Workload Identityを用いたGoogle CloudとAWSの連携
2025.10.9

はじめに
こんにちは、Ganonです。
近年、マルチクラウドというフレーズを聞く機会が多くなってきたのではないでしょうか。
ここでは、AWSとGoogle Cloudの連携に用いる、Workload Identityについて紹介します。
Workload Identity連携とは
従来のサービスアカウントキーの代わり外部の認証サーバーが発行したIDを用いて、オンプレミスやマルチクラウド環境からGoogle Cloudリソースにアクセスできます。
具体的には、外部システムが持つ認証トークンをGoogle Cloudのセキュリティトークンサービス(STS)に提示し、短期間有効なアクセストークンと交換します。このトークンを使用して、指定されたサービスアカウントの権限でGoogle Cloudのリソースにアクセスできるようになります。
また、サービスアカウントキーとは異なり、構成ファイルに機密情報が含まれていないことでアクセス権の漏洩には繋がらないことがメリットとなります。
サービスアカウントキーとは
ユーザー名やパスワードと同様に認証方法の一つです。有効なサービスアカウントキーにアクセスできるユーザーは、このキーを使用して認証を行い、サービスアカウントの権限でリソースを使用できます。
出典:サービスアカウントキーを管理するためのベストプラクティス
Workload Identityプール
外部IDを管理するエンティティです。
Workload Identityプールのプロバイダ
Google CloudとIdPの間の関係を記述するエンティティです。これには以下のものが含まれます。
- AWS
- Microsoft EntraID
- GitHub
- GitLab
- Kubernetesクラスタ
- Okta
- オンプレミスのActive Directoryフェデレーションサービス(AD FS)
- Terraform
※IdPとはユーザーが誰であるかを証明し、他のサービスでも共有することができる仕組みです。
出典:Workload Identity連携
Workload Identityを利用した具体例
- AWS LambdaやAmazon ECSからVertex AIを呼び出す
- AWS CodeBuildを使ってGoogle Cloudリソースを展開するTerraformを実行する
- AWS LambdaやAmazon ECSとBigQueryを連携する
Workload Identityを用いたGoogle CloudとAWSの連携
