特徴を用いたランク学習の論文を2つ紹介し、また VGG-16 を用いた ViTOR (Visual learning TO Rank) モデルの再現実験の結果を紹介します。
- Learning Visual Features from Snapshots for Web Search [Fan et al., 2017] arXiv:1710.06997
- ViTOR: Learning to Rank Webpages Based on Visual Features [B.van den Akker et al., 2019] arXiv:1903.02939
本記事で掲載されている画像は上記論文からの引用を含みます。また、arXiv に投稿されている論文は内容が変更・修正となる場合があり、本記事の執筆時点 (2019-06-20) とは内容が異なる可能性があります。
Learning Visual Features from Snapshots for Web Search
Web 検索にランク学習を適用する際に、テキストやリンク構造、ユーザログなどから計算された多くの特徴量が用いられます。Web ページは HTML のテキスト以外にも HTML に関連付けられた CSS により構造化されたレイアウト (i.e Webページのスナップショット) を含んでいます。構造化されたレイアウトはクエリに対する Web ページの適合性を示す有用な特徴量を有していると考えられます。しかし、これまで Web 検索ではこの情報は直接的にはあまり使われてきませんでした。本論文は、Webページのスナップショットから visual features を抽出しランク学習を行う E2E の ViP (Visual Perception) モデルを提案しています。
ViP モデル
Web ページのスナップショットは画像であるためシンプルに CNN (Convolutional Neural Network) を使うことが考えられます。しかし、Web ページを見るユーザの viewing pattern は一般的な自然画像の場合とは異なります。例えば、Web ページの場合、上から下に向かって横読み (row by row reading) するパターンがあることは受け入れることのできる主張だと思います。本論文で提案された ViP モデルではこのような Web ページの viewing pattern を捉えるためにアーキテクチャの工夫を行なっています。
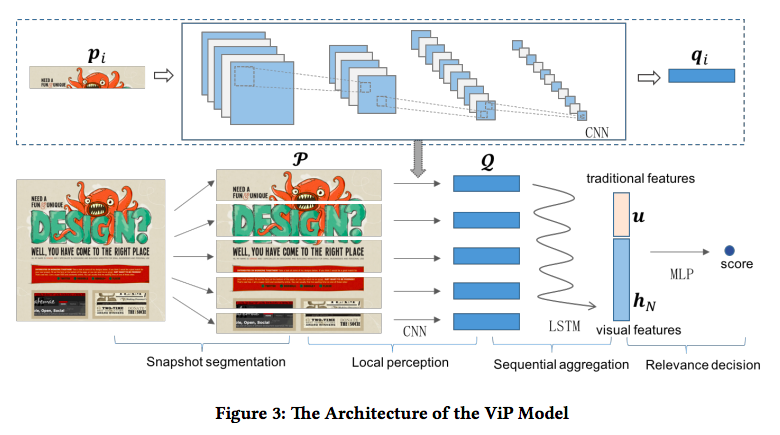
ViP (Visual Perception) モデルのアーキテクチャは以下の4つのレイヤに分かれます。
- snapshot segmentation: 入力画像
を N 個の領域に分割し
を出力する。
- local perception:
を CNN に入力し画像の領域ごとの特徴量
を出力する。 (
)
- sequential aggregation:
を上から順に LSTM に入力し最後の出力を visual features
とする。
- relevance decision:
を連結し relevance feature
とする。
を出力する。
ViP モデルの実験
MQ2007、MQ2008 [2] の2つのデータセットを用いた ViP モデルの実験結果は以下です。ViP baseline は特徴量に visual features
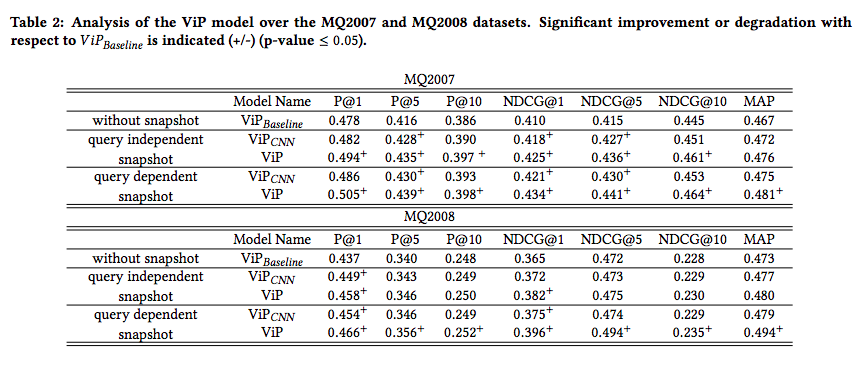
