Amazon Personalize Web-APIで情報推薦サービスを実現する(3)

【連載】Amazon Personalize Web-APIで情報推薦サービスを実現する
(1)シグネチャバージョン4を使うメソッドの定義と必要なデータ
(2)データセットグループとスキーマ
▶︎(3)データセットとイベントトラッカー
(4)データをリアルタイム登録する方法とレシピ
(5)機械学習を実行するソリューション、機械学習モデルをデプロイするキャンペーン
(6)レコメンド結果と利用料金
今までの記事では、次のような内容を説明してきました。
- Amazon Personalize Web-APIで情報推薦サービスを実現する(1)
シグネチャバージョン4を使うメソッドの定義と、Amazon Personalizeを利用する上で必要なデータについて - Amazon Personalize Web-APIで情報推薦サービスを実現する(2)
Amazon Personalizeにデータを登録するために必要な、データセットグループとスキーマについて
今回は、スキーマに基づいてデータセットグループにデータセットを作成する作業から説明しようと思います。
データセットを操作する
データセットは具体的にデータを入れる箱のようなもので、スキーマに紐付きどんな項目のデータを登録するかを定めます。
公式ドキュメントに説明があるとおり、以下の3種類のデータセットがサポートされています。
- Users — このデータセットではユーザーに関するメタデータを提供します。これには、年齢、性別、ロイヤリティメンバーシップなど、パーソナライゼーションシステムで重要なシグナルとなる情報が含まれます。
- Items — このデータセットでは、アイテムに関するメタデータを提供します。これには、価格、SKU タイプ、可用性などの情報が含まれます。
- Interactions — このデータセットでは、ユーザーとアイテム間のインタラクション、インタラクションのタイプ、タイムスタンプを指定します。各レコードは、クリック、視聴、カートへの追加などのイベントタイプに対応します。
今回は、前の記事で既にInteractionsのスキーマを用意したので、データセットもInteractionsという種類を用いることにします。
{
"type": "record",
"name": "Interactions",
"namespace": "com.amazonaws.personalize.schema",
(以下略)
データセットの一覧を得るメソッドは、次のように定義できます(データセットグループやスキーマの一覧を得る方法とほぼ同じで、また、今後説明する他のデータについても同様です)。
def ListDatasets(datasetGroupArn, maxResults = 100)
endpoint = "https://personalize.#{REGION}.amazonaws.com/"
post_data = { 'datasetGroupArn' => datasetGroupArn,
'maxResults' => maxResults,
}.to_json
call(endpoint, 'AmazonPersonalize.ListDatasets', post_data)
end
APIの引数であるデータセットグループARN(Amazon Resource Name)は必須ではなく、省略すると全てのデータセットグループの中の全てのデータセットの一覧を得ることができるのですが、ここでは指定することにします。前回の記事の中でデータセットグループARNが得られましたので、それを引数として渡して実行してみます。
ListDatasets('arn:aws:personalize:ap-northeast-1:123456:dataset-group/sample-dataset-group')
{
"datasets": [
]
}
まだカラですので、作成します。データセットを作成するメソッドは、次のように定義できます。
def CreateDataset(datasetGroupArn, datasetType, name, schemaArn)
endpoint = "https://personalize.#{REGION}.amazonaws.com/"
post_data = {'datasetGroupArn' => datasetGroupArn,
'datasetType' => datasetType,
'name' => name,
'schemaArn' => schemaArn
}.to_json
call(endpoint, 'AmazonPersonalize.CreateDataset', post_data)
end
datasetGroupArnとschemaArnは前回の記事で得られたものを使い、datasetTypeは前述のようにスキーマに合わせてInteractionsを指定し、データセットの名前は「sample-dataset」にします。
CreateDataset('arn:aws:personalize:ap-northeast-1:123456:dataset-group/sample-dataset-group',
'Interactions', 'sample-dataset',
'arn:aws:personalize:ap-northeast-1:123456:schema/sample-schema')
{
"datasetArn": "arn:aws:personalize:ap-northeast-1:123456:dataset/sample-dataset-group/INTERACTIONS"
}
他のデータと同様、ARNから詳細を確認するメソッドは次のように定義できます。
def DescribeDataset(datasetArn)
endpoint = "https://personalize.#{REGION}.amazonaws.com/"
post_data = {'datasetArn' => datasetArn,
}.to_json
call(endpoint, 'AmazonPersonalize.DescribeDataset', post_data)
end
上で得られたデータセットARNを引数として渡して実行してみると、詳細情報が得られます。
DescribeDataset('arn:aws:personalize:ap-northeast-1:123456:dataset/sample-dataset-group/INTERACTIONS')
{
"dataset": {
"creationDateTime": 1559615684.515,