1.Google Cloudでサービスアカウントを作成する
Google Cloudにアクセスするためにサービスアカウントを作成します。
次に、以下の権限を付与します。
- Storage オブジェクト ユーザー
- サービス アカウント トークン作成者
サービスアカウントに関して
サービスアカウントは、人間ではなくアプリケーションやVM、その他Google Cloudリソースなどが操作・認証するときに使う特殊なアカウントです。
通常のユーザーアカウントとは異なり、ブラウザでログインしてコンソール操作をするためのアカウントではありません。

2.Workload Identityプールを作成する
AWSとの連携のためWorkload Identityプールを作成します。
- 名前と説明を入力します
- AWSアカウントIDを入力します
- プロバイダの属性は設定なしで大丈夫です
3.アクセス権を付与する
コンソール画面上の方に記載されている「アクセスを許可」を選択し、サービスアカウント権限借用を利用してアクセス権を付与します。
- サービスアカウントは1で作成したアカウントを選択する
- プリンシパルの属性名:アクセスを許可する際に作成した「aws-role」を選択する
- プリンシパルの属性値:arn:aws:sts::(AWSアカウントID):assumed-role/(IAM ロール名)とする
最後に構成をダウンロードします。
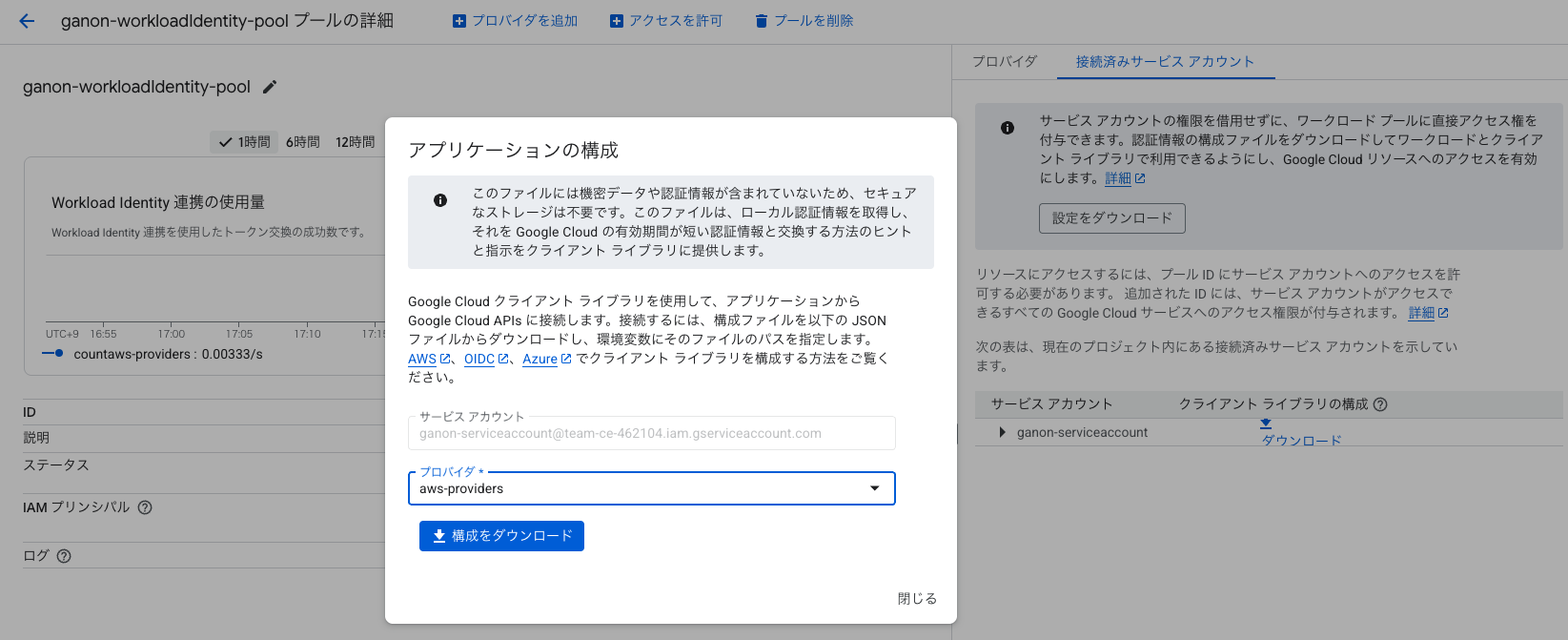
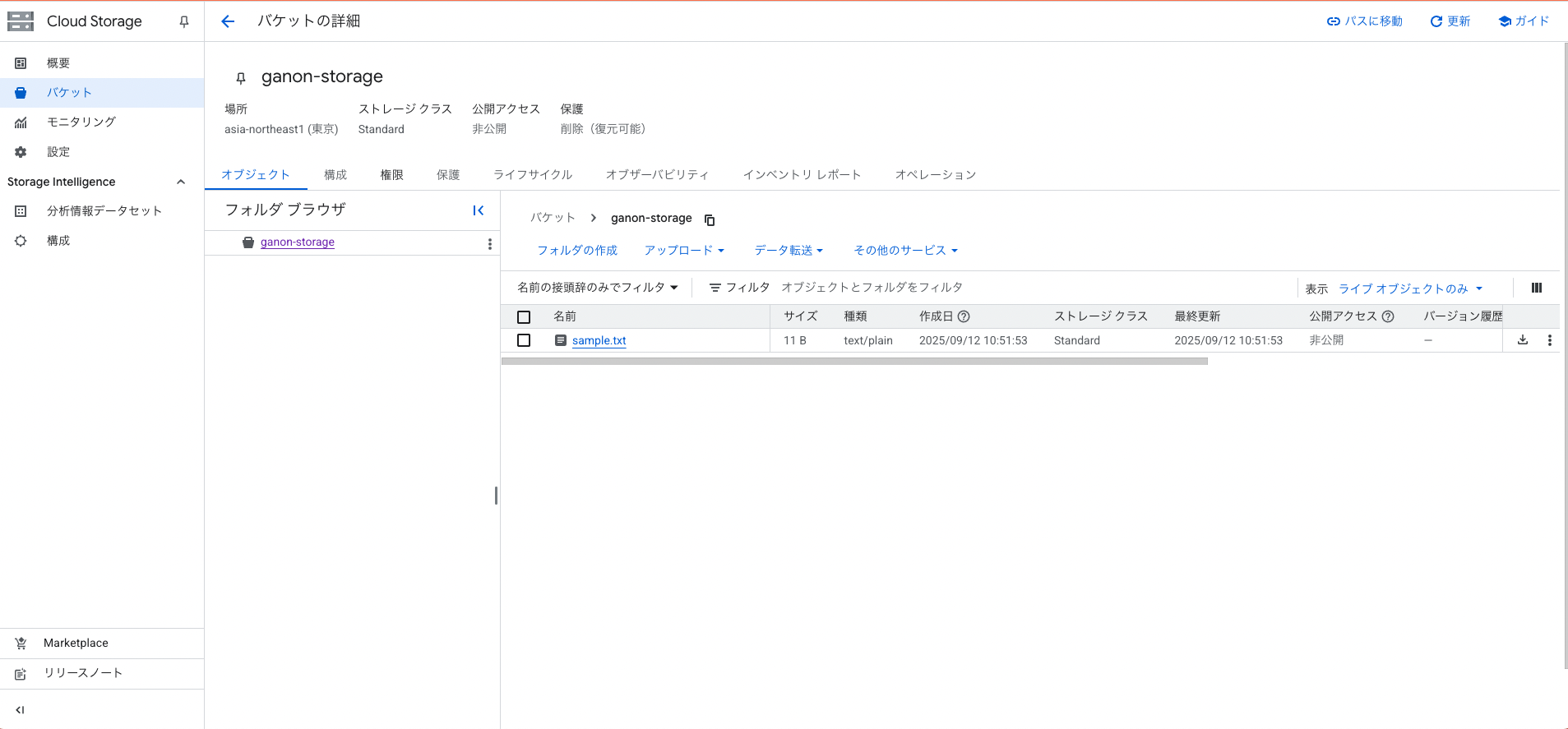
4.Cloud Storageにデータを保管する
データ送信用のsample.txtを作成後、Cloud Storageに保存します。
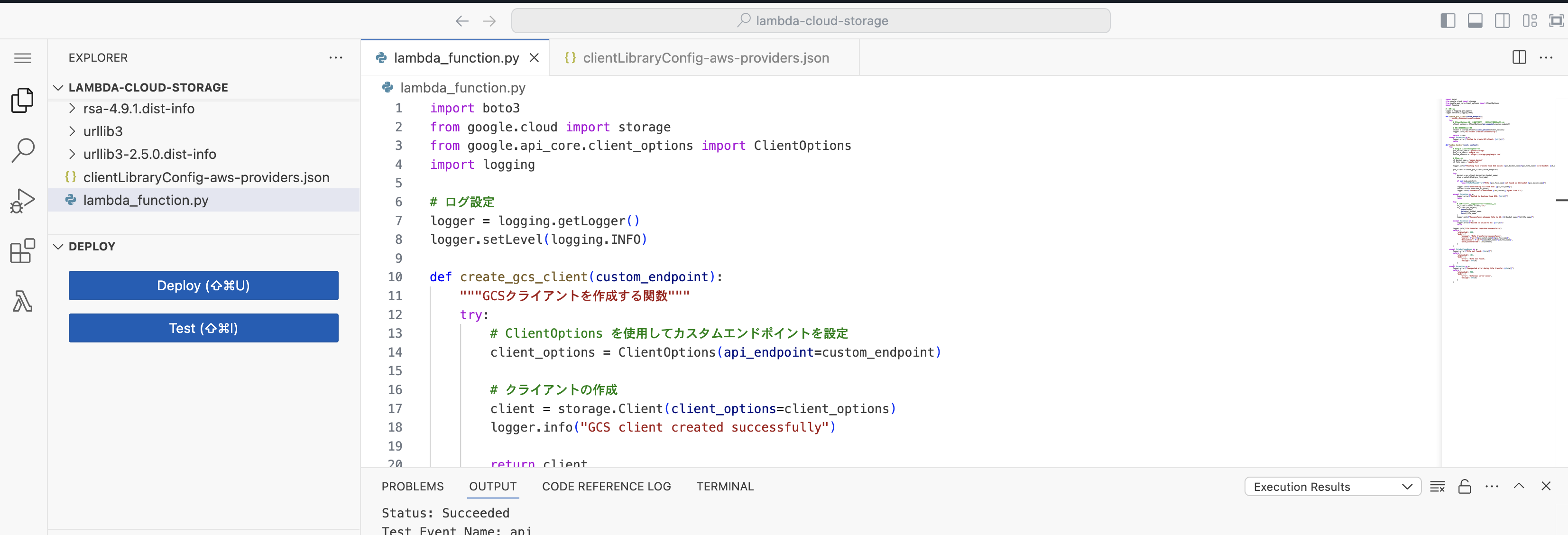
5.AWS LambdaでCloud StorageからAmazon S3にデータを渡すコードを記述する
コードは以下になります、Pythonはバージョン3.11を使用します。
import boto3
from google.cloud import storage
from google.api_core.client_options import ClientOptions
import logging
logger = logging.getLogger()
logger.setLevel(logging.INFO)
def create_gcs_client(custom_endpoint):
try:
client_options = ClientOptions(api_endpoint=custom_endpoint)
