再利用性を意識したデータ分析基盤の構築事例(AWS+Looker)

はじめに
こんにちは。データサイエンスチームのmotchieです。
データ活用を進める際は、大規模データを蓄積・集計・可視化できるデータ分析基盤が必要になります。
AWSには、データレイクのAmazon S3、データウェアハウス(DWH)のAmazon Redshiftなど、ビッグデータの活用を支援する様々なサービスがあります。
この記事では、実際にNHN テコラス社内で構築・運用しているシステム事例を紹介しながら、AWSのベストプラクティスに沿ってデータ分析基盤を構築していく方法をご紹介します。
記事の流れは以下の通りです。
- システムの概要と構成図
- AWS Well-Architected フレームワークによる全体設計
- CloudFormationによるDWH構築
- ネストされたスタックの活用
- Secrets Managerで認証情報の一元管理
- Step FunctionsによるETLパイプライン
- Step Functionsの活用
- LookerによるBI構築
- LookMLの活用
- SSHトンネルによる接続の保護
- AWSコストの削減
- C-Chorusの活用
システムの概要と構成図
現在、データサイエンスチームでは社内データの分析・可視化のため、下記のデータ基盤を構築・運用しています。
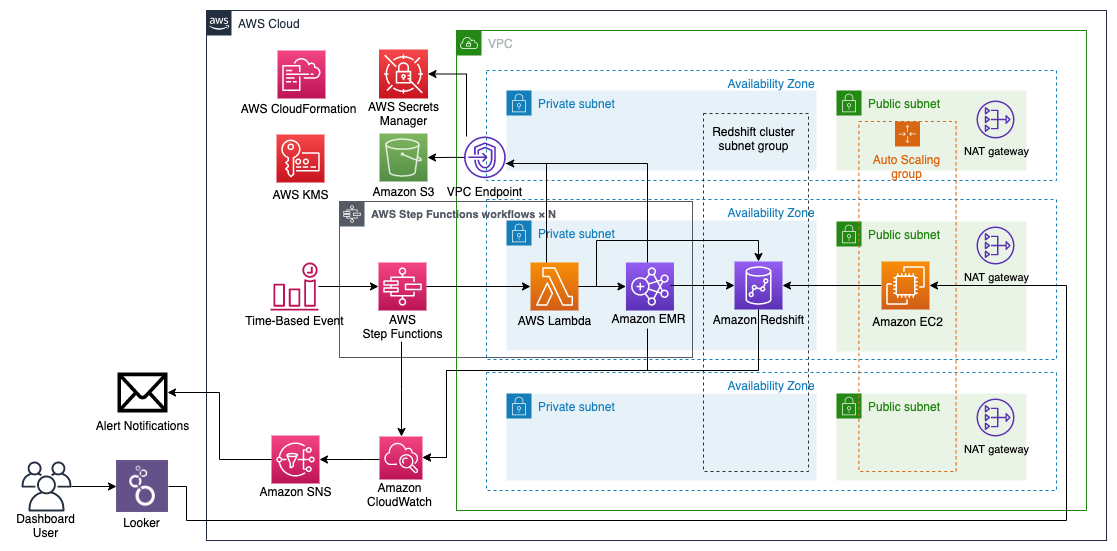
構成の概要としては、データレイクとしてS3を活用し、S3に蓄積されたデータをStep FunctionsによるETLパイプラインでRedshiftに読み込み、LookerからRedshiftにクエリを投げてデータを集計・可視化し、社内ユーザーにダッシュボードを提供しています。
上記のデータ基盤の設計では、以下のように各コンポーネントをコード化することで、各コンポーネントの再利用性を向上させています。
- CloudFormationで機能ごとテンプレートを分けて、インフラをコード化する
- Step Functionsでジョブ実行・エラー処理・タイムアウトというETLパイプラインをコード化する
- Lookerのデータモデリング言語(LookML)でデータの定義・集計・ダッシュボードをコード化する
上記のように、DWH、ETL、BIの各部分のコード化を進めていくことで、機能追加や修正における冗長な作業のコストを減らし、開発を迅速に進めることができます。
以下では、DWH、ETL、BIの各コンポーネントについて、内容を詳しく見ていきたいと思います。
その前にまずは、システムの設計段階でチェックしておきたいAWS Well-Architected フレームワークの紹介から始めていきたいと思います。
AWS Well-Architected フレームワークによる全体設計
AWSでは、クラウド上でシステムを設計・運用する際のベストプラクティスがAWS Well-Architected フレームワーク(以下WAフレームワーク)として公開されています。