"datasetArn": "arn:aws:personalize:ap-northeast-1:123456:dataset/sample-dataset-group/INTERACTIONS",
"datasetGroupArn": "arn:aws:personalize:ap-northeast-1:123456:dataset-group/sample-dataset-group",
"datasetType": "INTERACTIONS",
"lastUpdatedDateTime": 1559615684.515,
"name": "sample-dataset",
"schemaArn": "arn:aws:personalize:ap-northeast-1:123456:schema/sample-schema",
"status": "ACTIVE"
}
}
statusにACTIVEとありますが、CreateDatasetのドキュメントにある通り、データセットグループと同様に次のように変化します。
- CREATE PENDING > CREATE IN_PROGRESS > ACTIVE -or- CREATE FAILED
執筆者の環境では数秒かかりました。データセットのstatusがACTIVEになる前にデータ登録などの操作を行うとエラーになりますので、プログラムを作成する場合はデータセットグループの時と同様に、statusがACTIVEになるまで待つ必要があります。
例えば次のようになるでしょう。
datasetArn = 'arn:aws:personalize:ap-northeast-1:123456:dataset/sample-dataset-group/INTERACTIONS' ret = DescribeDataset(datasetArn) sampleDataset = JSON.parse(ret.body)['dataset'] while sampleDataset['status'] =~ /(CREATE PENDING)|(CREATE IN_PROGRESS)/ sleep(3) ret = DescribeDataset(datasetArn) sampleDataset = JSON.parse(ret.body)['dataset'] end
イベントトラッカーを操作する
前回の記事でスキーマを作成した際、次のような説明をしました。
EVENT_TYPEは、何かユーザーが取った行動を表します。ECサイトなら閲覧、検索、購入などがあるでしょうし、SNSならお店や商品につけた評価やいわゆる「いいね」を押したかどうかなどもあり得るかもしれません。
Amazon Personalizeでは、情報推薦のために利用するデータ(ユーザーの行動や、世の中で起こった出来事など何でも)のことをイベントと呼び、イベントを記録するためにイベントトラッカーという概念を使います。
イベントトラッカーはデータセットグループに対し1つだけ作成することができますが、作成するまでは存在しません。
他のデータと同様、イベントトラッカーの一覧を得るメソッドとイベントトラッカーを作成するメソッドは、次のように定義できます。
def ListEventTrackers(datasetGroupArn, maxResults = 100)
endpoint = "https://personalize.#{REGION}.amazonaws.com/"
post_data = {'datasetGroupArn' => datasetGroupArn,
'maxResults' => maxResults,
}.to_json
call(endpoint, 'AmazonPersonalize.ListEventTrackers', post_data)
end
def CreateEventTracker(datasetGroupArn, name)
endpoint = "https://personalize.#{REGION}.amazonaws.com/"
post_data = {'datasetGroupArn' => datasetGroupArn,
'name' => name,
}.to_json
call(endpoint, 'AmazonPersonalize.CreateEventTracker', post_data)
end
一覧を確認したあと、イベントトラッカーを作成すると、次のような出力が得られるでしょう。イベントトラッカーには、「sample-event-tracker」という名前を付けることにします。
ListEventTracers('arn:aws:personalize:ap-northeast-1:123456:dataset-group/sample-dataset-group')
{
"eventTrackers": [
]
}
CreateEventTracker('arn:aws:personalize:ap-northeast-1:123456:dataset-group/sample-dataset-group',
'sample-event-tracker')
{
"eventTrackerArn": "arn:aws:personalize:ap-northeast-1:123456:event-tracker/a0bc5257",
"trackingId": "3febd1f4-daa1-42da-8233-3ca785bf9c2b"
}
他のデータと同様にイベントトラッカーのARNを得ることができ、詳細を確認するメソッドを定義し実行することでイベントトラッカーの情報を得ることができます。
def DescribeEventTracker(eventTrackerArn)
endpoint = "https://personalize.#{REGION}.amazonaws.com/"
post_data = {'eventTrackerArn' => eventTrackerArn,
}.to_json
call(endpoint, 'AmazonPersonalize.DescribeEventTracker', post_data)
end
DescribeEventTracker('arn:aws:personalize:ap-northeast-1:123456:event-tracker/a0bc5257')
{
"eventTracker": {
"accountId": "123456",
"creationDateTime": 1559620004.453,
"datasetGroupArn": "arn:aws:personalize:ap-northeast-1:123456:dataset-group/sample-dataset-group",