client = storage.Client(client_options=client_options)
logger.info("GCS client created successfully")
return client
except Exception as e:
logger.error(f"Failed to create GCS client: {str(e)}")
raise
def lambda_handler(event, context):
try:
# Google Cloud Storageの設定
gcs_bucket_name = '<<Cloud Storageのバケット名>>'
gcs_file_name = 'sample.txt'
custom_endpoint = 'https://storage.googleapis.com'
# S3の設定
s3_bucket_name = '<<Amazon S3のバケット名>>'
s3_file_name = 'sample.txt'
logger.info(f"Starting file transfer from GCS bucket: {gcs_bucket_name}/{gcs_file_name} to S3 bucket: {s3_bucket_name}/{s3_file_name}")
gcs_client = create_gcs_client(custom_endpoint)
try:
bucket = gcs_client.bucket(gcs_bucket_name)
blob = bucket.blob(gcs_file_name)
if not blob.exists():
raise FileNotFoundError(f"File {gcs_file_name} not found in GCS bucket {gcs_bucket_name}")
logger.info(f"Downloading file from GCS: {gcs_file_name}")
content = blob.download_as_bytes()
logger.info(f"Successfully downloaded {len(content)} bytes from GCS")
except Exception as e:
logger.error(f"Failed to download from GCS: {str(e)}")
raise
try:
s3_client = boto3.client('s3')
