「21世紀の相関係数」を超える(2)
2018.4.6

はじめに
昨年,非線形データの相関係数を計算する記事を書きました。
「21世紀の相関係数」を超える
記事では,
- ピアソンの積率相関係数,最大情報量係数(MIC)というものを紹介しました
- ピアソンの積率相関係数は直線関係しか検出できず,最大情報量係数は計算効率を向上させる方法があるので,R-AMICという手法を開発したので紹介しました
- 最大情報量係数以外にも手法があるのですが,紹介は宿題にしました
その時の宿題を片付けようと思います。
ピアソン以外の相関係数やMIC以外の非線形系用相関係数との比較も行いたいと思いますので,次回を御期待下さい
相関係数
データとデータの関連性を表す相関係数については,当ブログで何度か取り上げて来ました。
PythonやR言語で相関係数を計算してみよう
相関係数とは、2つの変数に線形関係があるかどうかを判定するための値です。
AWS GlueとAmazon Machine Learningでの予測モデル
予測モデルを作成する前に本当に基本給とボーナスは強い関係があるかRを利用して相関係数で確認してみましょう。
通常使われる相関係数:2つの変数において,スカラー値が以下のような値を持つ
・片方が増加するともう片方も増加する場合,増加の度合いに応じて絶対値が1以下の正の値を取る
・片方が増加するともう片方は減少する場合,増加の度合いに応じて絶対値が1以下の負の値を取る
・片方が増加してももう片方は変化しない場合,ゼロとなる
以下,ピアソン以外の相関係数やMIC以外の非線形系用相関係数ついて説明したいと思います。
注:本記事では,分かりやすさのため,理論的・数学的な厳密さはこだわらず,イメージが湧きやすいように表現しています。「正確に言うと違う」という部分が多々ありますが,ご容赦下さい。
非線形データやノイズの混入に対応する相関係数
上に掲載したブログの記事では,線形データに対するピアソンの積率相関係数(以下,ピアソン)を計算した例を紹介しています。
ここでは,ピアソン以外の相関係数を紹介したいと思います。
スピアマンの順位相関係数
「順序化」あるいは「順位化」とは,データの集合に対し,データの値の大小関係を用いて,データが集合の中で何番目に大きいか(あるいは小さいか)という値に変換することを言います。この変換により,一般に外れ値に強くなり,データ集合全体の傾向が掴みやすくなります。
ピアソンの計算式に,実際の値ではなく順位化した値を代入して計算した係数を「スピアマンの順位相関係数(以下,スピアマン)」と言います。
下は,Wikipediaによるピアソンとスピアマンの比較の例です。
最初の例は,非線形データに対する対応についてです。
X座標が増加するにつれY座標も増加しているので,X座標とY座標との間には相関関係があると考えるのが自然ですが,ピアソンでは0.88という値に留まっているのに関わらず,スピアマンでは1.0という値が計算されるとされています。

By Skbkekas – Own work, CC BY-SA 3.0, Link
次の例は,外れ値の影響についてです。
図の左側を見るとX座標が増加するにつれY座標が増加しており,明らかに正の相関があることが見て取れます。しかし,図の右側にいくつか外れ値があり,その影響でピアソンは0.67という低い値になっていますが,スピアマンでは0.84という高い値を示しています。

By Skbkekas – Own work, CC BY-SA 3.0, Link
では,スピアマンなら何でも大丈夫かというと,そんなことはありません。
次の例は,X座標が増加するにつれ,Y座標は減少してから増加に転ずるデータです。X座標とY座標に関連性があるのは確かですが,ピアソンでは-0.13,スピアマンでも-0.099と関連性が無いような値が計算されています。

Mutual Information(MI; 相互情報量)
相互情報量は次式で定義され,一般化された相関係数として使用されています。

確率分布同士が互いに独立なら(⇔
 )対数関数の引数が1となることから相互情報量がゼロになることから,相互情報量の値を計算することにより,2つの分布が独立かどうか(相関があるかどうか)が推定できます。相互情報量は機械学習を始め色々な用途に使われているのですが,相互情報量なら何でも大丈夫かと言うとそんなことはありません。
)対数関数の引数が1となることから相互情報量がゼロになることから,相互情報量の値を計算することにより,2つの分布が独立かどうか(相関があるかどうか)が推定できます。相互情報量は機械学習を始め色々な用途に使われているのですが,相互情報量なら何でも大丈夫かと言うとそんなことはありません。次の図は三角関数のグラフに,右に行くに連れ大きなノイズを加えたデータです。ノイズが混入することにより関数としての変数xとyの関連性が弱くなっていくので相関係数は右に行くに連れ小さくなって欲しいです。