ViP baseline に対して visual features を加えた ViP モデルの性能が向上していることから、Web ページのスナップショットから visual features を学習することはランク学習において重要であることがわかります。また、論文中では他に RankSVM や RankBoost、 LambdaMart といった他のランク学習の手法に対して比較を行った実験で ViP モデルが有意に性能を改善していることを示しています。
ViTOR: Learning to Rank Webpages Based on Visual Features
本論文は2019年5月にサンフランシスコで開催された The Web Conference 2019 で Best Short Paper に選ばれた論文です。
前述した ViP モデルと同様に Web ページの適合性を示す上でスナップショットに含まれる有用な特徴量を抽出・学習することで性能の向上を目指している点は変わりません。
ViP モデルではスナップショットを複数の領域に分け、各領域ごとの画像を CNN に入力し LSTM で visual features を得るアプローチでしたが、本論文では VGG-16 や ResNet-152 といった画像分類モデルの転移学習で抽象的な画像の特徴量を抽出し、それをランク学習に特有の特徴量へ変換するアプローチを提案しています。
ViTOR モデル
ViTOR モデルでは VGG-16 や ResNet-152 などのよく知られた画像分類モデルの転移学習というアプローチでスナップショットから特徴量を抽出します。
ViTOR モデルのアーキテクチャは以下です。
- Input image: スナップショットや saliency heatmap などの入力画像
- Visual feature extraction:
を画像分類モデルに入力し畳み込み層の出力として得られる特徴ベクトル visual feature
- Visual feature transformation:
をランク学習に特有の特徴量
に変換
- Content features: コンテンツ特徴量
- Scoring componet:
を連結した特徴量
を用いてスコア
を出力
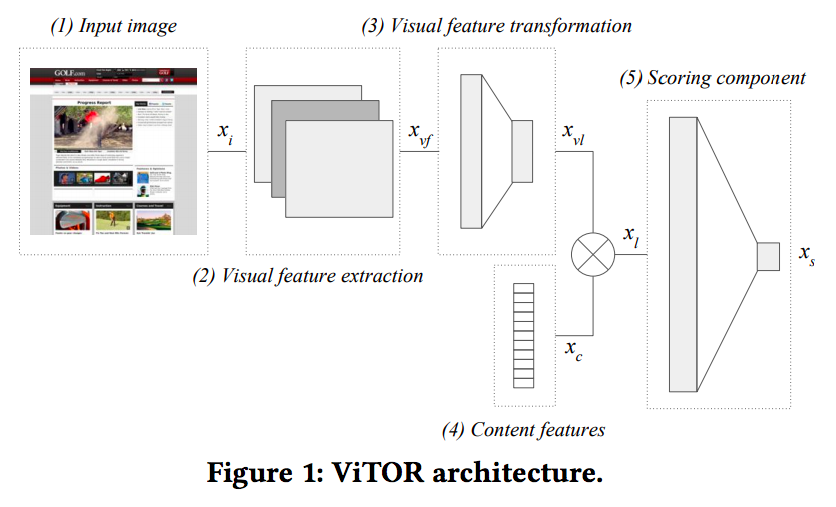
visual feature 抽出器では VGG-16 や ResNet-152 などの訓練済みモデルの畳み込み層のパラメータを凍結 (freezing) します。VGG-16 の場合、全結合層の直前の畳み込み層の出力
Saliency heatmap
本論文では、Web ページの生のスナップショット (vanilla snapshots) やハイライトされたスナップショットの他に saliency heatmap を用いることを提案しています。
以下の図の、左の列は生のスナップショット、中央の列は検索クエリの単語にマッチした部分を赤色 (#ff0000) でハイライトしたスナップショット、右の列は saliency heatmap です。
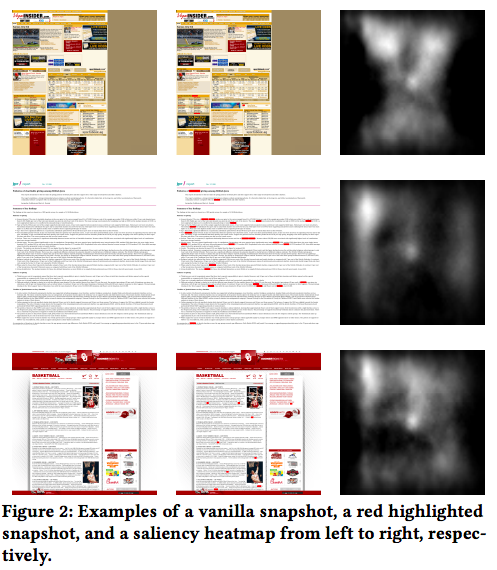
saliency heatmap を用いる利点として、生のスナップショットと比較して Web ページの適合性とより相関することが期待でき、また RGB 画像でなくグレースケール画像でかつ同じ色の部分が広いため、ストレージ容量を最大90%削減できる点が挙げられています。