s3_client.put_object(
Body=content,
Bucket=s3_bucket_name,
Key=s3_file_name
)
logger.info(f"Successfully uploaded file to S3: {s3_bucket_name}/{s3_file_name}")
except Exception as e:
logger.error(f"Failed to upload to S3: {str(e)}")
raise
logger.info("File transfer completed successfully")
return {
'statusCode': 200,
'body': {
'message': 'File transferred successfully',
'source': f'gs://{gcs_bucket_name}/{gcs_file_name}',
'destination': f's3://{s3_bucket_name}/{s3_file_name}',
'bytes_transferred': len(content)
}
}
except FileNotFoundError as e:
logger.error(f"File not found: {str(e)}")
return {
'statusCode': 404,
'body': {
'error': 'File not found',
'message': str(e)
}
}
except Exception as e:
logger.error(f"Unexpected error during file transfer: {str(e)}")
return {
'statusCode': 500,
'body': {
'error': 'Internal server error',
'message': str(e)
}
}
6.IAM ロールを編集します
AWS Lambdaに付与されているIAM ロールを編集し、以下の権限を付与する。
- AmazonS3FullAccess
- AWSLambdaBasicExecutionRole

7.パッケージの作成と環境変数を設定する
パッケージの作成は任意の環境で実行します。
AWS Lambdaで使用するCloud Storageライブラリをworkディレクトリにインストールします。
docker run --rm -v $(pwd):/work -w /work python:3.11 pip install google-cloud-storage -t .