いくつかの手法で係数を計算すると以下のようになります。
- 左
- 相互情報量=1.5
- R-AMIC=0.8
- ヒルベルト・シュミット独立性規準=0.1
- 真ん中
- 相互情報量=0.88
- R-AMIC=0.74
- ヒルベルト・シュミット独立性規準=0.05
- 右
- 相互情報量=0.9
- R-AMIC=0.48
- ヒルベルト・シュミット独立性規準=0.02
R-AMIC(以前のブログで説明したもの)やヒルベルト・シュミット独立性規準(のちほど説明)は右に行くほど順調に値が小さくなっており関連性が弱くなっていることを判定していますが,相互情報量は真ん中から右に行くと逆に値が大きくなってしまいます。
ただまぁ,この結果から,相互情報量はピアソンに比べると非線形データに対応していることは分かります。
Distance Covariance(dCov; 距離共分散)
距離共分散は統計的な特性関数から計算される量で,距離分散で正規化することで距離相関を計算することができます。
特性関数は確率分布に1-1に対応して存在し,確率分布同士が互いに独立なら(⇔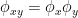
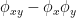
次の図はWikipediaによるもので,データの分布が直線以外でも相関係数がゼロにはならない値を取ることが示されています。

この距離共分散の計算は,ハイパーパラメータの選択により後に述べるHSICと等価になることが知られており,結局は行列計算に帰着することができます。
Maimal Information Coefficient(MIC; 最大情報量係数)
最大情報量係数は,入力されたデータの空間をグリッドに区切り,各グリッドの中で相互情報量を計算します。
その際,様々な区切り方を試して相互情報量が最も大きくなる区切り方を探索します。例えば,次のイメージ図では,データが3つある空間で左は4×4=16のグリッドに,右は2×2=4のグリッドに区切っています。
グリッドの中でデータが占める割合は,左は3/16≒0.19,右は2/4= 0.5で右の方が密度が高くなっており,情報量が大きくなります。この例では縦と横を同じ数で区切っていますが,より複雑な区切り方をすることで相互情報量のみだとうまくいかなかったノイズの混入した非線形データに対応します。

Hilbert-Schmidt Independence Criterion(HSIC; ヒルベルト・シュミット独立性規準)
ヒルベルト・シュミット独立性規準は,カーネル法によって入力データをカーネル計算,すなわち行列計算に帰着させることでデータ同士が独立かどうか(相関があるかどうか)を計算します。
アイディアとしては,まず線形代数における次のような事実を思い出します。
- 入力データxとyが独立なら,期待値をE(x)として次の共分散がゼロに近い値を取る

ピアソンは,この共分散を正規化したものに他なりません。
この性質は入力データが多次元でも成り立ち,計算結果は相互共分散行列と呼ばれる行列になります。

2次元の場合,相互共分散行列は2×2の対角行列になり,相関を表す主要な成分である対角成分では無い値を計算すると次のようになります(正規化していないピアソンの値に等しくなります)。

同様に,カーネル法でもRKHS(Reproducing Kernel Hilbert Space; 再生核ヒルベルト空間)の中で相互共分散行列のようなものが定義でき,次のようになります。
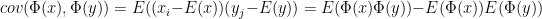
従って距離共分散の場合と同様のイメージで,2つのデータが独立なら同時生起確率がp(x,y)=p(x)p(y)となる(すなわちp(x,y)-p(x)p(y)がゼロに近くなる)ことと対応して,この量を計算することで2つの分布が独立かどうか(相関があるかどうか)が推定できます。
 はカーネルの基底関数と呼ばれるもので,まさにカーネル法のポイントとなる技術により
はカーネルの基底関数と呼ばれるもので,まさにカーネル法のポイントとなる技術により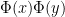 などは基底関数に関係なくカーネル関数の評価に帰着しますので,最終的にヒルベルト・シュミット独立性規準は行列計算に帰着することができます。
などは基底関数に関係なくカーネル関数の評価に帰着しますので,最終的にヒルベルト・シュミット独立性規準は行列計算に帰着することができます。
Bagging Nearest-Neighbor Prediction independence Test(BNNPT; バギング最近傍予測独立性テスト)
こちらは最近傍探索をした結果を並べ替え検定を計算して独立性を計算するようですが,配布されているプログラムが動かなかったので確認していません。
ただしこちらの論文は昨年2017年に発表になっており,非線形データの相関を計算する研究は続いているということだと考えております。
色々な手法で相関係数を計算する
いくつかの2次元の線形・非線形,ノイズ混入有り・ノイズ混入無しのデータを用意し,横軸と縦軸の関連性を計算してみた結果が次の表です。
(各データの詳細については,文献[佐藤,2018]を御参照下さい)