WAフレームワークでは、以下の5つの柱に関して、設計・運用のベストプラクティスとチェックシートがまとめられています。
- 運用上の優秀性
- セキュリティ
- 信頼性
- パフォーマンス効率
- コスト最適化
WAフレームワークの概要とチェックシートについては、こちらの内容もわかりやすいです。
[AWS Black Belt Online Seminar] AWS Well-Architected Framework 資料及び QA 公開
さらに、各領域に特化したベストプラクティスがレンズとして公開されており、以下の分析レンズでは、ETLを初めとした分析アプリケーション向けのベストプラクティスがまとめられています。
Analytics Lens – AWS Well-Architected Framework
ドキュメントの量は多いですが、WAフレームワークのチェックリストに目を通しておくと、設計段階で検討すべきポイントに気づくことができ、手戻りが発生するリスクを削減できます。
CloudFormationによるDWH構築
WAフレームワークの運用上の優秀性の柱において、インフラをコードで管理し、デプロイを自動化する重要性が挙げられています。
また、セキュリティの柱では、本番環境と開発環境でAWSアカウントを分けることが推奨されています。
そんなときに使えるのがAWS CloudFormation(以下CFn)です。CFnを使うことで、YAMLやJSON形式のテンプレートでインフラを記述・管理でき、デプロイ作業をコマンドで自動化できるため、複数のAWSアカウントで同じインフラ環境を構築するのも容易になります。
CFnは、サンプルコードとテンプレートの例として多くのリソースが公開されており、AWSリソースおよびプロパティタイプのリファレンスではJSON/YAMLのコード例が多く掲載されており、利用可能なリソースが多いです。
さらに、DWHの構築では、下記のブログで公開されているテンプレートが活用できます。
AWS CloudFormation を使用して Amazon Redshift クラスターの作成を自動化する
上記のテンプレートを活用することで、WAフレームワークのベストプラクティスに沿ったRedshift環境を簡単に構築することができます。テンプレートの詳細については、上記のブログ記事をご確認ください。
この記事のデータ基盤の構築では、インフラコード化の利点を更に得るために、いくつか修正を行いました。
以下では、修正点についていくつかご紹介していきます。
ネストされたスタックの活用
上記のブログ記事で公開されているテンプレートは、機能ごとに3つのテンプレートに分割されており、それによってテンプレートの可読性と再利用性が向上しています。
テンプレートを分けて、別のスタックとしてデプロイする場合、スタック間で設定値をやりとりする必要があります。
そのために上記のブログ記事ではクロススタック参照が用いられており、参照される側のスタックのOutputsセクションで値を出力し、参照する側のテンプレートではFn::ImportValue関数を使い、値を取得しています。