現在のディレクトリの内容を、一つ上の階層にzipファイルとして作成します。
zip -r ../function.zip .
作成したzipファイルをAWS Lambdaで展開します。
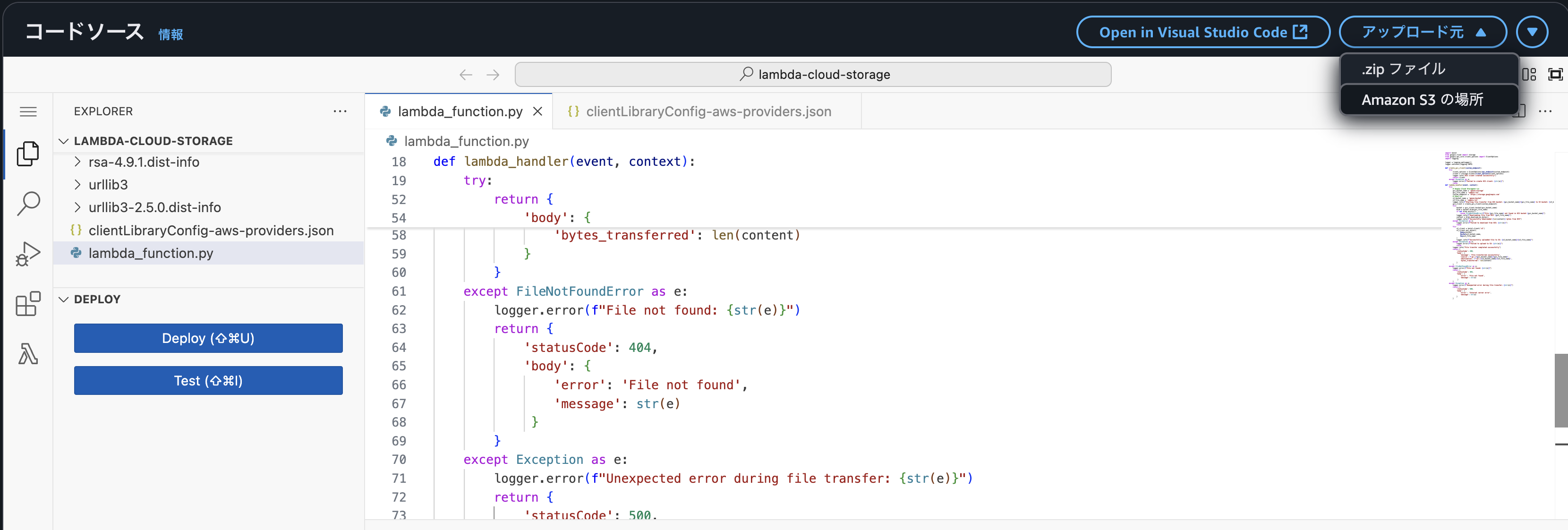
AWS LambdaのPythonファイルがあるディレクトリに3でダウンロードしたプロバイダー情報をドラック&ドロップします。
8.テストを実行する
テストに関する設定はデフォルトです。
statusCode200が返れば成功です。