本論文における saliency heatmap は Two-Stage Transfer Learning of End-to-End Convolutional Neural Networks for Webpage Saliency Prediction [Shan et al, 2017] の手法に基づき、二段階の転移学習により生成されています。Saliency Prediction は人間が画像のどの部分を注視しているかを表す heatmap を予測するタスクです。
Content features
ViTOR モデルで使われる、コンテンツ特徴量 (i.e. Non-visual features) は文書検索などでよく使われる特徴量が用いられています。ただ、ViTOR では LETOR 4.0 dataset [2] で用いられている 46 個の特徴量から最も有用と考えられる以下の 11 個の特徴量に絞りこんでいます。
- Pagerank
- Content length
- Content TF
- Content IDF
- Content TF-IDF
- Content BM25
- Title length
- Title TF
- Title IDF
- Title TF-IDF
- Title BM25
ViTOR dataset でコンテンツ特徴量の数を 46 個と 11 個とした場合の比較実験の結果が以下です。ランク学習の手法は、RankBoost、AdaRank、LambdaMart の三つです。
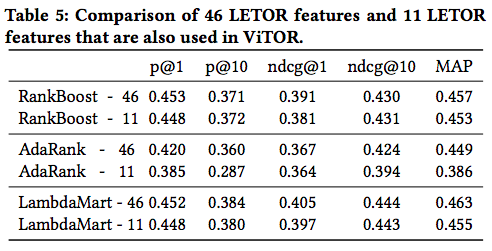
RankBoost と LambdaMart では 46 個と 11 個で各評価指標はほとんど変わらない結果となっています。従って、ViTOR では 11 個の特徴量を採用しています。
ViTOR モデルの実験
ViTOR baseline に対してスナップショットや、ハイライトされたスナップショット、saliency heatmap から抽出された visual features を用いた場合の実験結果は以下です。ViTOR Baseline は visual features を使わずコンテンツ特徴量のみを用いたモデルを指します。
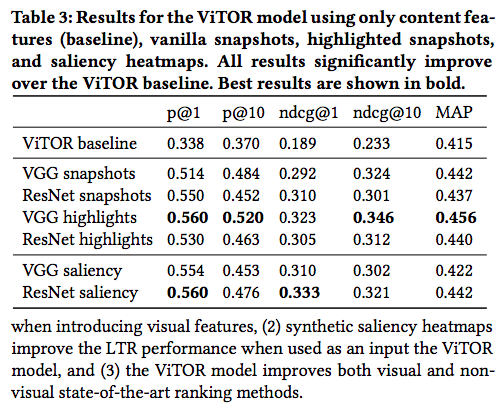
全体として visual features を用いた方が性能が高く、特に VGG-16 でハイライトされたスナップショットを用いたモデルの性能が高いことがわかります。これはスナップショットよりもハイライトされたスナップショットの方が情報量が多いためと推測されます。ResNet saliency は他のモデルと比べ p@1 や ndcg@1 の値が高いことから early precision が重要な場合に向いていると述べられています。
また、コンテンツ特徴量のみを用いた RankBoost や LambdaMart などと比較した実験の結果が以下です。
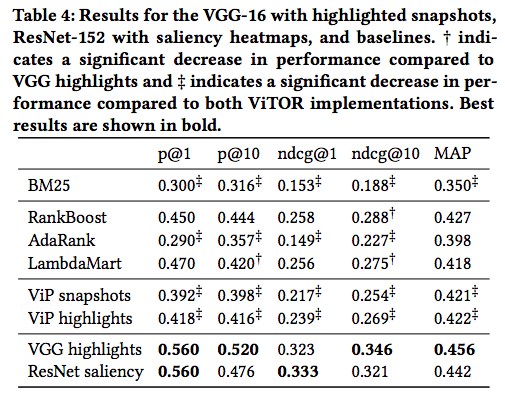
ViTOR の方が良いものの全ての指標で顕著に改善されているわけではありません。この理由として、ViTOR ではランク学習の損失関数にペアワイズのヒンジ損失というシンプルな損失関数としているためでないかと考察しています。
本論文のコードは GitHub で公開されているため、今回 VGG-16 を用いた ViTOR モデルの再現実験を行いました。 test データ (Epoch 20) に対する各モデルの性能の結果は以下です。