ただ、クロススタック参照には、以下のような課題点もあります。
- テンプレート(スタック)の数だけデプロイを実行が必要になる。また、削除する際も、スタック間の依存関係を考慮した順で一つずつスタックの削除を行う必要がある
- 他のスタックからリソースの値が参照されている場合、そのリソースを削除したり、出力値が変わるような変更を行うことができない。そのためにはまず、参照している側のリソースを一旦削除する必要がある
- スタック間でどのように値の参照が行われているのか概観できず、各テンプレートを見る必要がある
こんなときに活用できるのが、ネストされたスタックです。
親スタックのテンプレートでAWS::CloudFormation::Stackタイプのリソースとしてネストされたスタック(子スタック)を作成することができます。子スタック間での設定値のやりとりは、親スタックを介して行うことができます。
これにより、以下のような利点が得られます。
- スタック全体の作成/更新/削除を最上位の親スタック(ルートスタック)のデプロイ一発で行える
- 親スタックを介してスタック間の依存関係を解決してくれるので、リソースの削除や変更時のリソース作り直しもCFn側で行ってくれる
- スタック間での値のやりとりは親テンプレートの記述を見て把握できる
本記事のデータ基盤では、親テンプレートを用意してルートスタックを作成し、VPC・踏み台サーバ・Redshift・ETLパイプライン(後述)といった子スタックをネストされたスタックとして取り込んでいます。
これにより、スタック間の設定値のやりとりを親テンプレートで概観でき、デプロイ時にスタック間の依存関係がルートスタックを通じて解決され、開発検証時の利便性が向上しました。
ネストされたスタックを活用することで、CFnが公開しているサンプルテンプレートや、AWS Serverless Application Repositoryで公開されているSAMのテンプレートなど、必要に応じてテンプレートを組み合わせてスタックを拡張していくことが容易になり、リソースの再利用による開発コストの削減と迅速な構築が可能になります。
ネストされたスタックを使用して共通テンプレートパターンを再利用する
Secrets Managerで認証情報の一元管理
また、前述のAWSブログのテンプレートでは、Redshiftのパスワードといった認証情報をスタックデプロイ時のコマンドで指定する形になっており、認証情報を安全に管理するためのリソースが含まれていませんでした。
そこで、本記事のデータ基盤では、AWS Secrets Managerのリソースを追加し、各種認証情報の一元管理を行っています。
CloudFormationとSecrets Managerを組み合わせることで、以下のようなメリットが得られます。
- CloudFormationのテンプレートでSecrets Managerのリソースを記述できるため、認証情報のリソースもインフラコード化の対象に含められる
- CloudFormationのテンプレートで認証情報の自動生成・自動ローテーションの設定を記述できる
