機械学習 曲線フィッテングについて おまけ?編
2016.4.28

前回: 機械学習 曲線フィッテングについて 後編
橘です。
曲線フィッティングはもっとサラッと書くつもりでいたのですが、3回も使ってしまいました。
前回お話した通り、次回からは1テーマ1回で書いていきます。
そして今回、おまけ編として書き始めたのですが、おまけというよりはむしろ中核です。
前回ご説明した、曲線
ですのでお見苦しい点があるかと思いますが、「汚い板書」だと思って、ご自身でまとめ直していただけたら幸いです。
目的をもう一度確認
目的は次のとおりです。

曲線フィッティングの目的は、「いい曲線を描いてデータを予測する」ことにあります。
「いい曲線である」であるとは、「実際のデータを曲線を比較した時になるべくズレがない」曲線を指します。ではどうすれば「ズレがない」曲線を描けるか、の考え方を見ていきましょう。
いい曲線を描くアプローチ
いい曲線を描くには、次のようなアプローチを考えていきます。
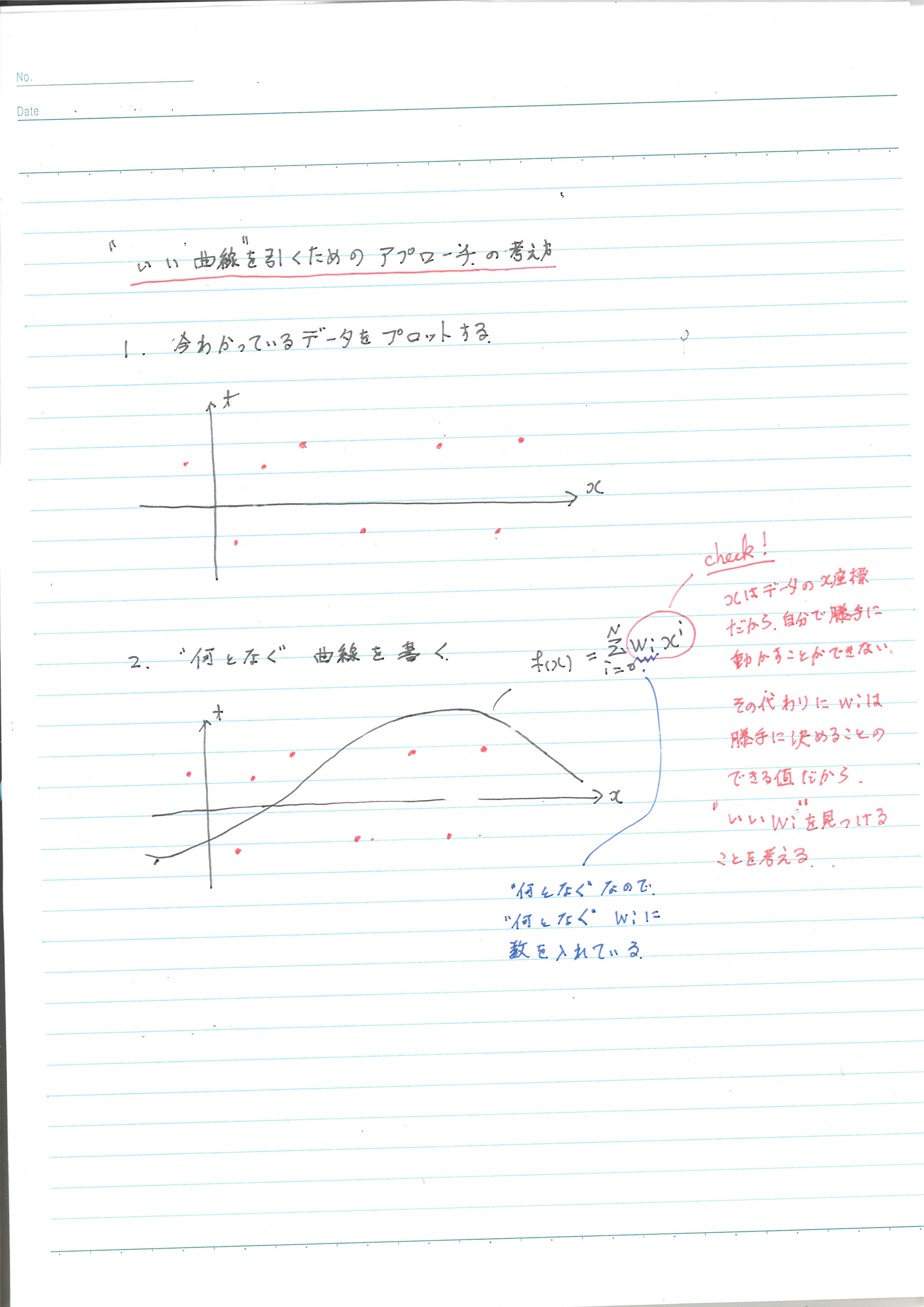