| ndcg@1 | ndcg@5 | ndcg@10 | p@1 | p@5 | p@10 | |
|---|---|---|---|---|---|---|
| ViTOR baseline | 0.133 | 0.231 | 0.235 | 0.250 | 0.420 | 0.380 |
| VGG snapshots | 0.267 | 0.300 | 0.324 | 0.400 | 0.530 | 0.530 |
| VGG highlights | 0.289 | 0.289 | 0.351 | 0.526 | 0.453 | 0.442 |
| VGG saliency | 0.325 | 0.282 | 0.290 | 0.550 | 0.460 | 0.475 |
概ね論文と同じような傾向となり転移学習を用いた visual features の抽出によりランク学習の性能を向上できることを確認しました。
本論文は、Web ページのスナップショットから転移学習により visual features を抽出することでランク学習の性能を向上できることを示しました。今後の方向性としてスナップショットや、ハイライトされたスナップショット、saliency heatmap から抽出した visual features を組み合わせたり、Visual feature 抽出器に CNN でなく CapsuleNet [3] を用いるアイデアなどが挙げられています。
また、著者らは visual features を伴うランク学習のために、豊富で多様な Web ページとそれに対応するスナップショットを含む ViTOR dataset をリリースしています。
おわりに
この記事では、Web 検索のランク学習で Web ページのスナップショットを用いることでモデルの性能を向上させることを目的とした研究を2つ紹介しました。Web 検索における Web ページのスナップショットに限らず、ランク学習で従来あまり使われてこなかったデータから目的に合った特徴量の抽出あるいは表現の獲得により性能の向上を目指す研究は今後も増えてくるかもしれません。データサイエンスチームでは最新の研究にアンテナを張りつつ、これらの統計・機械学習の技術を既存事業に展開していくことを目指していきます。
参考文献
[1] A Short Introduction to Learning to Rank
[2] LETOR 4.0
[3] Dynamic Routing Between Capsules [S.Sabour, 2017] arXiv:1710.09829
[4] 推薦システムの基本的な評価指標について整理してみた

2016年11月、データサイエンティストとして中途入社。時系列分析や異常検知、情報推薦に特に興味があります。クロスバイク、映画鑑賞、猫が好き。


Recommends
こちらもおすすめ
-

JDLA「G検定」試験の合格体験記
2018.12.12
-

高速フーリエ変換で畳み込みを高速化する 1. 離散フーリエ変換入門
2018.7.24
-

「AWS AI Week for Developers」へ参加してみました!
2023.10.23
-

NHN FORWARD 2019 参加レポート-AI/機械学習セッションの紹介-
2019.12.4

Special Topics
注目記事はこちら

データ分析入門
これから始めるBigQuery基礎知識
2024.02.28

AWSの料金が 10 %割引になる!
『AWSの請求代行リセールサービス』
2024.07.16