Secrets Managerの使い方や他のサービスとの比較については、以下の記事で解説しています。
AWS Serverless Application RepositoryからSAMテンプレートを取り込む方法についても例を記載しています。
ぜひご覧になってみてください。
CloudFormationで認証情報を扱うベストプラクティス
Step FunctionsによるETLパイプライン
データサイエンスチームではこれまで、ビッグデータの処理では主にAmazon EMR上のApache SparkジョブでETL処理を行ってきました。
EMRを使うことで、S3上に格納された大規模データの分散処理を効率的に行うことができます。
EMRクラスタの作成はLambdaとCloudWatchEventで自動化し、定期的なバッチ処理の実行時のみクラスタが立ち上がり、完了時にクラスタが自動終了することでコストを削減することができます。
さらに、データの量がそれほど多くない処理については、EMRの他にもLambda関数やAWS Batchを組み合わせてバッチ処理を行うことで、リソースを最適化してきました。
しかし、上記の構成にはいくつか課題がありました。
- EMRジョブの失敗時のリトライや処理遅延時のタイムアウトを行いたい場合、そのための仕組みを別途実装する必要がある
- ETLジョブ/サービスが増えるにつれて、ETLパイプライン全体の見通しや、処理の状況の把握が難しくなる
- EMRクラスタの設定がLambdaのコード内で管理されている(CloudFormationテンプレートから漏れている)
これらの課題を解決するためには、AWS Step Functionsが使用できます。
Step Functionsの活用
AWS Step Functions(以下SFN)を使用することで、様々なAWSのサービスを組み合わせたワークフローをステートマシンとして定義し、複数のステップからなるアプリケーションを実行することができます。
SFNのステートマシンは、ダイアグラムに変換され、処理の進行状況やエラー状況を視覚的にモニタリングできるため、ETLパイプライン全体の見通しがよくなります。
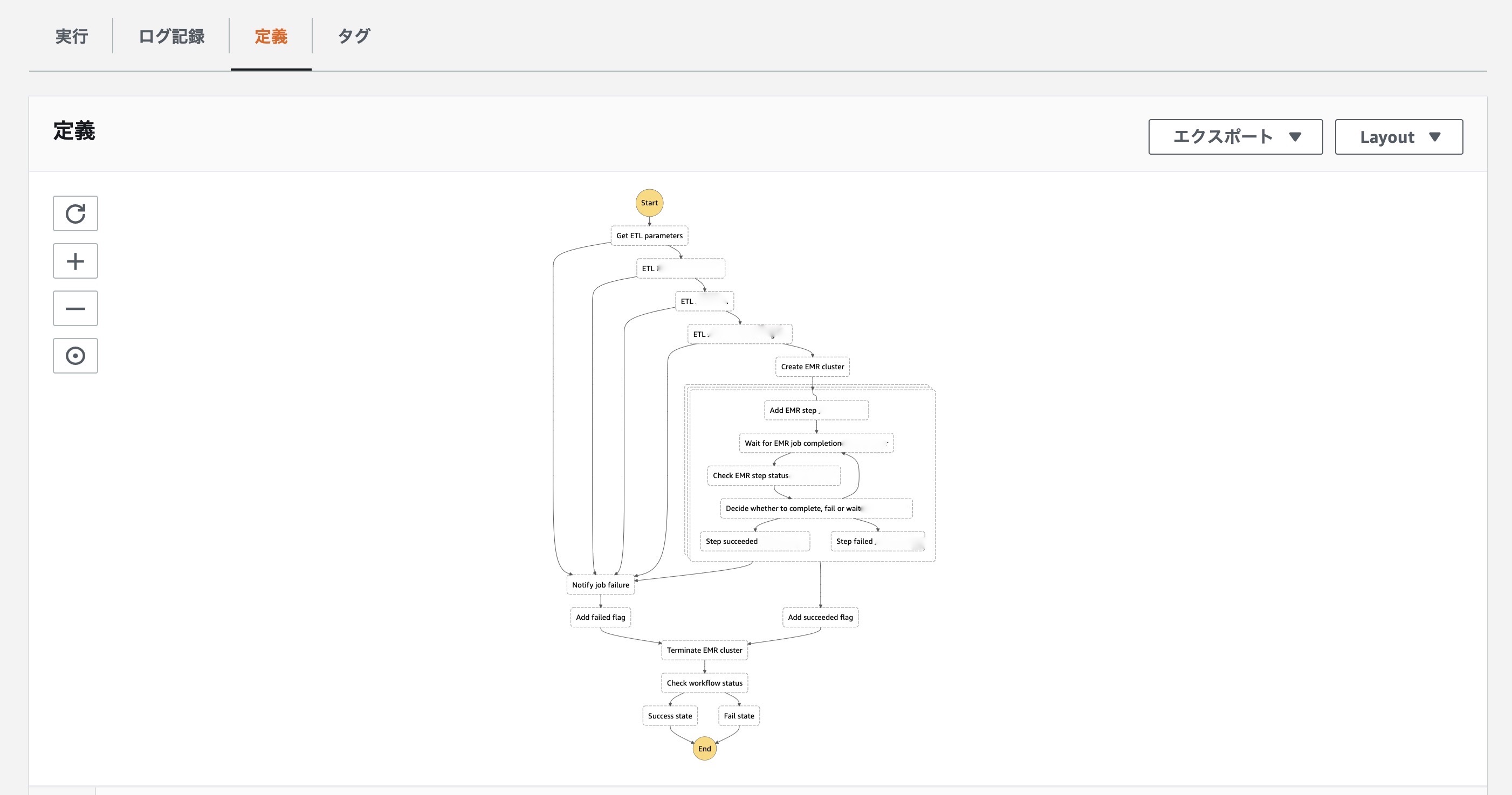
SFNは、Lambda関数を初め、EMR、Batchなど、様々なサービスと連携させることができ、ステートマシンから呼び出すことができます。
そのため、EMRクラスタの作成/削除・ステップの追加といった処理をLambda関数の実行ではなく、ステートマシン(json)で記述・自動化することができます。
AWS Step Functions 開発者ガイド: サービスの AWS Step Functions との統合
SFNでは、タイムアウトを使用して実行のスタックを回避するが可能です。
また、SFNでは、Retry フィールドを使うことで、エラー種別ごとに再実行の回数を設定でき、さらにCatchフィールドを使うことで、当該タスク失敗時に推移するタスク(エラーの通知やリソースの後始末など)を指定できます。