青い矢印は相関の無いデータであり,相関係数は小さくなければなりません。それ以外は相関があるデータで,相関係数は大きい値を取るのが正解です。
数値に引いてある赤い下線は,その手法で計算した値のうち大きな値上位2つを示しており,青い下線は小さな値下位2つを示しています。
すぐに分かる結果としては,次のようなものが上げられます。
- 線形の相関がある直線のデータに対しては,全ての手法が大きな相関値を出している
- ノイズが混入していない人口データに対しても,全ての手法が大きな相関値を出している。ただし,ピアソンとスピアマンは-1から1の値を取るもので(他の手法はマイナスの値は取らない),プラスの値を取っていることは年代が上がるほど人口が増加するという誤った結論を出している
- 疑似相関に引っかかっている手法が多い
- 全ての例において,開発したR-AMICのみが期待通りの結果が出ている
ただし,これらの手法は互いに関係があり,最終的にはほとんど同じ精度になると思われます。例えば相互情報量を推定するのにカーネル法を使うことがある,カーネル法の双対空間の概念は情報幾何学に他ならない,共通の情報量規準でモデル選択をすることができる,など多くの類似点があります。
おわりに
ピアソンの積率相関係数,スピアマンの順位相関係数といった線形データに対する相関係数の計算方法に加え,非線形データに対する相関係数について紹介しました。
最終結果としては微差で我々が開発したR-AMICが最も良い結果を出しているのですが,実のところどの手法も互いに関係のある沢山の理論で結びついており,どれか一つが万能で圧倒的な正確性を持つということはありません。
それぞれ,計算コストや設定しなければならないパラメータなどが違いますので,やはり目的に合った手法を使わなければなりません。
弊社では,これらの手法を簡単に使えるAPIを開発しておりますので,利用してみたい方がおられましたらこちらからご連絡を下さい。
参考文献
- G. J. Székely, M. L. Rizzo and Nail K. Bakirov, Measuring and Testing Dependence by Correlation of Distances, Ann. Stat., Vol. 35, No. 6, pp. 2769–2794, 2007.
- D. N. Reshef, Y. A. Reshef, H. K. Finucane, S. R. Grossman, G. McVean, P. J. Turnbaugh, E. S. Lander, M. Mitzenmacher, and P. C. Sabeti, Detecting Novel Associations in Large Data Sets, Science, Vol. 334, No. 6062, pp. 1518-–1524, 2011.
- A. Gretton, K. Fukumizu, C. H. Teo, L. Song, B. Schölkopf, and A. J. Smola, A Kernel Statistical Test of Independence, Proc. NIPS 2007, pp. 585-–592, 2007.
- Y. Wang, Y. Li, X. Liu, W. Pu, X. Wang, J. Wang, M. Xiong, Y. Y. Shugart and L. Jin, Bagging Nearest-Neighbor Prediction independence Test: An Efficient Method for Nonlinear Dependence of Two Continuous Variables, Sci. Rep., Vol. 7, No. 12736, 2017.
- 佐藤哲,確率的な再サンプリング法に基づく非線形系に対する相関係数計算, 情処全大, 4B-05, 2018.
- 距離相関のRパッケージドキュメント
- 最大情報量係数のRインターフェース
- ヒルベルト・シュミット独立性規準のRパッケージ
- バギング最近傍予測独立性テストのRパッケージ
(距離共分散の論文)
(最大情報量係数の論文)
(ヒルベルト・シュミット独立性規準の論文)
(バギング最近傍予測独立性テストの論文)
(R-AMICの文献)
テックブログ新着情報のほか、AWSやGoogle Cloudに関するお役立ち情報を配信中!
Follow @twitter
大学で民俗学や宗教についてのフィールドワークを楽しんでいたのですが,うっかり新設された結び目理論と幾何学を勉強する研究室に移ってしまい,さらに大学院では一般相対性理論を研究するという迷走した人生を歩んでいます.プログラミングが苦手で勉強中です.
Recommends
こちらもおすすめ
-

VAEを用いたUNIXセッションのなりすまし検出
2018.12.17
-

機械学習 オーバーフィッティング(過学習)について
2016.5.31
-

機械学習を学ぶための準備 その3(行列について)
2015.12.6
-

機械学習 曲線フィッテングについて おまけ?編
2016.4.28
-

手を動かして GBDT を理解してみる
2019.5.24

{kind=link}
Special Topics
注目記事はこちら

データ分析入門
これから始めるBigQuery基礎知識
2024.02.28

AWSの料金が 8 %割引になる!
『AWSの請求代行リセールサービス』
2023.01.15