まとめると、
- データをプロットする
- “適当に”曲線を引く
- データと曲線の誤差を謀る
- もっとも誤差が小さい時の、曲線の各係数の
を計算して求める
- 4.で計算した新しい
というものです。全体を見ると、そこまで難しい話でないと感じていただければうれしいです。
ですが、4.の「もっとも誤差が小さい時の、曲線の各係数の
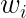 の計算方法
の計算方法
証明は次の通りです。




はい、何をやっているかわからない方も多いかと思います。ですので一言でざっくり言うと、
「各データ毎に誤差関数が小さくなるところを計算して行ったら、いい感じの
という感じです。本質的には、そんなにズレてはいないかと思います。
前回ご説明した通り、各
一度作ってしまえば「なんだ、こんなものか」と思われるかもしれません。
曲線フィッティングの解説に関しては、以上になります。
長々とご覧頂き、ありがとうございました。
最後に、理論とプログラミングについて
私自身がそうだったのですが、大学からずっと数学をやっていたため機械学習の参考書を読んで割りとすぐに理解はできるのですが、「理論をコーディングに落とす」ことができませんでした。何から手をつけたらいいかわからなかったのです。おそらく、参考書を読むところから入った方であれば、多少なりとも共感いただけるかもしれません。
また逆に、最近はかなり強力なライブラリが増え、理論的な背景を知らなくても大抵の機械学習やディープラーニング、もしくはそこまでいかなくても分析ができるようになっているかと思います。「作れるが、理論はあまり知らない」、そういう人ももしかしたら増えているのかもしれません。
と、偉そうに言っていますが、私自身も勉強中です。最近になってやっと、本を読んで、読んだ結果をコーディングしたりできるようになってはきました。そこで、今の私が思う、「理論は知っているが、プログラミングが書けない方」へ、いくつかポイントを共有したいと思います。
最新のライブラリに頼る
先程も言った通り、各言語ごとに強力なライブラリが提供されています。その強力さは「理論的な背景を知らなくても結果は出せるレベル」です。それらを有効に使いましょう。
「技術は理論をオーバーラップするもの」だと思っています。技術でなんとかなるうちは技術を有効活用すべきです。技術でなんとかならなくなったら、理論の役目が来るのだと思います。
困らない限りは、計算速度は気にしない
他の人の持論を引き合いに出すと「明日できることは明日やればいい」の精神だと思います。「計算結果に5億年・・・?ボタンかよ。」などと困らないかぎりは、まずやりやすい方法でさくっと作ってしまうべきです。
Pythonであれば、簡単なことはThe Jupyter Notebookでやってしまうなど、さくっとやれる環境を用意しましょう。
でも最終的にはやっぱり理論大事
他の人の発言を引き合いに出すと「中身がピーマン」(古い)なのは、やはりあまりかっこ良くないですし、モチベーションにつながらないと思います。専門書を読む時間と、コードを書く時間をわけるなど、工夫するのがいいと思います。
ポイントとしては以上です。
次回予告
最尤推定法をご紹介します。
できるだけ、数学は取り入れます。
テックブログ新着情報のほか、AWSやGoogle Cloudに関するお役立ち情報を配信中!
Follow @twitter
AWSを中心としたクラウドインフラやオンプレミス、ビッグデータ、機械学習などの技術ネタを中心にご紹介します。
Recommends
こちらもおすすめ
-

ディープラーニングにおけるdeconvolutionとは何か
2018.11.6
-

第18回情報科学技術フォーラム(FIT2019)に参加しています
2019.9.5
-

Pythonで実装する画像認識アルゴリズム SLIC 入門
2018.2.13
-

「21世紀の相関係数」を超える(2)
2018.4.6


Special Topics
注目記事はこちら

データ分析入門
これから始めるBigQuery基礎知識
2024.02.28

AWSの料金が 8 %割引になる!
『AWSの請求代行リセールサービス』
2023.01.15