AWS Step Functions 開発者ガイド: Step Functions でのエラー処理
これにより、EMRジョブ失敗時の自動リトライや処理遅延時のタイムアウトが行えるようになりました。
さらに、SFNのステートマシンはCFnのテンプレートで記述することができます。
これによって、EMRクラスタの設定値や、ETLパイプラインで呼び出すLambdaの設定値をステートマシンで記述し、それをCFnのテンプレートで管理することができ、インフラコード化による一元管理を押し進めることができます。
EMRやLambdaなどのアプリケーション実行環境、IAMロールやセキュリティグループなどの周辺リソース、リトライ/タイムアウト/エラー通知など処理の流れを設定するステートマシンなど、ETLパイプラインに必要なリソース一式をテンプレートとして用意しておくと、別のETLパイプラインを追加する際に非常に便利です。
CFnでステートマシンを記述する例については、以下のチュートリアルが参考になります。
AWS CloudFormation を使用してStep Functions 用 Lambda ステートマシンを作成する
今回、ETLパイプラインごとにCFnのテンプレートを分け、大きなデータの処理はEMR(Scala/Spark)、比較的小さなデータの処理はLambda(Python/Pandas)で行い、SFNのワークフローとしてパイプラインごとにETL処理をまとめています。
まず、Lambda関数タスクで、他のETLタスクの処理時に必要な情報で取得し、ETLタスク別でJSONのKEYを分けて出力し、各タスクではInputPathを使って必要なパラメータだけを取得し、引数を取得して処理を行うようにしています。
Path の動作については、下記のドキュメントにまとめられています。
AWS Step Functions 開発者ガイド: Step Functions の入出力処理
LookerによるBI構築
データサイエンスチームでは、ビジネスインテリジェンス(BI)のツールとして、Lookerを利用しています。
Lookerを使うことで、様々なメリットがあります
- ブラウザベースですぐに使えて、クライアント側でソフトウェアのインストールやBI用サーバの構築・保守運用が必要ない
- Looker側にはデータが保存されず、グラフ描画時にデータベースからデータを取得してくるため、セキュリティ面・データ管理面でメリットがある
- 独自のデータモデリング言語(LookML)を使ってデータ構造・集計・ダッシュボードを記述できる
- LookMLによってダッシュボードもgitでバージョン管理ができ、事前構築済の分析テンプレート(Looker Blocks)も活用できる
LookMLの活用
Lookerは独自のデータモデリング言語であるLookMLを提供しており、LookMLを活用することで、SQLの利用と比較して、学習コストの削減・再利用性やメンテナンス性の向上などのメリットが得られます。
LookMLについて、詳細は以下のドキュメントが詳しいです。
Looker Documentation: LookMLとは?