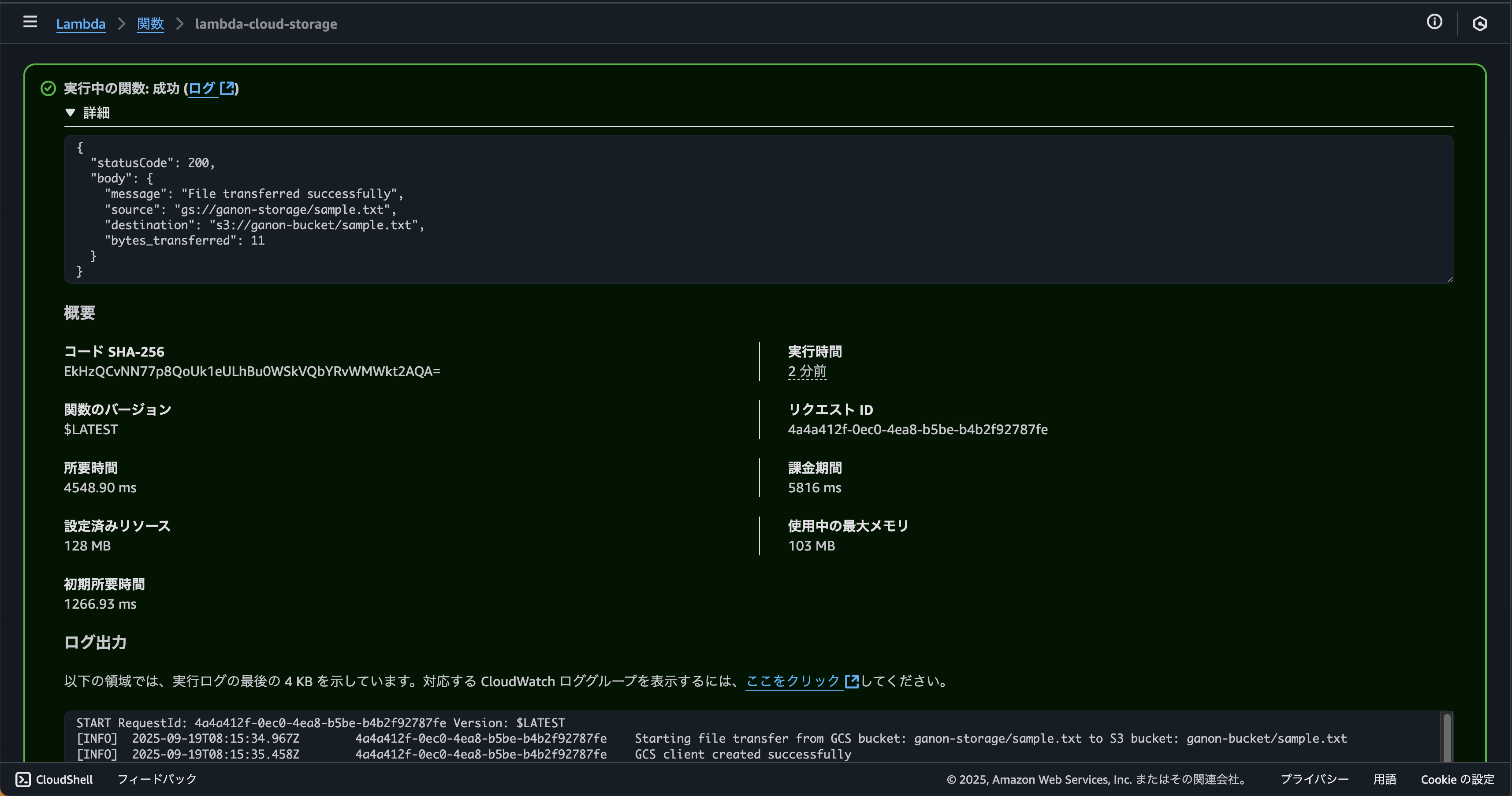
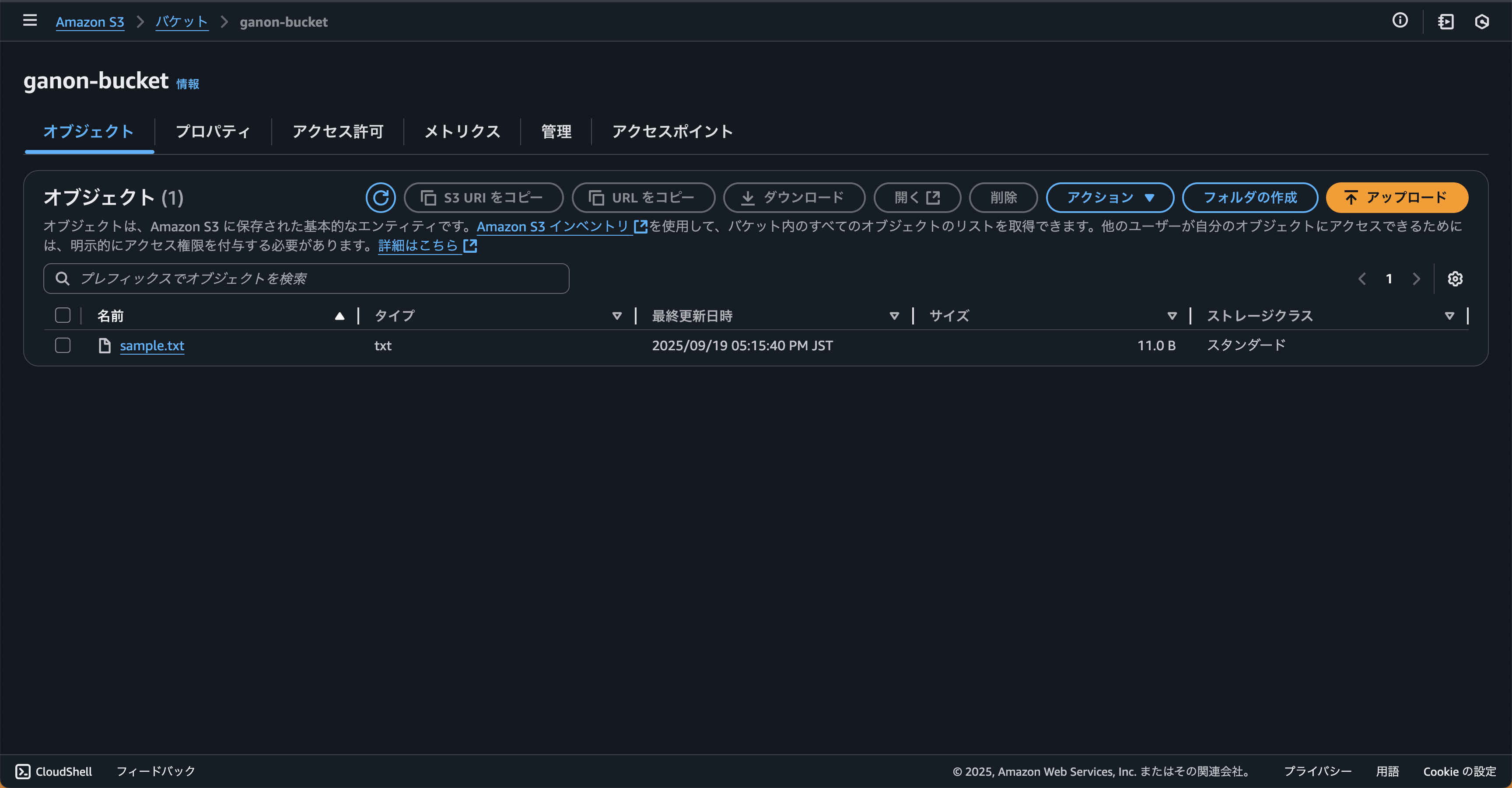
9.Amazon S3を確認する
Cloud Storageに作成したsample.txtがAmazon S3に転送されていることを確認します。
最後に
AWSとGoogle Cloudという異なるクラウドプロバイダー間でのシームレスな連携が、構成ファイルを渡すだけでこれほど実用的に実現できることに驚きました。
マルチクラウドが注目される今、AWSとGoogle Cloudの優れた特性を活かした連携により、サービス価値の最大化が図れると考えます。

筋肉で解決するタイプのエンジニア


Recommends
こちらもおすすめ
-

Amazon Bedrock を API キー で管理する
2025.8.8





Special Topics
注目記事はこちら

データ分析入門
これから始めるBigQuery基礎知識
2024.02.28

AWSの料金が 10 %割引になる!
『AWSの請求代行リセールサービス』
2024.07.16