"eventTrackerArn": "arn:aws:personalize:ap-northeast-1:123456:event-tracker/a0bc5257",
"lastUpdatedDateTime": 1559620010.566,
"name": "sample-event-tracker",
"status": "ACTIVE",
"trackingId": "3febd1f4-daa1-42da-8233-3ca785bf9c2b"
}
}
statusが存在することから、イベントトラッカーの作成時にも、statusがACTIVEになるまで待つ必要があることが分かります。
データセットを確認する
イベントトラッカーを作成したところで、今回の記事の最初に戻り、データセットグループの中のデータセットの一覧を表示してみます。
データセットグループARNを引数に、定義したListDatasetsを呼び出すと、JSON配列の形で2つのデータセットが確認できます。
ListDatasets('arn:aws:personalize:ap-northeast-1:123456:dataset-group/sample-dataset-group')
{
"datasets": [
{
"creationDateTime": 1559615684.515,
"datasetArn": "arn:aws:personalize:ap-northeast-1:123456:dataset/sample-dataset-group/INTERACTIONS",
"datasetType": "INTERACTIONS",
"lastUpdatedDateTime": 1559615684.515,
"name": "sample-dataset",
"status": "ACTIVE"
},
{
"creationDateTime": 1559620010.424,
"datasetArn": "arn:aws:personalize:ap-northeast-1:123456:dataset/sample-dataset-group/EVENT_INTERACTIONS",
"datasetType": "EVENT_INTERACTIONS",
"lastUpdatedDateTime": 1559620010.424,
"name": "sample-dataset-group/EVENT_INTERACTIONS",
"status": "ACTIVE"
}
]
}
datasetTypeがINTERACTIONSとなっているデータセットが、CreateDatasetで作成したデータセットです。もう一つ、datasetTypeがEVENT_INTERACTIONSというイベントトラッカー用のデータセットは、イベントトラッカー作成時に自動作成されたものです。データセットが自動作成されるならわざわざ作る必要が無いのではないかと思うかもしれませんが、データセットInteractionsを作成しないでイベントトラッカーだけ作成しようとすると、次のようなエラーが発生します。
{
"__type": "ResourceNotFoundException",
"message": "Missing Interaction dataset with datasetgroup: [arn:aws:personalize:ap-northeast-1:123456:dataset-group/sample-dataset-group]"
}
ここは仕様としてはよく分からないところで、しかもEVENT_INTERACTIONSデータセットが自動作成されたあとは、CreateDatasetで作成したINTERACTIONSデータセットは削除することもできます。というかこの記事では削除します。
def DeleteDataset(arn)
endpoint = "https://personalize.#{REGION}.amazonaws.com/"
post_data = {'datasetArn' => arn }.to_json
call(endpoint, 'AmazonPersonalize.DeleteDataset', post_data)
end
DeleteDataset('arn:aws:personalize:ap-northeast-1:123456:dataset/sample-dataset-group/INTERACTIONS')
理由は、この記事ではINTERACTIONSデータセットは使用しないので、データが空です。空のデータセットが置いてあると、次回に説明する機械学習を実行する時に次のようなエラーが出るからです。
The following dataset does not have any successfully completed dataset import jobs: [arn:aws:personalize:ap-northeast-1:123456:dataset/sample-dataset-group/INTERACTIONS]
なお、英語版の公式ドキュメントのEVENT_INTERACTIONSデータセットの説明箇所及びそれに相当する日本語版の公式ドキュメントには、次のような記載があります。
The event-interactions dataset stores the event data from the PutEvents call. The contents of the dataset are not available to the user.
データセットの内容は、ユーザーには使用できません。
記録したデータの保存場所を確認したり、記録したデータを再読み取りするなどの操作はサポートされていません。なかなかAWSらしい仕様だと思います。
次の予定
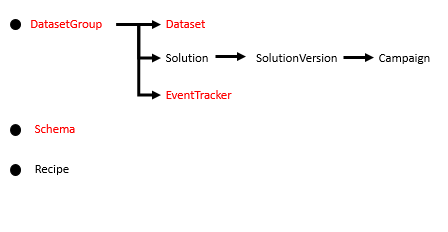
ここまでで、図の赤字になっている部分の準備ができました。
次の記事ではデータの登録をして、いよいよAmazon Personalizeで使用する機械学習にも触れようと思います。


大学で民俗学や宗教についてのフィールドワークを楽しんでいたのですが,うっかり新設された結び目理論と幾何学を勉強する研究室に移ってしまい,さらに大学院では一般相対性理論を研究するという迷走した人生を歩んでいます.プログラミングが苦手で勉強中です.


Recommends
こちらもおすすめ
-

Rで実践!欠損データ分析入門【2】
2017.12.20
-

データサイエンス関連参加イベントまとめ(2017年)【後半】
2017.12.2



Special Topics
注目記事はこちら

データ分析入門
これから始めるBigQuery基礎知識
2024.02.28

AWSの料金が 10 %割引になる!
『AWSの請求代行リセールサービス』
2024.07.16