また、LookerではLooker Blocksとして各種データの分析に活用できる事前構築済テンプレートが公開されており、Blocksを活用してデータモデルとダッシュボードの構築を迅速に行うことができます。
AWSに関連するBlocksとしては、執筆時点(2020年8月)では、以下のリソースが公開されています。これらを活用し、Redshiftのモニタリングやコストの最適化を進めています。
- Redshift Admin by AWS
- Redshift Optimization:AWS
- AWS最適化スイート
- コスト・使用状況分析:AWS
- Security and Monitoring by AWS
SSHトンネルによる通信の保護
LookerはブラウザベースのBIツールで、Looker側でホストされているインスタンスを利用することで、Lookerアプリケーションのインストール、設定、保守運用の作業が不要になります。
Looker-Hosted Installation Steps
ただし、Looker側のインスタンスとデータベース間の通信の保護は、ユーザー側で適切な設定を行う必要があります。そのための方法として下記のドキュメントでは、データベースへの接続元のIPアドレスの制限やSSLによる通信の暗号化、そして更に強固な方法としてSSHトンネルによる通信の暗号化が挙げられています。
Enabling Secure Database Access – Looker Documentation
今回のデータ基盤では、Redshiftクラスタをプライベートサブネット内で構築し、外部から直接アクセスできないようにしています。
このようなケースでは、Looker側のインスタンスからユーザー側の踏み台サーバへのSSHトンネルを確立することで、外部に公開されていないデータベースへLookerから安全に接続・通信することができます。
Using an SSH Tunnel – Looker Documentation
AWSコストの削減
C-Chorusの活用
最後に、データ基盤のAWSコストに関して、サービスをご紹介します。
弊社のAWSリセールサービス(C-Chorus)を活用することで、AWSのコストを即座に削減することが可能です。
全リージョン・全サービスが一律5%割引になる「5%割引プラン」や、EC2やCloudFrontの割引に特化した「個別割引プラン」など、用途に応じて割引プランを選択することができます。
AWSリセールサービス(請求代行・活用支援)| C-Chorus
AWSコストの削減を進める際には、ぜひ上記のサービスもご検討ください。
まとめ
この記事では、社内で構築・運用しているデータ分析基盤をご紹介しました。
DWH、ETL、BIの各コンポーネントを見ていきながら、再利用性を高める工夫について紹介しました。
内容のまとめとしては以下の通りです。
- AWS Well-Architected Frameworkを活用することで、AWS上での設計・運用のベストプラクティスを確認できる
- AWSブログのCloudFormationのテンプレートを活用することで、ベストプラクティスに沿ったRedshift環境を簡単に構築できる
- 上記のテンプレートを拡張していく際は、ネストされたスタックやSecrets Managerによる認証情報の一元管理によって、運用面・セキュリティ面を強化していくことができる
- Step Functionsを活用することで、EMRジョブ失敗時の自動リトライや処理遅延時のタイムアウトを設定でき、ETLパイプライン全体をCloudFormationテンプレートで記述・再利用できる。
- Lookerを活用することで、BIサーバの保守運用が不要になり、LookMLによる学習コストやメンテナンスコストの削減、Looker Blocksによる事前設定済テンプレートの活用が可能になる
- Lookerインスタンスからプライベートサブネット内のデータベースへ接続する際は、踏み台サーバへのSSHトンネルを確立することで、安全に接続・通信することができる
この記事の内容が参考になりましたら幸いです。
テックブログ新着情報のほか、AWSやGoogle Cloudに関するお役立ち情報を配信中!
Follow @twitter
2017年4月、NHNテコラスに新卒入社。データサイエンスチームに所属し、AWSを活用したデータ分析サービスの設計開発を担当。
Recommends
こちらもおすすめ
-

AWS無料セミナー開催レポート | 満足度93%!AWSのはじめ方セミナー
2019.3.29





Special Topics
注目記事はこちら

データ分析入門
これから始めるBigQuery基礎知識
2024.02.28

AWSの料金が 8 %割引になる!
『AWSの請求代行リセールサービス』
2023.01.15