FIT2018 第17回情報科学技術フォーラム参加報告(2)メタ分析編

こんにちは。データサイエンスチームのtsです。
弊社は東京都内は虎ノ門にありますが、私は現在、学会参加のため九州に来ております。
FIT2018 第17回情報科学技術フォーラム参加報告(1)
今回は、二日目参加終了時点での、データ分析に関する学会発表内容のメタ分析を紹介したいと思います。
1日目・2日目と、私は特別なテーマが設けられたセッションではなく、一般的な機械学習関連のセッションに参加しました。
その講演内容の主観的かつ大雑把な統計データを作ってみましたので、どうぞ御覧ください。
分析対象とした発表は、特別なイベント講演ではなく一般参加者の講演の23件の内容です。
まず、大学関係者の参加が多い印象のある学会発表ですが、今回はどうだったか確認してみました。
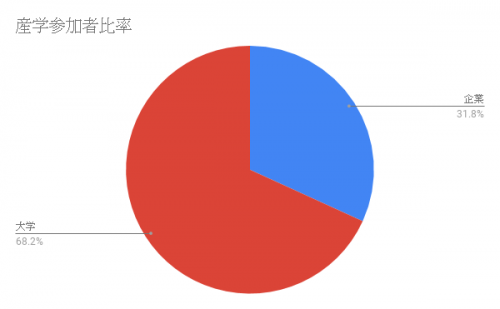
3割が企業の方でした。とは言え、いわゆる大企業の方々だったように思います。
さて、機械学習関連の複数のセッションの中で、使われていた手法について確認すると、こんな感じでした!
ジャンルの粒度が違ったり複数の手法を主観で一つにまとめたりしてますが、あくまで目安ということで。
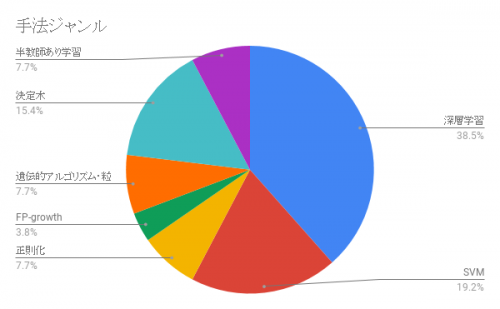
ディープラーニングが4割だったのは流行っているので納得ですが、意外とサポートベクターマシンやランダムフォレスト、2分木などを使った発表も多かったです。
ただ、ディープラーニングにしてもサポートベクターマシンにしても、発表内でアルゴリズムやパラメータ、カーネル関数などには触れられていないものが多く、ライブラリ/APIの中身をちゃんと理解しているのか疑問に思う発表もありました。
ところで決定木やSVMが意外と多かった理由の一つに、しっかりと研究され原理が解明されていることだろうと思われる結果があります。発表のうち、研究の目的を「学習及び学習に基づくモデル適用結果の解釈性・説明根拠を明らかにすること」と述べていた発表数の割合を出してみました。
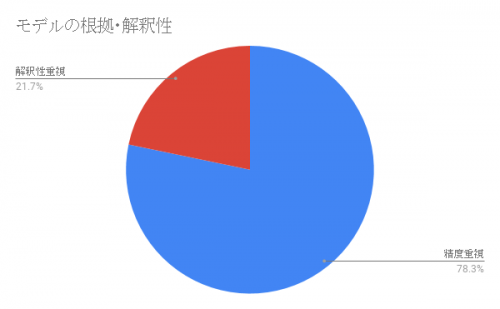
2割の研究が、機械学習がなぜどうやってそう判断しているか、その根拠を明らかにするというものでした。その研究に使われている手法はディープラーニングに限ったものでは無く、医療関係など人間生活に深く関わる研究は、明確な説明責任がコンピュータアルゴリズムに対しても必要とされるということでした。
最後に、どんなデータをメインターゲットに研究されているかを調べてみました。
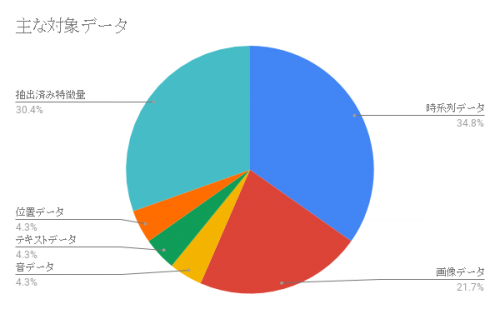
画像データが多いのは、やはりディープラーニングの研究が多かったからのように思えますが、意外と時系列データが対象の研究が多かったです。これは、やはり機械学習ならではの人間の能力を超える時間軸に対する「未来の予測・推論」に対する需要が多いからのようです。また、対象データの種別を問わない汎用性を目指した研究(抽出済み特徴量を対象とするもの)が多いのも印象的でした。
次回は、発表された研究内容を紹介できたらいいなと思う今日このごろです。

大学で民俗学や宗教についてのフィールドワークを楽しんでいたのですが,うっかり新設された結び目理論と幾何学を勉強する研究室に移ってしまい,さらに大学院では一般相対性理論を研究するという迷走した人生を歩んでいます.プログラミングが苦手で勉強中です.


Recommends
こちらもおすすめ
-

FIT2018 第17回情報科学技術フォーラム参加報告(3)ブース編
2018.9.21
-

FIT2018 第17回情報科学技術フォーラム参加報告(1)FIT2018概要編
2018.9.20
-

機械学習 曲線フィッテングについて 後編
2016.4.13



Special Topics
注目記事はこちら

データ分析入門
これから始めるBigQuery基礎知識
2024.02.28

AWSの料金が 10 %割引になる!
『AWSの請求代行リセールサービス』
2024.07.16